empiricalblm
贝叶斯线性回归模型与样本前或后验分布
描述
的贝叶斯线性回归模型对象empiricalblm包含样本的先验分布β和σ2,MATLAB®使用前或后验分布的特点。
数据可能是 在哪里ϕ(yt;xtβ,σ2)是高斯概率密度评估yt与的意思xtβ和方差σ2。因为形式的先验分布函数未知,由此产生的后验分布不易于分析。因此,估计或从后验分布,模拟MATLAB实现采样重要性重采样。
您可以创建一个贝叶斯线性回归模型与实证之前直接使用bayeslm或empiricalblm。然而,对于实证先知先觉,估计后验分布相似后之前要求。因此,实证模型更适合更新后验分布估计使用蒙特卡罗抽样之前(例如,semiconjugate和自定义模型)得到新的数据。
创建
要么估计函数返回一个empiricalblm对象或您直接创建一个通过使用empiricalblm。
返回
empiricalblm对象使用估计:对于semiconjugate,经验、自定义和变量选择模型之前,估计使用蒙特卡罗抽样估计后验分布。具体地说,估计描述后验分布的大量从分布。估计商店的吸引BetaDraws和Sigma2Draws返回的贝叶斯线性回归模型对象的属性。因此,当你估计semiconjugateblm,empiricalblm,customblm,lassoblm,mixconjugateblm,mixconjugateblm模型对象,估计返回一个empiricalblm对象。创建
empiricalblm对象直接:如果你想使用新数据更新估计后验分布,绘制的后验分布β和σ2,您可以创建一个使用经验模型empiricalblm。
语法
描述
PriorMdl= empiricalblm (NumPredictors”,BetaDraws“BetaDraws,”Sigma2Draws”,Sigma2Draws)PriorMdl)组成的NumPredictors预测和拦截,并设置NumPredictors财产。随机样本的先验分布β和σ2,BetaDraws和Sigma2Draws分别是先验分布的特征。PriorMdl是一个模板,它定义了维度的先验分布和β。
属性
对象的功能
例子
创建之前经验模型
考虑的多元线性回归模型预测美国实际国民生产总值(GNPR)使用工业生产指数的线性组合新闻学会)、就业总人数(E),实际工资(或者说是)。
对所有 时间点, 是一系列的独立和0的均值和方差高斯干扰吗 。
假设先验分布:
。 意味着是一个4-by-1向量, 是一个按比例缩小的4×4正定协方差矩阵。
。 和 分别是形状和规模的逆伽马分布。
这些假设和数据可能意味着normal-inverse-gamma semiconjugate模型。即共轭条件后验来之前对数据的可能性,但边际后分析棘手。
创建一个normal-inverse-gamma semiconjugate之前线性回归模型参数。指定数量的预测p。
p = 3;PriorMdl = bayeslm (p,“ModelType”,“semiconjugate”)
PriorMdl = semiconjugateblm属性:NumPredictors: 3拦截:1 VarNames: {4 x1细胞}μ:x1双[4]V: [4 x4双]A: 3 B: 1 |意味着性病CI95积极分配- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -拦截| 0 100 [-195.996,195.996]0.500 N(0.00、100.00 ^ 2)β(1)| 0 100 [-195.996,195.996]0.500 N(0.00、100.00 ^ 2)β(2)| 0 100 [-195.996,195.996]0.500 N(0.00、100.00 ^ 2)β(3)| 0 100 [-195.996,195.996]0.500 N (0.00、100.00 ^ 2) Sigma2 | 0.5000 - 0.5000[0.138, 1.616] 1.000搞笑(3.00,1)
Mdl是一个semiconjugateblm贝叶斯线性回归模型对象代表回归系数的先验分布和扰动方差。在命令窗口中,bayeslm显示一个先验分布的摘要。
加载Nelson-Plosser数据集。为响应和预测系列创建变量。
负载Data_NelsonPlosserVarNames = {“他们”;“E”;“福”};X = DataTable {: VarNames};y = DataTable {:,“GNPR”};
估计边际的后验分布 和 。
rng (1);%的再现性PosteriorMdl =估计(PriorMdl, X, y);
方法:吉布斯抽样数量与10000年吸引的观察:62年的预测数量:4 |意味着性病CI95积极分配- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -拦截| -23.9922 - 9.0520[-41.734,-6.198]0.005经验β(1)| 4.3929 - 0.1458[4.101,4.678]1.000经验β(2)| 0.0011 - 0.0003[0.000,0.002]0.999经验β(3)| 2.4711 - 0.3576[1.762,3.178]1.000经验Sigma2 | 46.7474 - 8.4550[33.099, 66.126] 1.000经验
PosteriorMdl是一个empiricalblm模型对象存储的后验分布
和
考虑到数据。估计显示一个总结边缘后验分布的命令窗口。行总结对应回归系数和扰动变化,和列后验分布的特点。特点包括:
CI95,其中包含参数的贝叶斯equitailed 95%可信区间。例如,后验概率的回归系数或者说是0.95在[1.762,3.178]。积极的,其中包含参数的后验概率大于0。例如,截距大于0的概率是0.005。
在这种情况下,边际分析后是棘手的。因此,估计用吉布斯抽样从后和估计后特征。
为新数据更新边缘后验分布
考虑线性回归模型创建之前经验模型。
创建一个normal-inverse-gamma semiconjugate之前线性回归模型参数。指定数量的预测p和回归系数的名称。
p = 3;PriorMdl = bayeslm (p,“ModelType”,“semiconjugate”,“VarNames”,(“他们”“E”“福”]);
加载Nelson-Plosser数据集。分区数据保留过去的五期的系列。
负载Data_NelsonPlosserX0 = DataTable{1:结束(- 5),PriorMdl.VarNames(2:结束)};y0 = DataTable{1:结束(- 5),“GNPR”};X1 = DataTable{(结束- 4):最终,PriorMdl.VarNames(2:结束)};日元= DataTable {(end - 4):结束,“GNPR”};
估计边际的后验分布 和 。
rng (1);%的再现性PosteriorMdl0 =估计(PriorMdl, X0, y0);
方法:吉布斯抽样数量与10000年吸引的观察:57的预测数量:4 |意味着性病CI95积极分配- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -拦截| -34.3887 - 10.5218[-55.350,-13.615]0.001经验IPI | 3.9076 - 0.2786[3.356, 4.459] 1.000经验E | 0.0011 - 0.0003[0.000, 0.002] 0.999经验或者说是| 3.2146 - 0.4967[2.228,4.196]1.000经验Sigma2 | 45.3098 - 8.5597[31.620, 64.972] 1.000经验
PosteriorMdl0是一个empiricalblm模型对象存储Gibbs-sampling吸引的后验分布。
基于过去的5期更新后验分布的数据通过这些观察和后验分布估计。
PosteriorMdl1 =估计(PosteriorMdl0 (X1, y1);
方法:重要性抽样/重采样与10000年吸引了数量的观察:5预测数量:4 |意味着性病CI95积极分配- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -拦截| -24.3152 - 9.3408[-41.163,-5.301]0.008经验IPI | 4.3893 - 0.1440[4.107, 4.658] 1.000经验E | 0.0011 - 0.0004[0.000, 0.002] 0.998经验或者说是| 2.4763 - 0.3694[1.630,3.170]1.000经验Sigma2 | 46.5211 - 8.2913[33.646, 65.402] 1.000经验
更新后验分布基于吸引,估计使用采样重要性重采样。
使用蒙特卡罗模拟法估计后验概率
考虑线性回归模型估计边缘后验分布。
创建一个模型的回归系数和扰动变化之前,然后估计边缘后验分布。
p = 3;PriorMdl = bayeslm (p,“ModelType”,“semiconjugate”,“VarNames”,(“他们”“E”“福”]);负载Data_NelsonPlosserX = DataTable {: PriorMdl.VarNames(2:结束)};y = DataTable {:,“GNPR”};rng (1);%的再现性PosteriorMdl =估计(PriorMdl, X, y);
方法:吉布斯抽样数量与10000年吸引的观察:62年的预测数量:4 |意味着性病CI95积极分配- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -拦截| -23.9922 - 9.0520[-41.734,-6.198]0.005经验IPI | 4.3929 - 0.1458[4.101, 4.678] 1.000经验E | 0.0011 - 0.0003[0.000, 0.002] 0.999经验或者说是| 2.4711 - 0.3576[1.762,3.178]1.000经验Sigma2 | 46.7474 - 8.4550[33.099, 66.126] 1.000经验
估计后验分布汇总统计数据 通过使用了从后验分布存储模型。
estBeta =意味着(PosteriorMdl.BetaDraws, 2);EstBetaCov = x (PosteriorMdl.BetaDraws ');
假设如果实际工资系数低于2.5,则颁布了一项政策。尽管的后验分布或者说是是已知的,所以你可以直接计算概率,您可以使用蒙特卡罗模拟估计的概率。
画1 e6样本的边缘后验分布
。
NumDraws = 1 e6;rng (1);BetaSim =模拟(PosteriorMdl,“NumDraws”,NumDraws);
BetaSim是一个4×-1 e6矩阵包含了。行对应的回归系数和列连续的吸引。
隔离了相应的实际工资系数,然后确定哪些吸引小于2.5。
isWR = PosteriorMdl。VarNames = =“福”;wrSim = BetaSim (isWR:);isWRLT2p5 = wrSim < 2.5;
找到的回归系数的边缘后验概率或者说是低于2.5通过计算的比例小于2.5的吸引。
probWRLT2p5 =意味着(isWRLT2p5)
probWRLT2p5 = 0.5283
实际工资的后验概率系数小于2.50.53。
版权2018年MathWorks公司。
使用后预测分布预测的反应
考虑线性回归模型估计边缘后验分布。
创建一个模型的回归系数和扰动变化之前,然后估计边缘后验分布。坚持过去10期的数据估计,这样你可以使用它们来预测实际国民生产总值。关掉估计显示。
p = 3;PriorMdl = bayeslm (p,“ModelType”,“semiconjugate”,“VarNames”,(“他们”“E”“福”]);负载Data_NelsonPlosserfhs = 10;%预测地平线大小X = DataTable{1:(结束- fhs), PriorMdl.VarNames(2:结束)};y = DataTable{1:(结束- fhs),“GNPR”};XF = DataTable{(结束- fhs + 1):最终,PriorMdl.VarNames(2:结束)};%未来的预测数据yFT = DataTable{(结束- fhs + 1):结束,“GNPR”};%未来真实的反应rng (1);%的再现性PosteriorMdl =估计(PriorMdl, X, y,“显示”、假);
使用后预测分布和预测反应使用未来的预测数据XF。情节的真实值响应和预测的值。
yF =预测(PosteriorMdl XF);图;情节(日期、DataTable.GNPR);持有在情节(日期((结束- fhs + 1):结束),yF h = gca;惠普=补丁([日期(结束- fhs + 1)日期(结束)日期(结束)日期(结束- fhs + 1)),…h.YLim ([1, 1、2、2]), [0.8 0.8 0.8]);uistack(惠普、“底”);传奇(“预测地平线”,“真正的GNPR”,“预测GNPR”,“位置”,“西北”)标题(“真正的国民生产总值:1909 - 1970”);ylabel (“rGNP”);包含(“年”);持有从
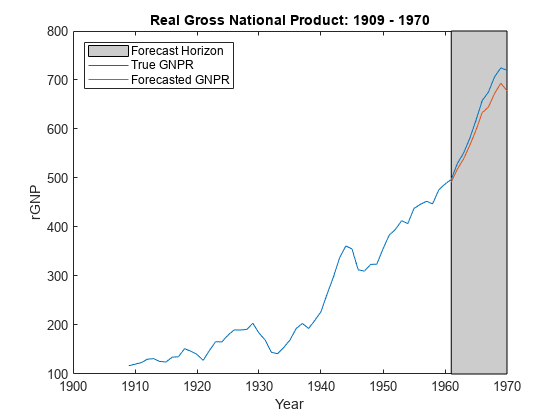
yF是一个10-by-1向量的值相对应的实际国民生产总值未来预测数据。
估计预测均方误差(RMSE)。
frmse =√意味着(yF - yFT) ^ 2))
frmse = 25.1938
预测均方根误差是一个相对程度的预测精度。具体地说,您估计几个使用不同的假设模型。最低的模型预测的RMSE是表现最好的模型相比较。
更多关于
算法
选择
的bayeslm函数可以创建任何支持先前对贝叶斯线性回归的模型对万博1manbetx象。
版本历史
介绍了R2017a