模拟
模拟回归系数和扰动贝叶斯线性回归模型的方差
语法
描述
(从潜在的政权如果分布也返回了BetaSim,sigma2Sim,RegimeSim)=模拟(___)Mdl是一个随机搜索贝叶斯线性回归模型变量选择(科学),也就是说,如果Mdl是一个mixconjugateblm或mixsemiconjugateblm模型对象。
例子
从先验和后验分布模拟参数值
考虑的多元线性回归模型预测美国实际国民生产总值(GNPR)通过使用工业生产指数的线性组合新闻学会)、就业总人数(E),实际工资(或者说是)。
对所有 , 是一系列的独立和0的均值和方差高斯干扰吗 。
假设这些先验分布:
。 意味着是一个4-by-1向量, 是一个按比例缩小的4×4正定协方差矩阵。
。 和 分别是形状和规模的逆伽马分布。
这些假设和数据可能意味着normal-inverse-gamma共轭模型。
加载Nelson-Plosser数据集。为响应和预测系列创建变量。
负载Data_NelsonPlosservarNames = {“他们”“E”“福”};X = DataTable {: varNames};y = DataTable {:,“GNPR”};
创建一个normal-inverse-gamma共轭先验模型的线性回归参数。指定数量的预测p和变量名。
p = 3;PriorMdl = bayeslm (p,“ModelType”,“共轭”,“VarNames”,varNames);
PriorMdl是一个conjugateblm贝叶斯线性回归模型对象代表回归系数的先验分布和扰动方差。
模拟一组回归系数和一个值的扰动先验分布的方差。
rng (1);%的再现性[betaSimPrior, sigma2SimPrior] =模拟(PriorMdl)
betaSimPrior =4×1-33.5917 -49.1445 -37.4492 -25.3632
sigma2SimPrior = 0.1962
betaSimPrior是随机画4-by-1向量回归系数对应的名字PriorMdl.VarNames。的sigma2SimPrior输出是随机画标量扰动方差。
估计后验分布。
PosteriorMdl =估计(PriorMdl, X, y);
方法:分析后分布的观测数量:62的预测数量:4日志边缘相似性:-259.348 |意味着性病CI95积极分配- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -拦截| -24.2494 - 8.7821[-41.514,-6.985]0.003吨(-24.25、8.65 ^ 2,68)IPI | 4.3913 - 0.1414 [4.113, 4.669] 1.000 t E(4.39、0.14 ^ 2, 68) | 0.0011 - 0.0003[0.000, 0.002] 1.000吨(0.00、0.00 ^ 2,68)代为| 2.4683 - 0.3490[1.782,3.154]1.000吨(2.47、0.34 ^ 2,68)Sigma2 | 44.1347 - 7.8020[31.427, 61.855] 1.000搞笑(34.00,0.00069)
PosteriorMdl是一个conjugateblm贝叶斯线性回归模型对象代表回归系数和扰动的后验分布方差。
模拟一组回归系数和一个值的扰动后验分布的方差。
[betaSimPost, sigma2SimPost] =模拟(PosteriorMdl)
betaSimPost =4×1-25.9351 4.4379 0.0012 2.4072
sigma2SimPost = 41.9575
betaSimPost和sigma2SimPost有相同的尺寸吗betaSimPrior和sigma2SimPrior分别,但来自后。
为后验估计实现吉布斯采样器
考虑的回归模型从先验和后验分布模拟参数值。
加载数据和创建一个共轭先验模型的回归系数和扰动方差。然后,估计后验分布并返回评估汇总表。
负载Data_NelsonPlosservarNames = {“他们”“E”“福”};X = DataTable {: varNames};y = DataTable {:,“GNPR”};p = 3;PriorMdl = bayeslm (p,“ModelType”,“共轭”,“VarNames”,varNames);[PosteriorMdl,总结]=估计(PriorMdl, X, y);
方法:分析后分布的观测数量:62的预测数量:4日志边缘相似性:-259.348 |意味着性病CI95积极分配- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -拦截| -24.2494 - 8.7821[-41.514,-6.985]0.003吨(-24.25、8.65 ^ 2,68)IPI | 4.3913 - 0.1414 [4.113, 4.669] 1.000 t E(4.39、0.14 ^ 2, 68) | 0.0011 - 0.0003[0.000, 0.002] 1.000吨(0.00、0.00 ^ 2,68)代为| 2.4683 - 0.3490[1.782,3.154]1.000吨(2.47、0.34 ^ 2,68)Sigma2 | 44.1347 - 7.8020[31.427, 61.855] 1.000搞笑(34.00,0.00069)
总结包含数据的表吗估计显示在命令行。
尽管的边际和条件后验分布 和 易于分析,这个例子着重于如何实现吉布斯采样器复制已知的结果。
再次评估模型,但用吉布斯采样器。交替采样条件后验分布的参数。预先配置的示例和创建变量10000倍。开始画的条件后的取样器 鉴于 。
m = 1 e4;BetaDraws = 0 (p + 1, m);sigma2Draws = 0 (m + 1);sigma2Draws (1) = 2;rng (1);%的再现性为j = 1: m BetaDraws (:, j) =模拟(PriorMdl, X, y,“Sigma2”sigma2Draws (j));[~,sigma2Draws (j + 1) =模拟(PriorMdl, X, y,“β”BetaDraws (:, j));结束sigma2Draws = sigma2Draws(2:结束);%将初始值从获得样本
图像跟踪情节的参数。
图;为j = 1: (p + 1);次要情节(2,2,j);情节(BetaDraws (j,:)) ylabel (“获得画”)包含(“模拟指数”)标题(sprintf (“跟踪情节——% s”,PriorMdl.VarNames {j}));结束

图;情节(sigma2Draws) ylabel (“获得画”)包含(“模拟指数”)标题(“跟踪情节——Sigma2”)

马尔可夫链蒙特卡罗(密度)样本似乎收敛,拌匀。
应用一个老化1000平,然后计算获得样本的均值和标准差。比较它们的估计估计。
英国石油(bp) = 1000;postBetaMean =意味着(BetaDraws (:, (bp + 1):结束),2);postSigma2Mean =意味着(sigma2Draws (:, (bp + 1):结束));postBetaStd =性病(BetaDraws (:, (bp + 1):结束),[],2);postSigma2Std =性病(sigma2Draws ((bp + 1):结束);[摘要:1:2),表([postBetaMean;postSigma2Mean),…[postBetaStd;postSigma2Std),“VariableNames”,{“GibbsMean”,“GibbsStd”}))
ans =5×4表意思是性病GibbsMean GibbsStd _____ _____ _____ __________拦截IPI 4.3913 0.1414 4.3917 8.748 -24.249 8.7821 -24.293 0.0011202 0.00032931 0.0011229 0.00032875 0.13941 E WR Sigma2 44.135 7.802 44.011 0.34364 2.4683 0.34895 2.4654 7.7816
估计很近。密度变化的差异。
模拟政权从科学预测的选择
考虑的回归模型从先验和后验分布模拟参数值。
假设这些先验分布 = 0,…,3:
,在那里 和 是独立的,标准正态随机变量。因此,系数高斯混合分布。假定所有系数是条件独立的,先天的,但它们依赖于扰动方差。
。 和 分别是形状和规模的逆伽马分布。
,它代表了随机variable-inclusion政权变量离散均匀分布。
创建一个模型执行科学之前。假设
和
是依赖(共轭混合模型)。指定数量的预测p和回归系数的名称。
p = 3;PriorMdl = mixconjugateblm (p,“VarNames”,(“他们”“E”“福”]);
加载Nelson-Plosser数据集。为响应和预测系列创建变量。
负载Data_NelsonPlosserX = DataTable {: PriorMdl.VarNames(2:结束)};y = DataTable {:,“GNPR”};
计算可能的政权的数量,数量的组合,包括和排除变量在模型中。
cardRegime = 2 ^ (PriorMdl。我ntercept + PriorMdl.NumPredictors)
cardRegime = 16
模拟10000政权的后验分布。
rng (1);[~,~,RegimeSim] =模拟(PriorMdl, X, y,“NumDraws”,10000);
RegimeSim是一个4 - - 1000逻辑矩阵。行对应的变量Mdl.VarNames和列对应于从后验分布。
画一个柱状图的政权了。重新编码制度,他们是可读的。具体来说,对于每一个政权,创建一个标识字符串变量在模型中,用点和独立变量。
cRegime = num2cell (RegimeSim, 1);cRegime =分类(cellfun (@ (c)加入(PriorMdl.VarNames (c),“。”),cRegime));cRegime (ismissing (cRegime)) =“NoCoefficients”;直方图(cRegime);标题(“变量纳入模型”)ylabel (“频率”);

计算变量包含的边缘后验概率。
表(意思是(RegimeSim, 2),“RowNames”PriorMdl.VarNames,…“VariableNames”,“政权”)
ans =4×1表政权______拦截0.8829 IPI 0.4547 E 0.098或者说是0.1692
稳健回归使用吉布斯采样器
考虑一个包含一个预测的贝叶斯线性回归模型,和一个t分布式干扰与异形自由度参数方差 。
。
这些假设暗示:
是一个向量的潜在规模参数属性低精度观测回归线。 是hyperparameter控制的影响 在观察。
对于这个问题,吉布斯采样器是适合估计系数,因为你可以模拟一个贝叶斯线性回归模型的参数条件 ,然后模拟 从它的条件分布。
生成 的回应 在哪里 和 。
rng (“默认”);n = 100;x = linspace (0 2 n) ';b0 = 1;b1 = 2;σ= 0.5;e = randn (n, 1);* x + y = b0 + b1σ* e;
下面介绍偏远反应通过膨胀反应 3倍。
y (x < 0.25) = y (x < 0.25) * 3;
符合线性模型的数据。数据和拟合回归直线的阴谋。
Mdl = fitlm (x, y)
Mdl =线性回归模型:y ~ 1 + x1估计系数:估计SE tStat pValue ________ ________ _____(拦截)e15汽油x1 2.0859 2.6814 0.28433 9.4304 0.78974 0.24562 3.2153 0.0017653的观测数量:100年,错误自由度:98根均方误差:1.43平方:0.0954,调整平方:0.0862 f统计量与常数模型:10.3,p = 0.00177
图;情节(Mdl);hl =传奇;持有在;

模拟异常值出现影响拟合回归直线。
实现这个吉布斯采样器:
画出参数的后验分布 。缩小的观察 之前,创建一个扩散模型有两个回归系数,并从后画出一组参数。第一个回归系数对应于拦截,所以指定
bayeslm不包括一个拦截。计算残差。
画条件后的值 。
运行20000次迭代的吉布斯采样器和应用老化时期的5000年。指定 preallocate后吸引,并初始化 一个向量的。
m = 20000;ν= 1;燃烧= 5000;λ= 1 (n, m + 1);estBeta = 0 (2 m + 1);estSigma2 = 0 (m + 1);为j = 1: m yDef = y /√(λ(:,j));xDef = [(n, 1)的x]。/√(λ(:,j));PriorMdl = bayeslm (2“模型”,“扩散”,“拦截”、假);[estBeta: j + 1), estSigma2(1 + 1)] =模拟(PriorMdl, xDef yDef);ep = y - [(n, 1)的x] * estBeta (:, j + 1);sp =(ν+ 1)/ 2;sc = 2。/(nu + ep.^2/estSigma2(1,j + 1)); lambda(:,j + 1) = 1./gamrnd(sp,sc);结束
获得一个良好的实践是诊断取样器通过检查跟踪情节。为了简单起见,这个例子中跳过这个任务。
计算的均值后的回归系数。去除老化期了。
燃烧postEstBeta =意味着(estBeta(:,(+ 1):结束),2)
postEstBeta =2×11.3971 - 1.7051
估计的截距和斜率是高于低返回的估计fitlm。
情节的健壮的回归线回归线通过最小二乘拟合。
甘氨胆酸h =;xlim = h.XLim ';plotY = [(2, 1) xlim的]* postEstBeta;情节(xlim plotY,“线宽”2);霍奇金淋巴瘤。{4}=字符串“稳健贝叶斯;

回归线适合使用健壮的贝叶斯回归似乎是更好的选择。
使用蒙特卡罗估计最大后验概率
最大后验概率(MAP)估计是后模式,也就是说,收益最大的参数值后pdf。如果分析后是棘手的,那么您可以使用蒙特卡罗抽样估计的地图。
考虑线性回归模型从先验和后验分布模拟参数值。
加载Nelson-Plosser数据集。为响应和预测系列创建变量。
负载Data_NelsonPlosservarNames = {“他们”“E”“福”};X = DataTable {: varNames};y = DataTable {:,“GNPR”};
创建一个normal-inverse-gamma共轭先验模型的线性回归参数。指定数量的预测p和变量名。
p = 3;PriorMdl = bayeslm (p,“ModelType”,“共轭”,“VarNames”varNames)
PriorMdl = conjugateblm属性:NumPredictors: 3拦截:1 VarNames: {4 x1细胞}μ:x1双[4]V: [4 x4双]A: 3 B: 1 |意味着性病CI95积极分配- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -拦截| 0 70.7107 [-141.273,141.273]0.500 t (0.00、57.74 ^ 2,6) IPI | 0 70.7107 [-141.273, 141.273] 0.500 t (0.00、57.74 ^ 2,6) E | 0 70.7107 [-141.273, 141.273] 0.500 t (0.00、57.74 ^ 2, 6) WR | 0 70.7107 [-141.273, 141.273] 0.500 t (0.00、57.74 ^ 2, 6) Sigma2 | 0.5000 - 0.5000[0.138, 1.616] 1.000搞笑(3.00,1)
估计边际的后验分布 和 。
rng (1);%的再现性PosteriorMdl =估计(PriorMdl, X, y);
方法:分析后分布的观测数量:62的预测数量:4日志边缘相似性:-259.348 |意味着性病CI95积极分配- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -拦截| -24.2494 - 8.7821[-41.514,-6.985]0.003吨(-24.25、8.65 ^ 2,68)IPI | 4.3913 - 0.1414 [4.113, 4.669] 1.000 t E(4.39、0.14 ^ 2, 68) | 0.0011 - 0.0003[0.000, 0.002] 1.000吨(0.00、0.00 ^ 2,68)代为| 2.4683 - 0.3490[1.782,3.154]1.000吨(2.47、0.34 ^ 2,68)Sigma2 | 44.1347 - 7.8020[31.427, 61.855] 1.000搞笑(34.00,0.00069)
显示包括边缘后验分布统计信息。
提取后的均值
从模型后,提取后的协方差
从返回的评估总结总结。
estBetaMean = PosteriorMdl.Mu;摘要=总结(PosteriorMdl);EstBetaCov =总结。协方差{1:(- 1),1:结束(- 1)};
estBetaMean是一个4-by-1向量代表的边缘后意味着什么
。EstBetaCov是一个4×4矩阵的协方差矩阵代表后的
。
吸引10000后验分布的参数值。
rng (1);%的再现性[BetaSim, sigma2Sim] =模拟(PosteriorMdl,“NumDraws”1 e5);
BetaSim是一个由- 10000 4 -矩阵的随机回归系数。sigma2Sim是1 -到- 10000矢量随机扰动变化。
转置和标准化回归系数的矩阵。计算回归系数的相关矩阵。
estBetaStd =√诊断接头(EstBetaCov) ');BetaSim = BetaSim ';BetaSimStd = (BetaSim - estBetaMean”)。/ estBetaStd;BetaCorr = corrcov (EstBetaCov);BetaCorr = (BetaCorr + BetaCorr ') / 2;%执行对称
因为边缘后验分布是已知的,评估后pdf的模拟值。
betaPDF = mvtpdf (BetaSimStd BetaCorr 68);一个= 34;b = 0.00069;igPDF = @ (x,美联社、英国石油公司)1. /(伽马(美联社)。* bp。^美联社)。* x。^ (-ap-1)。* exp (-1. / (x。* bp));…%逆伽马pdfsigma2PDF = igPDF (sigma2Sim, a, b);
发现模拟值最大化各自的pdf文件,也就是说,后模式。
[~,idxMAPBeta] = max (betaPDF);[~,idxMAPSigma2] = max (sigma2PDF);betaMAP = BetaSim (idxMAPBeta:);sigma2MAP = sigma2Sim (idxMAPSigma2);
betaMAP和sigma2MAP地图估计。
因为后 是对称的单峰,后意味着和地图应该是相同的。地图的估计进行比较 后的意思。
表(betaMAP、PosteriorMdl.Mu“VariableNames”,{“地图”,“的意思是”},…“RowNames”PriorMdl.VarNames)
ans =4×2表地图的意思是替拦截-24.559 - -24.249 IPI E 4.3964 - 4.3913 2.4473 - 2.4683 0.0011389 - 0.0011202的车手
估计是相当接近。
估计后的分析模式 。比较估计的地图 。
igMode = 1 / (b * (+ 1))
igMode = 41.4079
sigma2MAP
sigma2MAP = 41.4075
这些估计也相当接近。
输入参数
输出参数
限制
模拟不能从一个画值分配不当,也就是说,一个分布的密度不整合为1。如果
Mdl是一个empiricalblm模型对象,那么你不能指定β或Sigma2。你不能模拟的条件后验分布通过使用一个经验分布。
更多关于
算法
每当
模拟必须估计后验分布(例如,当Mdl代表一个先验分布,你供应X和y)和后易于分析,模拟直接从后模拟。否则,模拟度假村蒙特卡罗模拟法估计后。更多细节,请参阅后估计和推断。如果
Mdl是一个联合后模型呢模拟模拟数据相比是不同的Mdl你之前是一个联合模型和供应吗X和y。因此,如果你设置相同的随机种子和生成随机值两个方面,那么你可能不会获得相同的值。然而,相应的经验分布基于足够数量的画实际上是等价的。这个图展示了
模拟减少了样本使用的值NumDraws,薄,燃烧。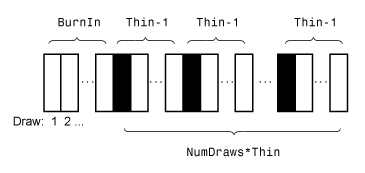
矩形表示连续分布的吸引。
模拟从样本中删除的白色矩形。剩下的NumDraws黑色的矩形组成样本。如果
Mdl是一个semiconjugateblm模型对象,然后模拟通过应用后验分布的样本吉布斯采样器。模拟使用的默认值Sigma2Start为σ2和的值β从π(β|σ2,X,y)。模拟画了一个值σ2从π(σ2|β,X,y使用前面生成的值)β。重复步骤1和2,直到收敛的函数。评估融合,画一个跟踪样本的情节。
如果您指定
BetaStart,然后模拟画了一个值σ2从π(σ2|β,X,y)开始吉布斯采样器。模拟不返回生成的价值呢σ2。如果
Mdl是一个empiricalblm模型对象和你不供应X和y,然后模拟从Mdl.BetaDraws和Mdl.Sigma2Draws。如果NumDraws小于或等于什么元素个数(Mdl.Sigma2Draws),然后模拟返回第一个NumDraws的元素Mdl.BetaDraws和Mdl.Sigma2Draws作为随机吸引相应的参数。否则,模拟随机重新取样NumDraws的元素Mdl.BetaDraws和Mdl.Sigma2Draws。如果
Mdl是一个customblm模型对象,然后模拟使用一个密度取样器从后验分布。在每个迭代中,软件连接的当前值回归系数和扰动变化成一个(Mdl.Intercept+Mdl.NumPredictors+ 1)1的向量,并将其传递到Mdl.LogPDF。扰动值的方差是这个向量的最后一个元素。HMC取样器需要日志密度及其梯度。梯度应该是一个
(NumPredictors +拦截+ 1)1的向量。如果某些参数的导数很难计算,然后,在相应位置的梯度,供应南值来代替。模拟替换南值和数字衍生品。如果
Mdl是一个lassoblm,mixconjugateblm,或mixsemiconjugateblm模型对象,你供应X和y,然后模拟通过应用后验分布的样本吉布斯采样器。如果你不提供数据,然后模拟样本分析,无条件的先验分布。模拟不返回默认的起始值生成。如果
Mdl是一个mixconjugateblm或mixsemiconjugateblm,然后模拟首先从政权分布,给定的当前状态链(的值RegimeStart,BetaStart,Sigma2Start)。如果你画一个样本和未指定值RegimeStart,BetaStart,Sigma2Start,然后模拟使用默认值并发出警告。

另请参阅
对象
conjugateblm|customblm|diffuseblm|empiricalblm|lassoblm|mixconjugateblm|mixsemiconjugateblm|semiconjugateblm
