customblm
自定义联合先验分布的贝叶斯线性回归模型
描述
的贝叶斯线性回归模型对象customblm载有(β,σ2)。日志pdf是您声明的自定义函数。
数据似然为 在哪里ϕ(yt;xtβ,σ2)为高斯概率密度,求值于yt与的意思xtβ和方差σ2。MATLAB®将先验分布函数视为未知。因此,得到的后验分布在分析上是不可处理的。为了从后验分布中估计或模拟,MATLAB实现了切片采样器。
一般来说,当您创建贝叶斯线性回归模型对象时,它只指定线性回归模型的联合先验分布和特征。也就是说,模型对象是一个用于进一步使用的模板。具体来说,将数据纳入模型进行后验分布分析,将模型对象和数据传递给相应的对象目标函数。
创建
语法
描述
PriorMdl= customblm (NumPredictors,'LogPDF”,LogPDF)PriorMdl由…组成NumPredictors预测器和截距,并设置NumPredictors财产。LogPDF是表示(的联合先验分布的对数的函数。β,σ2)。PriorMdl是定义先验分布和维数的模板吗β。
属性
对象的功能
例子
创建自定义多变量t系数先验模型
考虑预测美国实际国民生产总值(gdp)的多元线性回归模型(GNPR),利用工业生产指数(新闻学会)、总就业人数(E)和实际工资(或者说是)。

对所有 时间点,
时间点,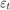 是一系列均值为0,方差为0的独立高斯扰动
是一系列均值为0,方差为0的独立高斯扰动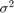 。假设这些先验分布:
。假设这些先验分布:
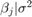 是四维t每个分量的自由度为50度,相关矩阵为单位矩阵。分布也以
是四维t每个分量的自由度为50度,相关矩阵为单位矩阵。分布也以![左${\[{\开始{数组}{* {20}{c}}{- 25} & # 38; 4 & # 38; 0 & # 38; 3结束\{数组}}\右]^ \ '}$](//www.tianjin-qmedu.com/help/examples/econ/win64/CreateCustomMultivariatetPriorModelForCoefficientsExample_eq06094370667326100457.png) 每个分量都被向量的相应元素缩放
每个分量都被向量的相应元素缩放![左${\[{\开始{数组}{* {20}{c}}{1} & # 38; 1 & # 38; 1 & # 38;结束1 \{数组}}\右]^ \ '}$](//www.tianjin-qmedu.com/help/examples/econ/win64/CreateCustomMultivariatetPriorModelForCoefficientsExample_eq17422027603262012745.png) 。
。
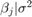
![左${\[{\开始{数组}{* {20}{c}}{- 25} & # 38; 4 & # 38; 0 & # 38; 3结束\{数组}}\右]^ \ '}$](http://www.tianjin-qmedu.com/help/examples/econ/win64/CreateCustomMultivariatetPriorModelForCoefficientsExample_eq06094370667326100457.png)
![左${\[{\开始{数组}{* {20}{c}}{1} & # 38; 1 & # 38; 1 & # 38;结束1 \{数组}}\右]^ \ '}$](http://www.tianjin-qmedu.com/help/examples/econ/win64/CreateCustomMultivariatetPriorModelForCoefficientsExample_eq17422027603262012745.png)
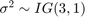 。
。
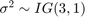
bayeslm将这些假设和数据似然视为相应的后验在分析上难以处理。
声明一个MATLAB®函数:
的值
 和
和 一起在列向量中,并接受超参数的值
一起在列向量中,并接受超参数的值返回联合先验分布的值,
 的值和
的值和

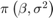
函数logPDF = priorMVTIG(params,ct,st,dof,C,a,b)多变量t乘以逆的对数密度priorMVTIG将参数(1:end-1)传递给多元t密度%函数的自由度为每个组件和正%确定相关矩阵C. priorMVTIG返回乘积的对数这两个计算的密度。%% params:计算密度的参数值% m × 1数值向量。%% ct:多元分布分量中心,(m-1) × 1%数字向量。元素对应于前m-1个元素%的参数。%% st:多元分布分量尺度,(m-1) × 1% numeric (m-1) × 1的数字向量。元素对应于参数的前m-1个元素。%% dof:多元t分布的自由度%数字标量或(m-1) × 1数字向量。priorMVTIG扩展%的标量使得dof = dof*ones(m-1,1)。dof的要素%对应params(1:end-1)中的元素。%% C:多元t分布的相关矩阵% (m-1) × -(m-1)对称正定矩阵。行和%列对应params(1:end-1)中的元素。%% a:反伽玛形状参数,一个正数标量。%% b:反伽马刻度参数,一个正标量。%Beta = params(1:(end-1));Sigma2 = params(end);tVal = (β - ct)./st;mvtDensity = mvtpdf(tVal,C,dof);igDensity = sigma2 ^ (1) * exp (1 / (sigma2 * b)) /(γ(a) * b ^);logPDF = log(mvtDensity*igDensity);结束
创建一个匿名函数,其操作如下priorMVTIG,但只接受参数值,并保持固定的超参数值。
Dof = 50;C =眼(4);Ct = [-25;4;0;3);St = ones(4,1);A = 3;B = 1;logPDF = @(params)priorMVTIG(params,ct,st,dof,C,a,b);
为线性回归参数创建自定义联合先验模型。指定预测器的数量p。另外,指定的函数句柄priorMVTIG还有变量名。
P = 3;PriorMdl = bayeslm(p,“ModelType”,“自定义”,“LogPDF”logPDF,…“VarNames”,[“他们”“E”“福”])
PriorMdl = customblm与属性:NumPredictors: 3 Intercept: 1 VarNames: {4x1 cell} LogPDF: @(params)priorMVTIG(params,ct,st,dof,C,a,b)先验由函数定义:@(params)priorMVTIG(params,ct,st,dof,C,a,b)
PriorMdl是一个customblm贝叶斯线性回归模型对象表示回归系数和扰动方差的先验分布。在这种情况下,bayeslm在命令行中不显示先前发行版的摘要。
估计边际后验分布
考虑中的线性回归模型为系数创建自定义多元先验模型。
创建一个匿名函数,其操作如下priorMVTIG,但只接受参数值,并将超参数值固定在它们的值上。
Dof = 50;C =眼(4);Ct = [-25;4;0;3);St = ones(4,1);A = 3;B = 1;logPDF = @(params)priorMVTIG(params,ct,st,dof,C,a,b);
为线性回归参数创建自定义联合先验模型。指定预测器的数量p。另外,指定的函数句柄priorMVTIG还有变量名。
P = 3;PriorMdl = bayeslm(p,“ModelType”,“自定义”,“LogPDF”logPDF,…“VarNames”,[“他们”“E”“福”])
PriorMdl = customblm与属性:NumPredictors: 3 Intercept: 1 VarNames: {4x1 cell} LogPDF: @(params)priorMVTIG(params,ct,st,dof,C,a,b)先验由函数定义:@(params)priorMVTIG(params,ct,st,dof,C,a,b)
加载Nelson-Plosser数据集。为响应和预测器系列创建变量。
负载Data_NelsonPlosserX = DataTable{:,PriorMdl.VarNames(2:end)};y = DataTable{:,“GNPR”};
估计的边际后验分布 和 。为切片采样器指定一个宽度,该宽度接近于假设弥散先验模型的参数的后验标准差。通过指定稀释因子10来减少序列相关性,并将有效默认绘制数减少因子10。
Width = [20,0.5,0.01,1,20];薄= 10;numDraws = 1e5/thin;rng (1)%为了重现性PosteriorMdl = estimate(PriorMdl,X,y,“宽度”、宽度、“薄”薄的,…“NumDraws”, numDraws);
方法:MCMC抽样10000次观测数:62个预测数:4个|平均Std CI95正分布--------------------------------------------------------------------------截距| -25.0069 0.9919[-26.990,-23.065]0.000经验IPI | 4.3544 0.1083[4.143, 4.562] 1.000经验E | 0.0011 0.0002[0.001, 0.001] 1.000经验WR | 2.5613 0.3293[1.939, 3.222] 1.000经验Sigma2 | 47.0593 8.7570[32.690, 67.115] 1.000经验
PosteriorMdl是一个empiricalblm的后验分布
和
根据数据。估计向命令窗口显示边际后验分布的摘要。摘要的行对应回归系数和扰动方差,列对应后验分布特征。其特点包括:
CI95,其中包含参数的95%贝叶斯均衡可信区间。的回归系数的后验概率或者说是[1.939,3.222]是0.95。积极的,其中包含参数大于0的后验概率。例如,截距大于0的概率为0。
估计从后验分布中提取后验特征,MATLAB®将其作为矩阵存储在属性中BetaDraws和Sigma2Draws。
为了监测MCMC样品的混合和收敛,构建轨迹图。在BetaDraws属性,则绘图与列对应,参数与行对应。
图;为j = 1:4 subplot(2,2,j) plot(PosteriorMdl.BetaDraws(j,:)) title(sprintf())“%s的跟踪图”, PosteriorMdl.VarNames {j}));结束
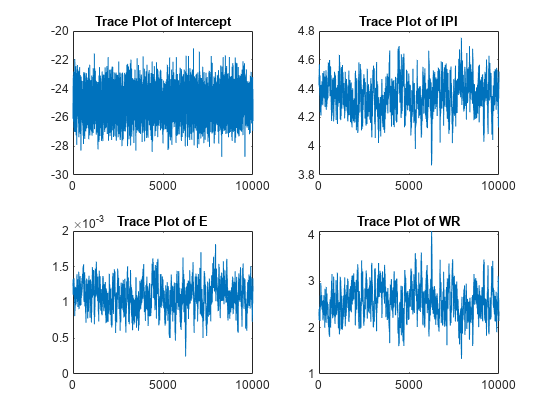
图;情节(PosteriorMdl.Sigma2Draws)标题(“Sigma2的轨迹图”);
迹图表明混合和收敛足够,没有需要消除的瞬态效应。
估计条件后验分布
考虑中的线性回归模型为系数创建自定义多元先验模型。
创建一个匿名函数,其操作如下priorMVTIG,但只接受参数值,并保持固定的超参数值。
Dof = 50;C =眼(4);Ct = [-25;4;0;3);St = ones(4,1);A = 3;B = 1;logPDF = @(params)priorMVTIG(params,ct,st,dof,C,a,b);
为线性回归参数创建自定义联合先验模型。指定预测器的数量p。另外,指定的函数句柄priorMVTIG还有变量名。
P = 3;PriorMdl = bayeslm(p,“ModelType”,“自定义”,“LogPDF”logPDF,…“VarNames”,[“他们”“E”“福”])
PriorMdl = customblm与属性:NumPredictors: 3 Intercept: 1 VarNames: {4x1 cell} LogPDF: @(params)priorMVTIG(params,ct,st,dof,C,a,b)先验由函数定义:@(params)priorMVTIG(params,ct,st,dof,C,a,b)
加载Nelson-Plosser数据集。为响应和预测器系列创建变量。
负载Data_NelsonPlosserX = DataTable{:,PriorMdl.VarNames(2:end)};y = DataTable{:,“GNPR”};
估计的条件后验分布 给定数据和 ,并返回评估汇总表以访问评估。为切片采样器指定一个宽度,该宽度接近于假设弥散先验模型的参数的后验标准差。通过指定稀释因子10来减少序列相关性,并将有效默认绘制数减少因子10。
Width = [20,0.5,0.01,1];薄= 10;numDraws = 1e5/thin;rng (1)%为了重现性[Mdl,Summary] = estimate(PriorMdl,X,y)“Sigma2”2,…“宽度”、宽度、“薄”薄的,“NumDraws”, numDraws);
方法:MCMC抽样10000次,条件变量:Sigma2固定为2观测值:624 |意味着性病CI95积极的分布 -------------------------------------------------------------------------- 拦截| -24.7820 - 0.8767[-26.483,-23.054]0.000经验IPI | 4.3825 - 0.0254[4.332, 4.431] 1.000经验E | 0.0011 - 0.0000[0.001, 0.001] 1.000经验或者说是| 2.4752 - 0.0724[2.337,2.618]1.000经验Sigma2 | 2 0[2.000, 2.000] 1.000经验
估计显示的条件后验分布的摘要
。因为
在估计时固定为2,对它的推论是微不足道的。
提取的条件后验的均值向量和协方差矩阵 从估计汇总表中。
condPostMeanBeta =摘要。平均值(1:(end - 1))
condPostMeanBeta =4×1-24.7820 4.3825 0.0011 2.4752
CondPostCovBeta =摘要。协方差(1:(end - 1),1:(end - 1))
CondPostCovBeta =4×40.7686 0.0084 -0.0000 0.0019 0.0084 0.0006 0.0000 -0.0015 -0.0000 0.0019 -0.0015 -0.0000 0.0052
显示Mdl。
Mdl
Mdl = customblm与属性:NumPredictors: 3 Intercept: 1 VarNames: {4x1 cell} LogPDF: @(params)priorMVTIG(params,ct,st,dof,C,a,b)先验由函数定义:@(params)priorMVTIG(params,ct,st,dof,C,a,b)
因为估计计算条件后验分布,它返回原始先验模型,而不是后验,在输出参数列表的第一个位置。同时,估计不退回MCMC样品。因此,要监视MCMC样本的收敛性,请使用模拟并指定相同的随机数种子。
用蒙特卡罗模拟估计后验概率
考虑中的线性回归模型估计边际后验分布。
为回归系数和扰动方差创建一个先验模型,然后估计边际后验分布。关闭估算显示。
Dof = 50;C =眼(4);Ct = [-25;4;0;3);St = ones(4,1);A = 3;B = 1;logPDF = @(params)priorMVTIG(params,ct,st,dof,C,a,b); p = 3; PriorMdl = bayeslm(p,“ModelType”,“自定义”,“LogPDF”logPDF,…“VarNames”,[“他们”“E”“福”]);负载Data_NelsonPlosserX = DataTable{:,PriorMdl.VarNames(2:end)};y = DataTable{:,“GNPR”};Width = [20,0.5,0.01,1,20];薄= 10;numDraws = 1e5/thin;rng (1)%为了重现性PosteriorMdl = estimate(PriorMdl,X,y,“宽度”、宽度、“薄”薄的,…“NumDraws”numDraws,“显示”、假);
估计后验分布汇总统计量 利用后验分布的数据存储在后验模型中。
estBeta = mean(PosteriorMdl.BetaDraws,2);EstBetaCov = cov(PosteriorMdl.BetaDraws');
假设实际工资系数(或者说是)低于2.5,则制定政策。虽然后验分布或者说是是已知的,你可以直接计算概率,你可以用蒙特卡罗模拟来估计概率。
画1 e6的边际后验分布的样本
。
numdraw_1e6;BetaSim =模拟(postiormdl;“NumDraws”, NumDraws);
BetaSim是4 × -1 e6包含平局的矩阵。行对应回归系数,列对应连续绘制。
隔离与系数相对应的绘图或者说是,然后确定哪些平局小于2.5。
isWR = postiormdl。VarNames = =“福”;wrSim = BetaSim(isWR,:);isWRLT2p5 = wrSim < 2.5;
求回归系数的边际后验概率或者说是通过计算小于2.5的平局的比例,小于2.5。
probWRLT2p5 = mean(isWRLT2p5)
probWRLT2p5 = 0.4430
的后验概率系数或者说是小于2.5是什么意思0.4430。
使用后验预测分布预测反应
考虑中的线性回归模型估计边际后验分布。
为回归系数和扰动方差创建一个先验模型,然后估计边际后验分布。保留最近10个时期的估计数据,以便您可以使用它们来预测实际GNP。关闭估算显示。
负载Data_NelsonPlosserVarNames = {“他们”;“E”;“福”};FHS = 10;预测地平线大小%X = DataTable{1:(end - fhs),VarNames};y = DataTable{1:(end - fhs),“GNPR”};XF = DataTable{(end - fhs + 1):end,VarNames};%未来预测数据yFT = DataTable{(end - fhs + 1):end,“GNPR”};未来真实回答百分比Dof = 50;C =眼(4);Ct = [-25;4;0;3);St = ones(4,1);A = 3;B = 1;logPDF = @(params)priorMVTIG(params,ct,st,dof,C,a,b); p = 3; PriorMdl = bayeslm(p,“ModelType”,“自定义”,“LogPDF”logPDF,…“VarNames”, VarNames);Width = [20,0.5,0.01,1,20];薄= 10;numDraws = 1e5/thin;rng (1)%为了重现性PosteriorMdl = estimate(PriorMdl,X,y,“宽度”、宽度、“薄”薄的,…“NumDraws”numDraws,“显示”、假);
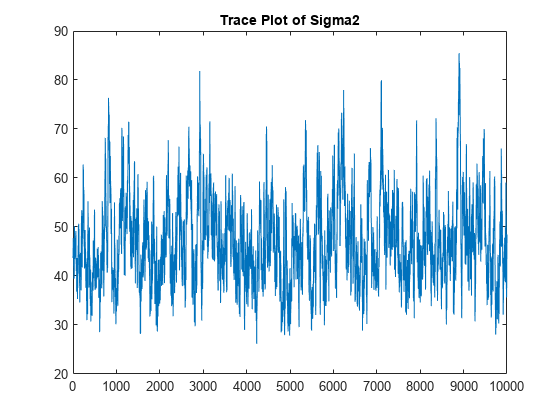
使用后验预测分布和未来预测数据预测响应XF。绘制响应的真实值和预测值。
yF = forecast(PosteriorMdl,XF);图;情节(日期、DataTable.GNPR);持有在plot(dates((end - fhs + 1):end),yF) h = gca;HP = patch([dates(end - FHS + 1) dates(end) dates(end) dates(end) dates(end) dates(end - FHS + 1)],…h.YLim([1,1,2,2]),[0.8 0.8 0.8]);uistack(惠普、“底”);传奇(“预测地平线”,“真正的GNPR”,“预测GNPR”,“位置”,“西北”)标题(“实际国民生产总值”);ylabel (“rGNP”);包含(“年”);持有从
yF是与未来预测器数据相对应的实际国民生产总值未来值的10乘1向量。
估计预测均方根误差(RMSE)。
frmse = sqrt(mean((yF - yFT).^2))
Frmse = 12.8148
预测均方根误差是预测精度的相对度量。具体来说,您使用不同的假设来估计几个模型。预测均方根误差最低的模型是被比较的模型中表现最好的模型。
更多关于
选择
的bayeslm函数可以为贝叶斯线性回归创建任何支持的先验模型对万博1manbetx象。