lassoblm
贝叶斯线性回归模型和套索正规化
描述
的贝叶斯线性回归模型对象lassoblm指定联合先验分布的回归系数和扰动方差(β,σ2)实现贝叶斯套索回归[1]。为j= 1,…,NumPredictors条件的先验分布βj|σ2拉普拉斯(双指数)分布的意思是0和规模σ2/λ,在那里λ套索正规化,或收缩,参数。的先验分布σ2是逆伽马和形状吗一个和规模B。
数据可能是 在哪里ϕ(yt;xtβ,σ2)是高斯概率密度评估yt与的意思xtβ和方差σ2。由此产生的后验分布是不易于分析。后验分布的详细信息,请参见易于分析后验。
一般来说,当你创建一个贝叶斯线性回归模型对象,它指定了联合线性回归模型的先验分布和特点。即模型对象是一个模板供进一步使用。具体地说,将数据分析和特征选择后验分布的模型,将模型对象和数据传递到合适的目标函数。
创建
描述
属性
对象的功能
例子
为贝叶斯套索创建之前模型回归
考虑的多元线性回归模型预测美国实际国民生产总值(GNPR)使用工业生产指数的线性组合新闻学会)、就业总人数(E),实际工资(或者说是)。
对所有 , 是一系列的独立和0的均值和方差高斯干扰吗 。
假设这些先验分布:
为j= 0,…,3, 拉普拉斯分布平均值为0和规模 ,在那里 是收缩参数。系数是条件独立的。
。 和 分别是形状和规模的逆伽马分布。
创建一个先验贝叶斯线性回归模型。指定数量的预测p。
p = 3;Mdl = lassoblm (p);
PriorMdl是一个lassoblm贝叶斯线性回归模型对象代表回归系数的先验分布和扰动方差。在命令窗口中,lassoblm显示一个先验分布的摘要。
或者,您可以创建一个先验贝叶斯模型套索回归通过预测的数量bayeslm并设置ModelType名称-值对参数“套索”。
MdlBayesLM = bayeslm (p,“ModelType”,“套索”)
MdlBayesLM = lassoblm属性:NumPredictors: 3拦截:1 VarNames:{4×1细胞}λ:[4×1双):3 B: 1 |意味着性病CI95积极分配- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -拦截| 0 100[-200.000,200.000]0.500级混合β(1)| 0 1[-2.000,2.000]0.500级混合β(2)| 0 1[-2.000,2.000]0.500级混合β(3)| 0 1[-2.000,2.000]0.500级混合Sigma2 | 0.5000 - 0.5000[0.138, 1.616] 1.000搞笑(3.00,1)
Mdl和MdlBayesLM是等价的模型对象。
你可以设置可写属性值创建模型的使用点符号。回归系数的名称设置为相应的变量名。
Mdl.VarNames=[“他们”“E”“福”]
Mdl = lassoblm属性:NumPredictors: 3拦截:1 VarNames:{4×1细胞}λ:[4×1双):3 B: 1 |意味着性病CI95积极分配- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -拦截| 0 100[-200.000,200.000]0.500级混合IPI | 0 1[-2.000, 2.000] 0.500级混合E | 0 1[-2.000, 2.000] 0.500级混合WR | 0 1[-2.000, 2.000] 0.500级混合Sigma2 | 0.5000 - 0.5000[0.138, 1.616] 1.000搞笑(3.00,1)
MATLAB®associates的回归系数显示的变量名。
执行变量选择使用默认套索收缩
考虑线性回归模型为贝叶斯套索创建之前模型回归。
创建一个模型执行贝叶斯套索之前回归。指定数量的预测p和回归系数的名称。
p = 3;PriorMdl = bayeslm (p,“ModelType”,“套索”,“VarNames”,(“他们”“E”“福”]);收缩= PriorMdl.Lambda
收缩=4×10.0100 1.0000 1.0000 1.0000
PriorMdl商店的所有预测收缩值λ财产。收缩(1)拦截的收缩,元素的收缩(2:结束)对应系数的预测因子Mdl.VarNames。默认的拦截的收缩0.01,默认的1对于所有其他系数。
加载Nelson-Plosser数据集。为响应和预测系列创建变量。因为套索敏感变量尺度,规范所有变量。
负载Data_NelsonPlosserX = DataTable {: PriorMdl.VarNames(2:结束)};y = DataTable {:,“GNPR”};X = (X -意味着(X,“omitnan”)。/性病(X,“omitnan”);y = (y -意味着(y,“omitnan”))/性病(y,“omitnan”);
尽管这个示例标准化变量,您可以指定为每个系数通过设置不同的收缩值λ的属性PriorMdl一个数值向量收缩值。
实现贝叶斯套索回归估计边缘后验分布的 和 。因为贝叶斯套索回归使用马尔可夫链蒙特卡罗(密度)估计,设置一个随机数种子繁殖的结果。
rng (1);PosteriorMdl =估计(PriorMdl, X, y);
方法:拉索与10000年获得了数量的观察:62年的预测数量:4 |意味着性病CI95积极分配- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -拦截| -0.4490 - 0.0527[-0.548,-0.344]0.000经验IPI | 0.6679 - 0.1063[0.456, 0.878] 1.000经验E | 0.1114 - 0.1223[-0.110, 0.365] 0.827经验或者说是| 0.2215 - 0.1367[-0.024,0.494]0.956经验Sigma2 | 0.0343 - 0.0062[0.024, 0.048] 1.000经验
PosteriorMdl是一个empiricalblm模型对象存储的后验分布
和
考虑到数据。估计显示一个总结边缘后验分布的命令行。行总结对应回归系数和扰动变化,和列对应于后验分布的特征。特点包括:
CI95,其中包含参数的贝叶斯equitailed 95%可信区间。例如,后验概率的回归系数E(标准化)是在[-0.110,0.365]是0.95。积极的,其中包含参数的后验概率大于0。例如,截距大于0的概率是0。
默认情况下,估计平,丢弃5000年老化的样本大小。然而,一个良好的实践是检查跟踪的情节吸引了足够的混合和缺乏无常。画一个跟踪每个参数的情节吸引了。您可以访问了组成分布(属性BetaDraws和Sigma2Draws使用点符号)。
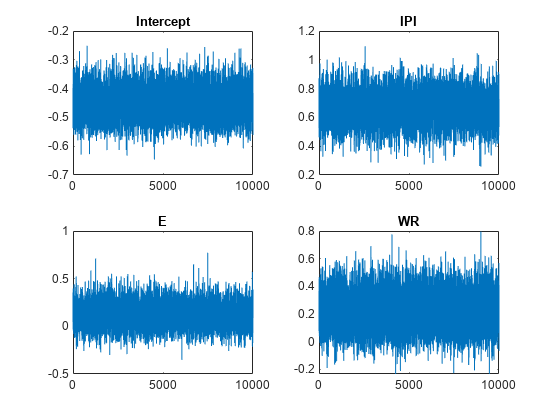
图;为j = 1: (p + 1)次要情节(2,2,j);情节(PosteriorMdl.BetaDraws (j,:));标题(sprintf (' % s ',PosteriorMdl.VarNames {j}));结束
图;情节(PosteriorMdl.Sigma2Draws);标题(“Sigma2”);
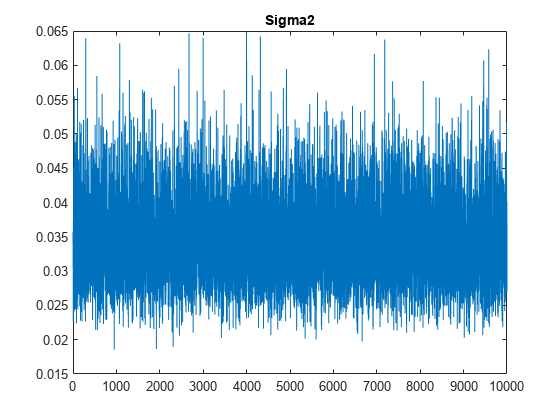
跟踪情节似乎表明了混合好。情节没有检测到无常或序列相关性,和州之间的吸引不跳。
情节后验分布的方差系数和干扰。
图;情节(PosteriorMdl)
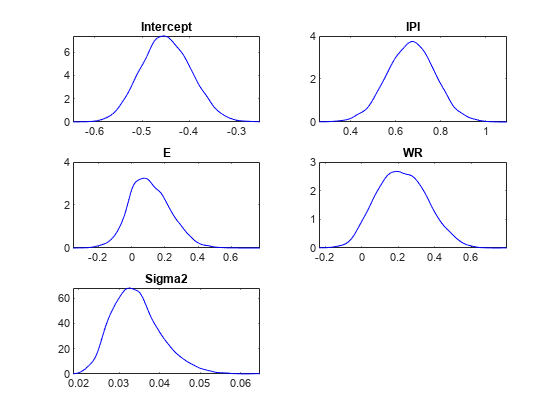
E和或者说是可能不是重要的预测因子因为0是高密度区域内的后验分布。
属性不同的收缩值系数
考虑线性回归模型为贝叶斯套索创建之前模型回归和它的实现执行变量选择使用默认套索收缩。
当你实现套索回归,一个常见的做法是标准化变量。然而,如果你想保留系数的解释,但变量有不同的尺度,那么您可以执行不均匀收缩通过指定一个不同的收缩系数。
创建一个模型执行贝叶斯套索之前回归。指定数量的预测p和回归系数的名称。
p = 3;PriorMdl = bayeslm (p,“ModelType”,“套索”,“VarNames”,(“他们”“E”“福”]);
加载Nelson-Plosser数据集。为响应和预测系列创建变量。确定变量的指数趋势通过绘制每个在单独的数据。
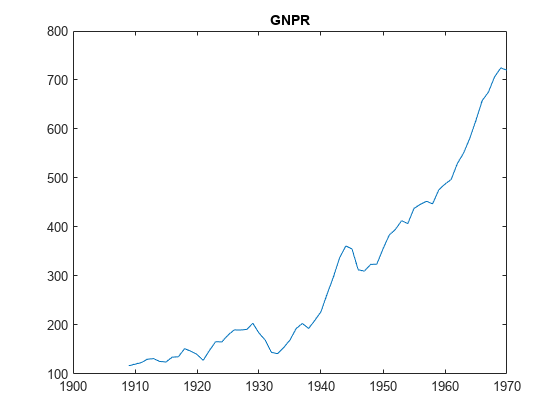
负载Data_NelsonPlosserX = DataTable {: PriorMdl.VarNames(2:结束)};y = DataTable {:,“GNPR”};图;情节(日期、y)标题(“GNPR”)
为j = 1:3图;情节(日期、X (:, j));标题(PriorMdl。VarNames (j+1));结束
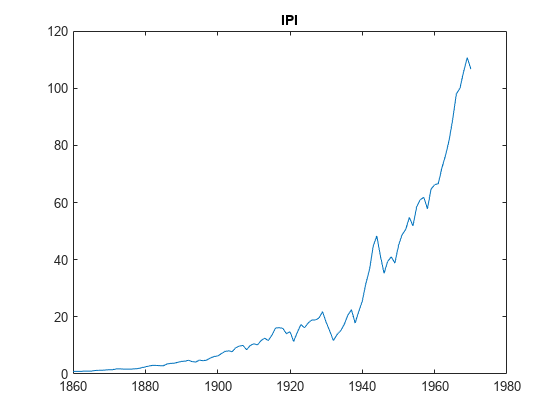
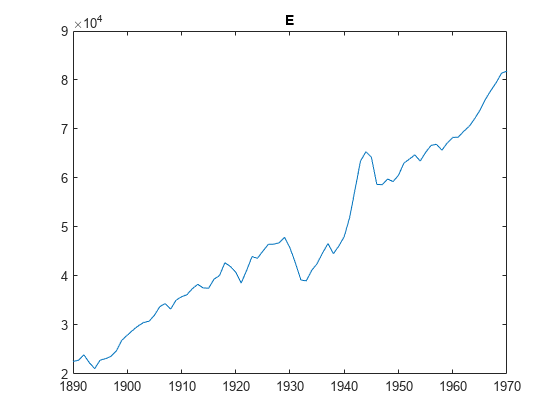
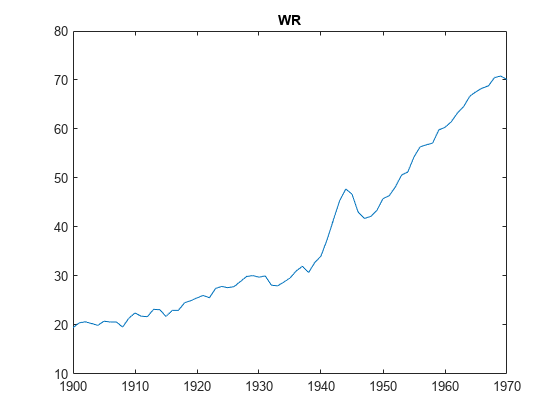
的变量GNPR,新闻学会,或者说是似乎一个指数的趋势。
删除变量的指数趋势GNPR,新闻学会,或者说是。
y =日志(y);X(: 3[1]) =日志(X (:, 3 [1]));
所有预测变量有不同的尺度(有关详细信息,输入描述在命令行)。显示每个预测的意思。删除包含主要观察缺失值预测。
predmeans =意味着(X,“omitnan”)
predmeans =1×3104×0.0002 4.7700 0.0004
第二个预测的值要大得多比其他两个预测和响应。因此,第二个预测可能出现的回归系数接近于零。
使用点符号、属性拦截一个非常低的收缩,收缩0.1第一个和第三个预测,1000年和收缩第二个预测。
PriorMdl。λ=[1e-5 0.1 1e4 0.1];
实现贝叶斯套索回归估计边缘后验分布的 和 。因为贝叶斯套索回归使用密度估计,设置一个随机数种子繁殖的结果。
rng (1);PosteriorMdl =估计(PriorMdl, X, y);
方法:拉索与10000年获得了数量的观察:62年的预测数量:4 |意味着性病CI95积极分配- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -拦截| 2.0281 - 0.6839[0.679,3.323]0.999经验IPI | 0.3534 - 0.2497[-0.139, 0.839] 0.923经验E | 0.0000 - 0.0000[-0.000, 0.000] 0.762经验或者说是| 0.5250 - 0.3482[-0.126,1.209]0.937经验Sigma2 | 0.0315 - 0.0055[0.023, 0.044] 1.000经验
使用后预测分布预测的反应
考虑线性回归模型为贝叶斯套索创建之前模型回归。
执行贝叶斯套索回归:
创建一个贝叶斯套索之前模型回归系数和扰动方差。使用默认的收缩。
坚持过去10期从估计的数据。
估计边缘后验分布。
p = 3;PriorMdl = bayeslm (p,“ModelType”,“套索”,“VarNames”,(“他们”“E”“福”]);负载Data_NelsonPlosserfhs = 10;%预测地平线大小X = DataTable{1:(结束- fhs), PriorMdl.VarNames(2:结束)};y = DataTable{1:(结束- fhs),“GNPR”};XF = DataTable{(结束- fhs + 1):最终,PriorMdl.VarNames(2:结束)};%未来的预测数据yFT = DataTable{(结束- fhs + 1):结束,“GNPR”};%未来真实的反应rng (1);%的再现性PosteriorMdl =估计(PriorMdl, X, y,“显示”、假);
预测使用后反应预测分布和未来预测数据XF。情节的真实值响应和预测的值。
yF =预测(PosteriorMdl XF);图;情节(日期、DataTable.GNPR);持有在情节(日期((结束- fhs + 1):结束),yF h = gca;惠普=补丁([日期(结束- fhs + 1)日期(结束)日期(结束)日期(结束- fhs + 1)),…h.YLim ([1, 1、2、2]), [0.8 0.8 0.8]);uistack(惠普、“底”);传奇(“预测地平线”,“真正的GNPR”,“预测GNPR”,“位置”,“西北”)标题(“真正的国民生产总值:1909 - 1970”);ylabel (“rGNP”);包含(“年”);持有从
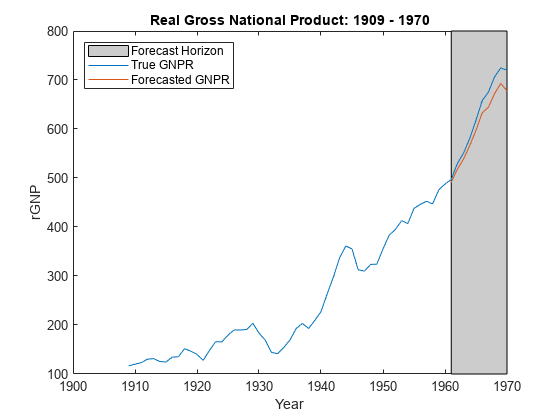
yF是一个10-by-1向量的值相对应的实际国民生产总值未来预测数据。
估计预测均方误差(RMSE)。
frmse =√意味着(yF - yFT) ^ 2))
frmse = 25.4831
预测均方根误差是一个相对程度的预测精度。具体地说,您估计几个使用不同的假设模型。最低的模型预测的RMSE是表现最好的模型相比较。
当您执行贝叶斯套索回归,一个最佳实践是寻找合适的收缩值。这样做的方法之一是估计预测RMSE超过一个网格的收缩值,并选择最小化预测RMSE的收缩。
更多关于
提示
λ是一个调优参数。因此,使用一个网格执行贝叶斯套索回归的收缩值,并选择最佳平衡的模型符合标准和模型的复杂性。MATLAB仿真,估计和预测®不规范预测数据。如果变量在预测数据有不同的尺度,然后指定一个收缩参数为每个预测通过提供一个数值向量
λ。
选择功能
的bayeslm函数可以创建任何支持先前对贝叶斯线性回归的模型对万博1manbetx象。
引用
[1]公园,T。,G。Casella. "The Bayesian Lasso."美国统计协会杂志》上。103卷,482号,2008年,页681 - 686。