主要内容
网格化和分散的样本数据
插值是一种在位于一组样本数据点域内的查询位置估计函数值的方法。函数值基于最接近查询点的样本数据点计算。MATLAB®可以根据样本数据的结构执行两种插值。样本数据可以形成网格,也可以分散。
网格化的样本数据使得插值更加有效,因为数据的组织结构使得MATLAB很容易找到最接近查询点的样本数据点。但是,插值分散的数据需要三角剖分这就引入了一个额外的计算层。因此,如果您的数据可以近似为网格,则网格插值与分散插值相比,在计算时间和内存使用方面节省了大量资源。
以下主题介绍了插值的两种方法:


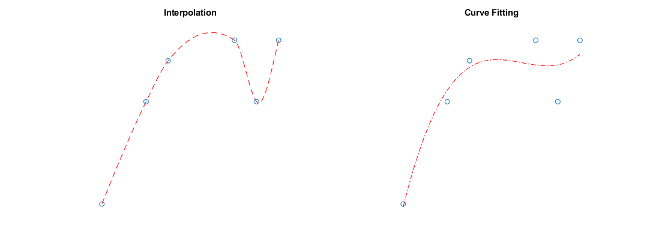
插值与曲线拟合
MATLAB中可用的插值方法创建通过采样数据点的插值函数。也就是说,如果在采样位置查询插值函数,则返回的是精确的采样数据值,而不是近似值。相比之下,曲线和曲面拟合算法不一定通过采样数据点。有关曲线拟合的详细信息,请参见曲线拟合工具箱.
网格逼近技术
在某些情况下,可能需要为数据近似设置网格。例如,栅格可以具有沿曲线分布的点。如果您的数据基于经度和纬度,则可能会出现这样的数据集:
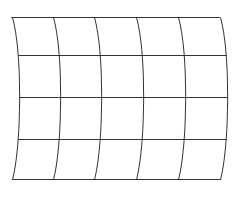
使用曲线网格,可以有效地处理一组分散的数据,并且必须使用计算成本更高的分散插值函数来插值值。然而,尽管不能直接对输入数据进行网格化,但有时可以在适当的间隔处用直线网格线近似曲线网格:
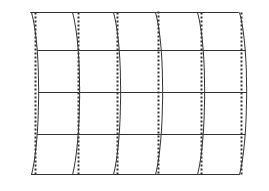
您可以通过创建一组具有适当间距的网格向量来创建近似网格。使用直线近似曲线网格可以获得基于网格的插值的性能优势,但代价是稍微扭曲数据。有关创建网格向量的更多信息,请参阅网格表示.
另见
相关话题
您还可以从以下列表中选择网站:
