主要内容
findgroups
查找组和返回组号
句法
描述
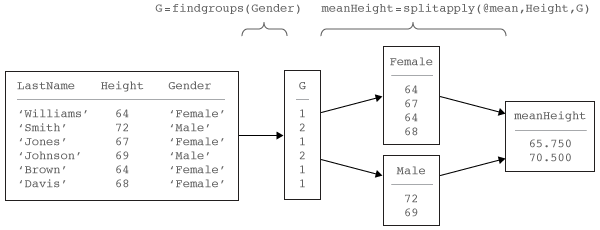
G= findgroups(一种)G,从分组变量创建的组编号的向量一种。输出参数G包含整数值从1到N,表明N不同群体的N在唯一值一种。例如,如果一种是{ 'B', 'A', 'A', 'B'}, 然后findgroups回报G作为[2 1 1 2]。您可以使用G数据的拆分组出的其他变量。用G作为输入参数,以splitapply当分体式应用组合工作流程。
findgroups对待空字符向量和南那的NaT和未定义分类值在一种作为缺失的值和返回南作为对相应的元件G。
例子
输入参数
输出参数
更多关于
分体式应用组合工作流程
当拆分申请,合并工作流是在数据分析常见。在这个工作流程中,分析将数据分成组,应用一个函数到每个组,并组合结果。该图显示了工作流的一个典型的例子和工作流的通过实现部件findgroups和splitapply。
扩展能力
也可以看看
accumarray|Arrayfun.|convertvars|离散化|团体ummary|节目|ismember|rowfun|splitapply|独特的|varfun|vartype.
在R2015B中介绍
您还可以从以下列表中选择一个网站:
