Scale Up from Desktop to Cluster
此示例显示了如何在本地机器上开发并行MATLAB®代码,并扩展到群集。集群提供更多的计算资源来加快和分发您的计算。您可以在本地计算机上并行交互方式运行代码,然后在群集上,而无需更改代码。完成本地计算机上的代码原型后,您可以使用批处理作业将计算卸载到集群中。因此,您可以关闭MATLAB并稍后检索结果。
Develop Your Algorithm
首先在本地计算机上原型制作算法。该示例使用整数分解作为样本问题。这是一个计算密集的问题,其中分解的复杂性随数量的大小而增加。您使用简单的算法来分解一系列整数编号。
以64位的精度创建质数的矢量,然后随机乘以成对的素数以获得大型的复合数。创建一个数组来存储每个分解的结果。以下每个示例中的每个部分中的代码可能需要超过20分钟。为了使其更快,请使用较少的质数减少工作量,例如2^19。Run with2^21to see the optimum final plots.
primenumbers = primes(uint64(2^21));compositenumbers = Primenumbers。因子=零(Numel(Primenumbers),2);
使用循环来考虑每个复合数,并测量计算所需的时间。
tic;foridx = 1:numel(compositeNumbers)因子(idx,:) = factor(compositenumbers(idx));endtoc
经过的时间为684.464556秒。
在本地平行池上运行代码
并行计算工具箱™使您可以通过在并行池中的多个工人上运行来扩展工作流程。上一个迭代forloop are independent, and so you can use aparforloop to distribute iterations to multiple workers. Simply transform yourforloop into aparfor环形。然后,运行代码并测量整体计算时间。该代码在平行池中运行,没有进一步的更改,工人将您的计算发送回本地工作区。由于工作负载分布在几个工人之间,因此计算时间较低。
tic;parforidx = 1:numel(compositeNumbers)因子(idx,:) = factor(compositenumbers(idx));endtoc
经过的时间为144.550358秒。
When you useparforand you have Parallel Computing Toolbox, MATLAB automatically starts a parallel pool of workers. The parallel pool takes some time to start. This example shows a second run with the pool already started.
默认集群配置文件是'local'。You can check that this profile is set as default on the MATLABHometab, inParallel>选择默认集群。With this profile enabled, MATLAB creates workers on your machine for the parallel pool. When you use the'local'profile, MATLAB, by default, starts as many workers as physical cores in your machine, up to your preferred number of workers. You can control parallel behavior using the parallel preferences. On the MATLABHometab, selectParallel>Parallel Preferences。
To measure the speedup with the number of workers, run the same code several times, limiting the maximum number of workers. First, define the number of workers for each run, up to the number of workers in the pool, and create an array to store the result of each test.
numWorkers = [1 2 4 6]; tLocal = zeros(size(numWorkers));
用一个循环遍历的最大数量f workers, and run the previous code. To limit the number of workers, use the second input argument ofparfor。
forw = 1:numel(numworkers)tic;parfor(idx = 1:numel(compositeNumbers),numworkers(w))因子(idx,:) = factor(compositeNumbers(idx));endtLocal(w) = toc;end
Calculate the speedup by computing the ratio between the computation time of a single worker and the computation time of each maximum number of workers. To visualize how the computations scale up with the number of workers, plot the speedup against the number of workers. Observe that the speedup increases with the number of workers. However, the scaling is not perfect due to overhead associated with parallelization.
f = figure; speedup = tLocal(1)./tLocal; plot(numWorkers, speedup); title('Speedup with the number of workers');Xlabel(“工人人数”);Xticks(Numworkers);ylabel('Speedup');

When you are done with your computation, delete the current parallel pool so you can create a new one for your cluster. You can obtain the current parallel pool with thegcpfunction.
delete(gcp);
Set up Your Cluster
If your computing task is too big or too slow for your local computer, you can offload your calculation to a cluster onsite or in the cloud. Before you can run the next sections, you must get access to a cluster. On the MATLABHometab, go toParallel>Discover Clusters找出您是否已经可以使用MATLAB Parallel Server™访问群集。有关更多信息,请参阅Discover Clusters。
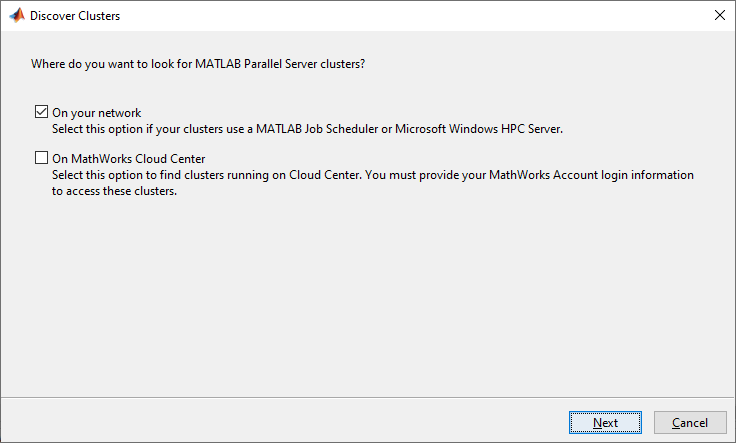
If you do not have access to a cluster, you must configure access to one before you can run the next sections. In MATLAB, you can create clusters in a cloud service, such as Amazon AWS, directly from the MATLAB Desktop. On theHometab, in theParallelmenu, selectCreate and Manage Clusters。In the Cluster Profile Manager, click创建云集群。要了解有关扩展到云的更多信息,请参阅Getting Started with Cloud Center。To learn more about your options for scaling to a cluster in your network, seeGet Started with MATLAB Parallel Server(MATLAB Parallel Server)。
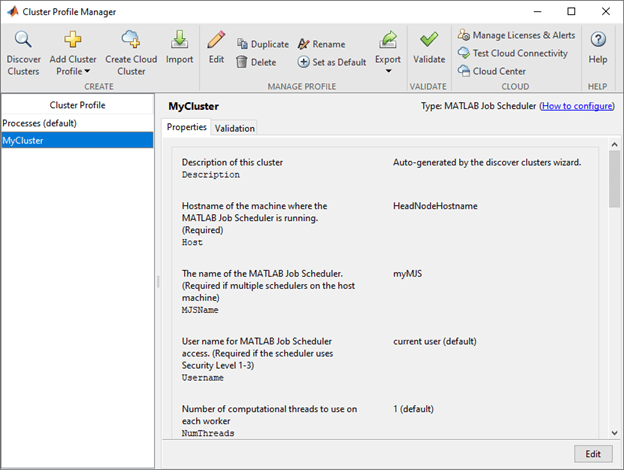
After you set up a cluster profile, you can modify its properties inParallel>Create and Manage Clusters。有关更多信息,请参阅Discover Clusters and Use Cluster Profiles。The following image shows a cluster profile in the集群配置文件管理器:
在集群并行池上运行代码
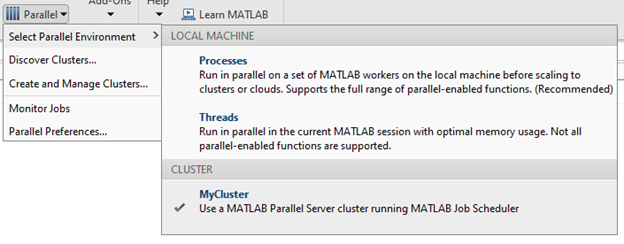
如果要默认在集群中运行并行功能,请将群集配置文件设置为默认Parallel>选择默认集群:
You can also use a programmatic approach to specify your cluster. To do so, start a parallel pool in the cluster by specifying the name of your cluster profile in theParpool命令。在以下代码中,替换MyClusterwith the name of your cluster profile. Also specify the number of workers with the second input argument.
Parpool(“ mycluster',64);
使用“ mycluster”配置文件...连接到64名工人。
和以前一样,通过几次运行相同的代码来测量工人数量的加速,并限制最大工人数量。因为此示例中的群集允许比本地设置更多的工人,所以numWorkerscan hold more values. If you run this code, theparforloop now runs in the cluster.
numWorkers = [1 2 4 6 16 32 64]; tCluster = zeros(size(numWorkers));forw = 1:numel(numworkers)tic;parfor(idx = 1:numel(compositeNumbers),numworkers(w))因子(idx,:) = factor(compositeNumbers(idx));endtcluster(w)= toc;end
Calculate the speedup, and plot it against the number of workers to visualize how the computations scale up with the number of workers. Compare the results with those of the local setup. Observe that the speedup increases with the number of workers. However, the scaling is not perfect due to overhead associated with parallelization.
图(f);抓住on速度= tcluster(1)./ tcluster;情节(Numworkers,Speedup);标题('Speedup with the number of workers');Xlabel(“工人人数”);xticks(numWorkers(2:end)); ylabel('Speedup');

完成计算后,删除当前的并行池。
delete(gcp);
卸载和扩展您的计算batch
After you are done prototyping and running interactively, you can use batch jobs to offload the execution of long-running computations in the background with batch processing. The computation happens in the cluster, and you can close MATLAB and retrieve the results later.
使用batch功能以将批处理作业提交给您的群集。您可以将算法的内容放在脚本中,并使用batch提交它的功能。例如,脚本myParallelAlgorithmperforms a simple benchmark based on the integer factorization problem shown in this example. The script measures the computation time of several problem complexities with different number of workers.
请注意,如果您使用脚本文件batchMATLAB转移所有工作空间变量the cluster, even if your script does not use them. If you have a large workspace, it impacts negatively the data transfer time. As a best practice, convert your script to a function file to avoid this communication overhead. You can do this by simply adding a function line at the beginning of your script. To learn how to convertmyParallelAlgorithmto a function, seemyParallelAlgorithmFcn。
The following code submitsmyParallelAlgorithmFcnas a batch job.myParallelAlgorithmFcnreturns two output arguments,numWorkersandtime,,,,and you must specify2as the number of outputs input argument. Because the code needs a parallel pool for theparforloop, use the'水池'name-value pair inbatch指定工人人数。群集使用额外的工人运行该功能本身。默认,batchchanges the current folder of the workers in the cluster to the current folder of the MATLAB client. It can be useful to control the current folder. For example, if your cluster uses a different filesystem, and therefore the paths are different, such as when you submit from a Windows client machine to a Linux cluster. Set the name-value pair'CurrentFolder'到您选择的文件夹,或'。'to avoid changing the folder of the workers.
TotalNumberOfWorkers = 65;群集= Parcluster(“ mycluster');job = batch(cluster,'myParallelAlgorithmFcn',,,,2,,,,'水池',,,,totalNumberOfWorkers-1,'CurrentFolder',,,,'。');
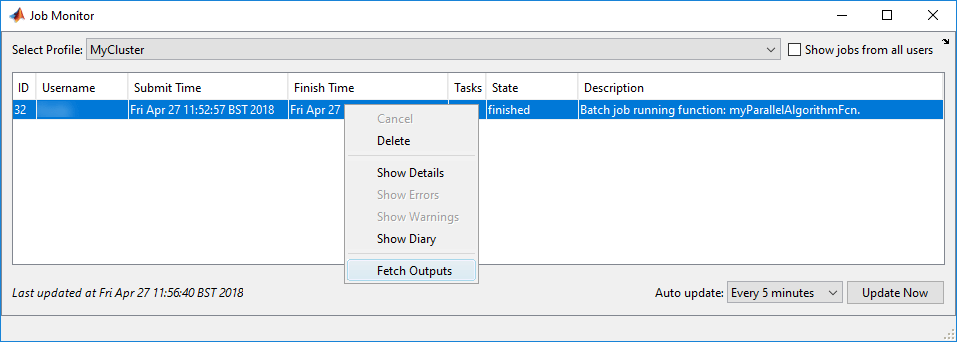
要在提交后监视工作状态,请打开工作监视器Parallel>监视工作。When computations start in the cluster, the state of the job changes torunning:

You can close MATLAB after the job has been submitted. When you open MATLAB again, the Job Monitor keeps track of the job for you, and you can interact with it if you right-click it. For example, to retrieve the job object, selectShow Details,,,,and to transfer the outputs of the batch job into the workspace, selectFetch Outputs。
Alternatively, if you want to block MATLAB until the job completes, use thewaitfunction on the job object.
等待(工作);
To transfer the outputs of the function from the cluster, use thefetchOutputsfunction.
outputs = fetchOutputs(job); numWorkers = outputs{1}; time = outputs{2};
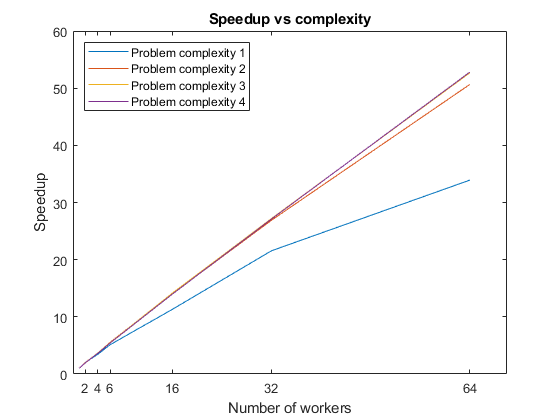
After retrieving the results, you can use them for calculations on your local machine. Calculate the speedup, and plot it against the number of workers. Because the code runs factorizations for different problem complexities, you get a plot for each level. You can see that, for each problem complexity, the speedup increases with the number of workers, until the overhead for additional workers is greater than the performance gain from parallelization. As you increase the problem complexity, you achieve better speedup at large numbers of workers, because overhead associated with parallelization is less significant.
figure speedup = time(1,:)./time; plot(numWorkers,speedup); legend(问题复杂性1',,,,“问题复杂性2”,,,,'Problem complexity 3',,,,'Problem complexity 4',,,,'Location',,,,'northwest');标题(“加速与复杂性”);Xlabel(“工人人数”);xticks(numWorkers(2:end)); ylabel('Speedup');
也可以看看
batch|fetchOutputs (Job)|parfor|Parpool
相关示例
更多关于
- Parallel for-Loops (parfor)
- Get Started with MATLAB Parallel Server(MATLAB Parallel Server)
You can also select a web site from the following list:
Americas
- América Latina(Español)
- Canada(English)
- United States(English)