二维CFAR检测器
二维恒虚警率(CFAR)检测器
- 库:
相控阵系统工具箱/检测
描述
的二维CFAR检测器块实现了二维图像数据的恒定虚警率检测器。当图像单元值超过阈值时,就声明检测。为了保持一个恒定的误报率,阈值被设置为图像噪声功率的倍数。检测器估计被测单元周围邻近单元的噪声功率(减少)使用三种单元格平均方法或顺序统计方法中的一种。细胞平均法有细胞平均法(CA)、最大细胞平均法(GOCA)或最小细胞平均法(SOCA)。
对于每个测试单元,检测器:
从围绕CUT单元的训练带中的单元值估计噪声统计量。
通过将噪声估计乘以阈值因子来计算阈值。
将剪切单元值与阈值进行比较,以确定目标是否存在。如果该值大于阈值,则表示存在目标。
港口
输入
输出
参数
算法
CFAR二维需要估计噪声功率。噪声功率是从假定不包含任何目标信号的单元中计算出来的。这些细胞是培养细胞.训练细胞在待测细胞(CUT)周围形成一个带,但可能被一个保卫带与被切细胞分开。检测阈值的计算方法是将噪声功率乘以阈值因子。
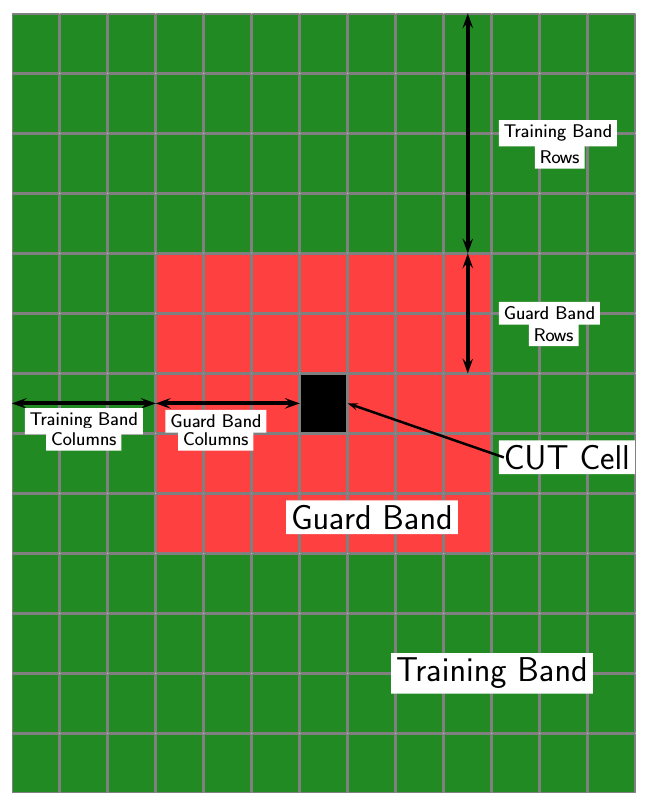
对于GOCA和SOCA平均,噪声功率来自训练单元区域左半部分或右半部分之一的平均值。
因为训练区域中的列数是奇数,中间列中的单元被相等地分配给左或右半部。
使用顺序统计方法时,rank不能大于训练单元区域的单元数,N火车.你可以计算N火车.
NTC为训练频带列的个数。
NTR为训练带行数。
NGC是保护频带列的数量。
NGR是保护带的行数。
联合训练区、保卫区和CUT区细胞的总数为N总计= (2 nTCn + 2GC+ 1) (2 nTRn + 2GR+ 1).
保卫区和CUT细胞合并后的细胞总数为N警卫= (2 nGC+ 1) (2 nGR+ 1).
训练单元的数量是N火车= N总计–N警卫.
通过构造,训练单元的数量总是偶数。因此,要实现中值过滤器,可以选择一个秩N火车/2或N火车/ 2 + 1.
你也可以从以下列表中选择一个网站:
