clusterDBSCAN.discoverClusters
语法
描述
(返回一个cluster-ordered点列表,订单,reachdist)= clusterDBSCAN.discoverClusters (X,maxepsilon,minnumpoints)订单距离可达性,reachdist每个点的数据X。指定最大ε,maxepsilon最小数量的点,minnumpoints。该方法实现了订购点识别集群结构(光学)算法。光学算法是有用的,当集群有不同的密度。
clusterDBSCAN.discoverClusters (显示一个条形图表示集群的层次结构。X,maxepsilon,minnumpoints)
例子
显示集群层次结构
创建目标数据的随机检测xy笛卡儿坐标。使用clusterDBSCAN.discoverClusters对象函数揭示底层集群的层次结构。
首先,设置clusterDBSCAN.discoverClusters参数。
maxEpsilon = 10;minNumPoints = 6;
创建随机目标数据。
2 X = [randn(20日)+ (11.5,11.5);randn (20, 2) + (25、15);randn (20, 2) + (8、20);兰德(10 * 10,2)+ [20、20]];情节(X (: 1) X (:, 2),“。”)轴平等的网格
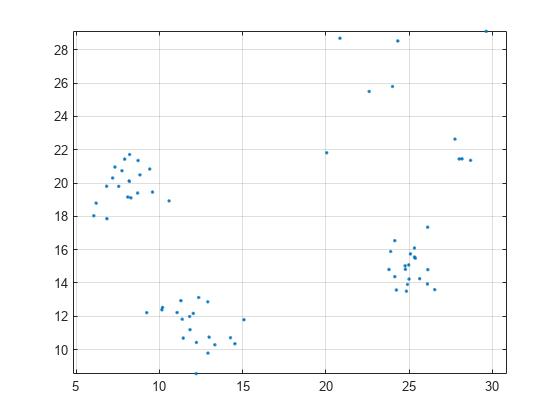
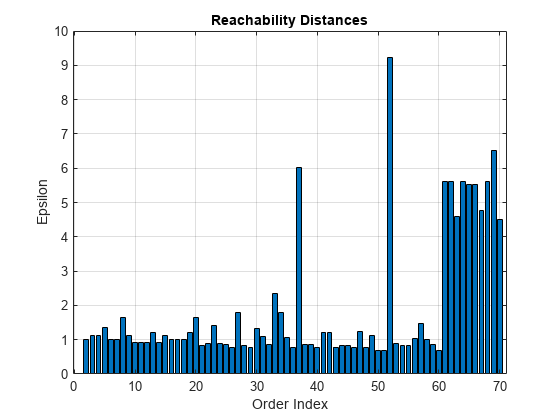
情节集群的层次结构。
clusterDBSCAN.discoverClusters (X, maxEpsilon minNumPoints)
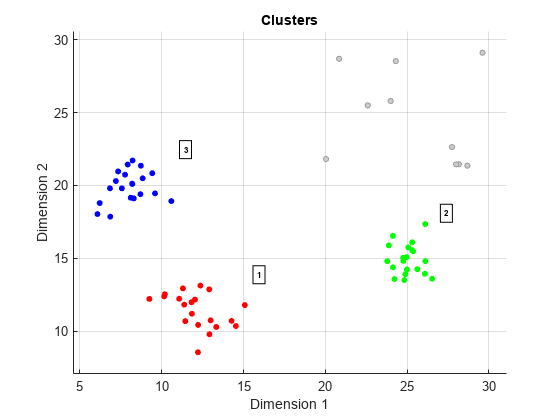
从情节的目视检查,选择ε2,然后执行集群使用clusterDBSCAN对象和情节的集群。
clusterer运算= clusterDBSCAN (“MinNumPoints”6‘ε’2,…“EnableDisambiguation”、假);[idx, cidx] clusterer运算(X) =;情节(clusterer运算,X, idx)
输入参数
输出参数
算法
的输出clusterDBSCAN.discoverClusters让你创建一个reachability-plot集群的层次结构可以可视化。reachability-plot包含命令点x设在和可达性的距离y设在。使用输出检查集群结构在一个广泛的参数设置。您可以使用输出帮助评估适当的εDBSCAN算法的聚类阈值。属于集群有小点可达性最近邻距离,和集群作为山谷出现在可达性的情节。更深层次的山谷对应密集的集群。确定纵坐标的ε山谷的底部。
光学假定密集的集群是完全包含集群密度较低。光学过程跟踪以正确的顺序的数据点密度社区。这个过程是由订购数据点的最短可达性的距离,保证集群密度较高的识别。
扩展功能
版本历史
介绍了R2021a