火车定制LQR代理
此示例显示如何训练自定义线性二次调节(LQR)代理以控制在MATLAB®中建模的离散时间线性系统。
创建线性系统环境
本例的强化学习环境是一个离散时间线性系统。给出了系统的动力学方程
反馈控制法是
控制目标是使二次成本最小化: 。
在这个例子中,系统矩阵是
a = [1.05,0.05,0.05; 0.05,1.05,0.05; 0,0.05,1.05];B = [0.1,0.0.2; 0.1,0.5,0; 0,0,0.5];
二次代价矩阵为:
Q =[10 3 1; 3、5、4、1、4、9];R = 0.5 *眼(3);
对于这样的环境,奖励是适时的 是(谁)给的 ,这是二次成本的负面。因此,最大化奖励最小化成本。初始条件通过复位函数随机设置。
为此线性系统和奖励创建MATLAB环境界面。这mydiscreteenv.函数通过定义自定义来创建环境步和重置功能。有关创建此类自定义环境的更多信息,请参阅使用自定义功能创建MATLAB环境。
env = myDiscreteEnv (A, B, Q, R);
修复随机生成器种子的再现性。
RNG(0)
创建自定义LQR代理
对于LQR问题,Q函数用于给定的控制增益 可以定义为 , 在哪里 是一个对称的正定的矩阵。
控制法最大化 是 ,反馈增益是 。
矩阵 包含 不同元素值,其中 是状态数和输入数的和。表示 作为对应于这些的矢量 元素,其中偏差元素 乘以2。
代表q-function , 在哪里 包含需要学习的参数。
, 在哪里 是二次基础函数 和 。
LQR代理以稳定控制器开头 。要获得初始稳定控制器,请放置闭环系统的极点 在单位圈内。
k0 =地方(a,b,[0.4,0.8,0.5]);
要创建自定义代理,您必须创建一个子类rl.agent.CustomAgent抽象类。对于自定义LQR代理,定义的自定义子类为LQRCustomAgent。有关更多信息,请参阅创建自定义强化学习代理。使用自定义LQR代理使用
那
,
。代理不需要有关系统矩阵的信息
和
。
代理= LQRCustomAgent (Q, R, K0);
对于本例,将代理折扣系数设置为1。若要使用贴现后的未来回报,请将贴现因子设为小于1的值。
Agent.gamma = 1;
因为线性系统有三个状态和三个输入,所以学习参数的总数是 。为确保代理的令人满意的性能,请设置参数估计数 要大于学习参数的数量。在此示例中,该值是 。
Agent.ESTIMATENUM = 45;
为得到较好的估计结果 ,您必须对系统应用一个持续兴奋的探索模型。在本例中,通过在控制器输出中添加白噪声来鼓励模型探索: 。通常,探索模型取决于系统模型。
火车代理
要培训代理,首先指定培训选项。对于本示例,请使用以下选项。
每次训练最多进行一次
10.剧集,每一集最多持久50.时间步骤。显示命令行显示(设置
详细的选项),并在“章节管理器”对话框中禁用培训进度(将绘图选项)。
有关更多信息,请参阅rlTrainingOptions。
trainingopts = rltringoptions(......“MaxEpisodes”10,......“MaxStepsPerEpisode”, 50岁,......'verbose',真的,......'plots'那'没有任何');
训练代理人使用火车功能。
Trainstats =火车(代理,ENV,Trainpepopts);
插曲:1/10 |集奖励:-55.16 |集步骤:50 |平均奖励:-55.16 |步骤数:50集:2/10 |集奖赏:-12.52 |集步骤:50 |平均奖励:-33.84 |步骤数:100集:3/10 |集奖赏:-15.59 |集步骤:50 |平均奖励:-27.76 |步骤数:150集:4/10 |集奖赏:50 | -22.22 |集步骤:平均奖励:-26.37 |步骤数:200集:5/10 |集奖赏:-14.32 |集步骤:50 |平均奖励:-23.96 |步骤数:250集:6/10 |集奖赏:-19.23 |集步骤:50 |平均奖励:-16.78 |步骤数:300集:7/10 |集奖赏:-34.14 |集步骤:50 |平均奖励:-21.10 |步骤数:350集:8/10 |集奖赏:-13.95 |集步骤:50 |平均奖励:-20.77 |步骤数:400集:9/10 |集奖赏:-36.01 |集步骤:50 |平均奖励:-23.53 |步骤数:450集:10/10 |集奖赏:-12.43 |集步骤:50 |平均奖励:步数:500
模拟Agent并与最优解进行比较
要验证培训的代理的性能,请在MATLAB环境中模拟它。有关代理模拟的更多信息,请参阅rlSimulationOptions和SIM。
simOptions = rlSimulationOptions (“MaxSteps”20);体验= SIM(ENV,Agent,SimOptions);TotalReward = Sum(经验.Rward)
totalReward = -20.1306
您可以使用使用的LQR问题来计算最佳解决方案DLQR.功能。
[KOPTIMAL,P] = DLQR(A,B,Q,R);
最佳奖励是给出的 。
x0 = experience.Observation.obs1.getdatasamples (1);Joptimal = x0 ' * P * x0;
计算训练的LQR代理和最佳LQR解决方案之间的奖励中的错误。
RegiseError = TotalRreward - Joptimal
RemantionError = 1.5270E-06
查看培训的LQR代理和最佳LQR解决方案之间的增益中的2-Norm的历史记录。
%增益更新数量len =代理.Kupdate;err = zeros(len,1);为了我= 1:len增益中的错误数量犯错(i) =规范(agent.KBuffer{我}-Koptimal);结尾情节(错误,'b * - ')
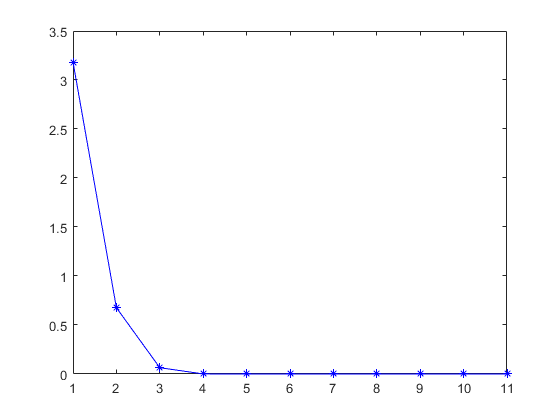
计算反馈增益的最终误差范数。
GaInerRor = Norm(Agent.k - Koptimal)
gainError = 2.2458 e-11
总的来说,经过训练的agent找到了一个接近于真实最优LQR解的LQR解。
也可以看看
相关的话题
你也可以从以下列表中选择一个网站: