主要内容
加速与GPU的相关性
此示例显示如何使用GPU加速互相关。许多相关问题涉及大数据集,可以使用GPU更快地解决。此示例需要并行计算工具箱™用户许可证。参考GPU通万博1manbetx过发布支持(并行计算工具箱)查看支持哪些gpu。万博1manbetx
介绍
首先学习有关机器中GPU的一些基本信息。要访问GPU,请使用“并行计算”工具箱。
流('基准GPU加速的互相关。\ n');如果〜(parallel.gpu.gpudevice.isavailable)fprintf([' \ n \ t * * GPU不可用。停止。* * \ n”]);返回;别的dev=gpuDevice;fprintf(...'检测到GPU(%s,%d个多处理器,计算能力%s)',...dev.name,dev.multiprocessorcount,dev.compteapability;结尾
基于GPU加速的互相关。检测到GPU(Titan XP,30个多处理器,计算能力6.1)
基准功能
因为为CPU编写的代码可以移植到GPU上运行,所以可以使用一个函数对CPU和GPU进行基准测试。但是,由于GPU上的代码是从CPU异步执行的,所以在测量性能时应该采取特别的预防措施。在测量执行一个函数所花费的时间之前,通过在设备上执行“等待”方法,确保所有的GPU处理已经完成。这个额外的调用对CPU性能没有影响。
这个例子对三种不同类型的相互关系进行了基准测试。
基准简单的互相关
对于第一种情况,两个大小相等的向量使用语法相互关联Xcorr(U,V).CPU执行时间与GPU执行时间的比率绘制针对向量的大小绘制。
流('\n\n ***基准矢量-矢量互相关*** \n\n');流('基准函数:\ n');类型('benchxcorrvec');流(“\n\n”); 尺寸=[2000 1e4 1e5 5e5 1e6];tc=零(1,单位(尺寸));tg=零(1,单位(尺寸));numruns=10;为了s = 1:磁数(尺寸);流('运行%d元素的xcorr ... \ n',尺寸);delchar = repmat(“\b”,1,numruns);a=兰特(尺寸,1);b=兰特(尺寸,1);tc(s)=benchXcorrVec(a,b,numruns);fprintf([delcharcpu时间:%。2 f \ n '女士],1000 * Tc(s));TG(s)= BenchxcorRvec(GPUARRAY(A),GPUARRAY(B),NUMRUNs);流([delchar'\ t \ tgpu time:%.2f ms \ n'],1000 * Tg(s));结尾%绘制结果图=图;轴=轴('父母', 无花果);semilogx(斧头,大小,tc./tg,“r * - - - - - -”);ylabel (ax,“加速”);xlabel(斧头,'矢量大小');标题(斧头,“XCORR的GPU加速”);drawnow;
***基准测试矢量 - 矢量 - 矢量互联***基准函数:功能T = BenchxcorRVEC(U,V,NumRuns)%用于基于CPU和GPU的向量输入的XCorr。% Copyright 2012 The MathWorks, Inc. timevec = zeros(1,numruns);gdev = gpuDevice;对于II = 1:numruns ts = tic;o = Xcorr(U,V);%#okwait(gdev) timevec(ii) = toc(ts);流('。');End t = min(timevec);结束2000元素的XCorr ... CPU时间:0.21 MS GPU时间:4.26 MS运行10000元素的XCorr ... CPU时间:1.03 MS GPU时间:4.37 MS运行100000元素的XCorr ... CPU时间:14.04毫秒GPU时间:6.28 MS运行XCorr为500000元素... CPU时间:55.98 MS GPU时间:16.09 MS运行1000000元素的XCorr ... CPU时间:169.00 MS GPU时间:25.60毫秒

基准矩阵柱互相关
对于第二种情况,矩阵A的列被成对交叉相关,以使用语法XCorr(A)产生所有相关的大矩阵输出。CPU执行时间与GPU执行时间的比率绘制矩阵A的大小。
流('\ n \ n ***基准矩阵列柱互联*** \ n \ n');流('基准函数:\ n');类型('benchxcorrmatrix');流(“\n\n”);尺寸=地板(Linspace(0,100,11));大小(1)= [];tc = 0(1,元素个数(大小));tg = 0(1,元素个数(大小));numruns = 10;为了s = 1:磁数(尺寸);流('运行Xcorr(矩阵)%d x%d矩阵... \ n',尺寸,尺寸);delchar = repmat(“\b”1、numruns);一个=兰德(大小(s));tc(s) = benchXcorrMatrix(a, numruns);流([delcharcpu时间:%。2 f \ n '女士],1000 * Tc(s));TG(s)= Benchxcorrmatrix(GPUArray(A),NumRuns);流([delchar'\ t \ tgpu time:%.2f ms \ n'],1000 * Tg(s));结尾%绘制结果图=图;轴=轴('父母',图);绘图(最大,尺寸^2,tc./tg,“r * - - - - - -”);ylabel (ax,“加速”);xlabel(斧头,矩阵元素的);标题(斧头,'GPU加速XCorr(矩阵)');drawnow;
***基准矩阵列互相关***基准函数:function t = benchXcorrMatrix(A, numruns) %用于在CPU和GPU上对输入矩阵的xcorr进行基准测试。% Copyright 2012 The MathWorks, Inc. timevec = zeros(1,numruns);gdev = gpuDevice;For ii=1:numruns, ts = tic;o = xcorr(一个);%#okwait(gdev) timevec(ii) = toc(ts);流('。');End t = min(timevec);end运行10 × 10矩阵的xcorr (matrix)…CPU时间:0.18 ms GPU时间:5.00 ms运行xcorr (matrix)的20 × 20矩阵… CPU time : 0.48 ms GPU time : 4.83 ms Running xcorr (matrix) of a 30 x 30 matrix... CPU time : 0.85 ms GPU time : 4.84 ms Running xcorr (matrix) of a 40 x 40 matrix... CPU time : 3.38 ms GPU time : 5.57 ms Running xcorr (matrix) of a 50 x 50 matrix... CPU time : 5.60 ms GPU time : 5.22 ms Running xcorr (matrix) of a 60 x 60 matrix... CPU time : 8.49 ms GPU time : 5.39 ms Running xcorr (matrix) of a 70 x 70 matrix... CPU time : 20.43 ms GPU time : 5.92 ms Running xcorr (matrix) of a 80 x 80 matrix... CPU time : 26.79 ms GPU time : 6.24 ms Running xcorr (matrix) of a 90 x 90 matrix... CPU time : 40.04 ms GPU time : 6.89 ms Running xcorr (matrix) of a 100 x 100 matrix... CPU time : 49.69 ms GPU time : 7.32 ms

基准测试的二维互相关
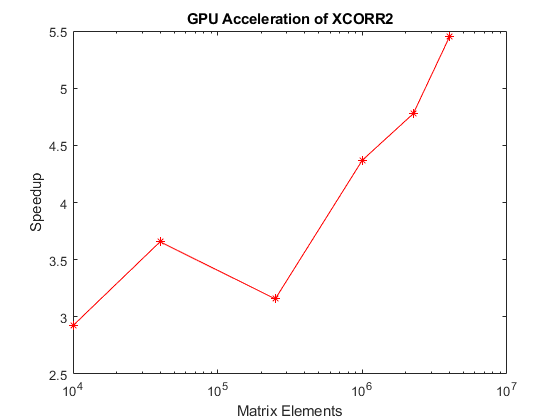
对于最终情况,两个矩阵,x和y,使用XcorR2(x,y)交叉相关。x允许y固定,而允许变化。加速度符合第二矩阵的大小。
流(“\n\n***基准二维互相关***\n\n”);流('基准函数:\ n');类型(“benchXcorr2”);流(“\n\n”);尺寸= [100,200,500,1000,1500,2000];tc = 0(1,元素个数(大小));tg = 0(1,元素个数(大小));numruns = 4;一个=兰德(100);为了s = 1:磁数(尺寸);流('运行100x100矩阵的Xcorr2和%d x%d矩阵... \ n',尺寸,尺寸);delchar = repmat(“\b”1、numruns);B =兰特(大小);tc(s)= benchxcorr2(a,b,numruns);流([delcharcpu时间:%。2 f \ n '女士],1000 * Tc(s));Tg(s)= Benchxcorr2(GPUARRAY(A),GPUARRAY(B),NUMRUNs);流([delchar'\ t \ tgpu time:%.2f ms \ n'],1000 * Tg(s));结尾%绘制结果图=图;斧头=轴('父母', 无花果);Semilogx(斧头,大小。^ 2,Tc./tg,“r * - - - - - -”);ylabel (ax,“加速”);xlabel(斧头,矩阵元素的);标题(斧头,“XCORR2 GPU加速”);drawnow;流('\ n \ nbenchmarking完成了。\ n \ n');
***基准2d互相关***基准功能:function t = benchXcorr2(X, Y, numruns) %用于在CPU和GPU上对xcorr2进行基准测试。% Copyright 2012 The MathWorks, Inc. timevec = zeros(1,numruns);gdev = gpuDevice;For ii=1:numruns, ts = tic;o = xcorr2 (X, Y);%#okwait(gdev) timevec(ii) = toc(ts);流('。');End t = min(timevec);运行100x100矩阵和100x100矩阵的xcorr2…CPU时间:20.35 ms GPU时间:6.96 ms运行xcorr2的100 × 100矩阵和200 × 200矩阵… CPU time : 42.87 ms GPU time : 11.72 ms Running xcorr2 of a 100x100 matrix and 500 x 500 matrix... CPU time : 125.23 ms GPU time : 39.67 ms Running xcorr2 of a 100x100 matrix and 1000 x 1000 matrix... CPU time : 386.59 ms GPU time : 88.46 ms Running xcorr2 of a 100x100 matrix and 1500 x 1500 matrix... CPU time : 788.38 ms GPU time : 165.04 ms Running xcorr2 of a 100x100 matrix and 2000 x 2000 matrix... CPU time : 1523.05 ms GPU time : 279.55 ms Benchmarking completed.
其他GPU加速信号处理功能
GPU上还可以运行其他几个信号处理功能。这些函数包括fft、ifft、conv、filter、fftfilt等。在某些情况下,您可以实现相对于CPU的较大加速。有关GPU加速信号处理功能的完整列表,请参阅GPU算法加速“信号处理工具箱”文档中的章节。
另请参阅
您还可以从以下列表中选择一个网站:
