主要内容
countlabels.
数量唯一标签数
描述
在进行机器或深度学习分类问题时,请使用此功能,并希望查看数据集中的标签值的比例。
例子
数组中的标签
分类阵列
使用类别生成一个分类数组一种那B.那C, 和D.。阵列包含每个类别的样本。
lbls =分类([“b”“C”“一种”“D”“b”“一种”“一种”“b”“C”“一种”],......[“一种”“b”“C”“D”])
lbls =1x10分类b c a d b a a b c a
计算数组中唯一标签类别值的数量。
cnt = countlabels(lbls)
cnt =4×3表标签计数百分比_____ _____ ________________________________________________________ a 4 40 b 3 30 c 2 20 d 1 10
使用相同类别生成第二个分类数组。该阵列包含每个类别的样本和一个具有缺失值的样本。
mlbls = pattorical([“b”“C”“一种”“D”“b”“一种”丢失的“b”“C”“一种”],......[“一种”“b”“C”“D”])
mlbls =.1x10分类列1至9b c a d b a <未定义> b c列10a
计算数组中唯一标签类别值的数量。缺失值的样本包括在计数中<未定义>。
MCNT = COUNTLABELS(MLBLS)
mcnt =5×3表标签计数百分比___________ _____________________________________________________ unefined> 1 10
字符阵列
阅读William Shakespeare的SonnetsFileread.功能。从文本中删除所有Nonalphabetic字符并将其转换为小写。
Sonnets = fileread(“sonnets.txt”);字母=较低(SONNET(Regexp(Sonnet),“[A-Z]”)))';
计算每个字母出现在SONNET中的次数。列出最常显示的字母。
cnt = countlabels(字母);cnt = sortrows(cnt,“数数”那“descend”);头(CNT)
ans =.8×3表标记数百分比_____ _____ _________ e 9028 12.298 T 7210 9.8216 o 5710 7.7782 H 5064 6.8982 S 4994 6.8982 494 6.8982 494 6.7293 I 4895 6.668 N 4522 6.1599
数字阵列
使用鲈鱼功能从泊松分布生成1000个随机整数的阵列3.绘制结果的直方图。
n = 1000;林= 3;nums = zeros(n,1);为了JK = 1:n NUMS(JK)= POISRAND(LAM);结尾直方图(NUMS)
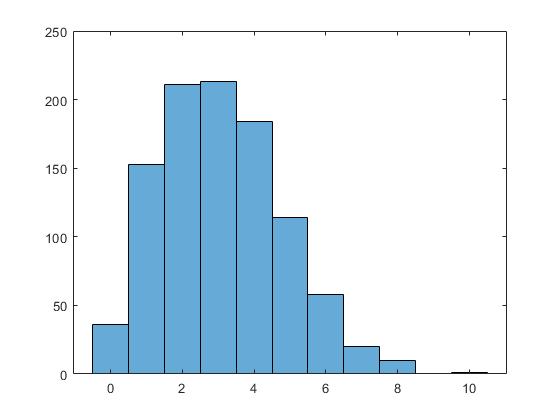
计算数组中表示的整数的频率。
mm = countlabels(nums)
mm =10×3表标签计数百分比_____ _____ _______ 0 36 3.6 1 153 15.3 10 1 0.1 2 211 21.1 3 213 21.3 4 184 18.4 5 114 11.4 6 58 5.8 7 20 2 8 10 1
功能num = poisrand(lam)%泊松随机整数使用抑制方法p = 0;num = -1;尽管p <= lam p = p - log(rand);num = num + 1;结尾结尾
计数表和数据存储中的标签
使用两个变量创建一个字符表。第一个变量type1.包含字母的实例P.那问:, 和R.。第二个变量Type2.包含字母的实例一种那B., 和D.。
tbl = table([“P”“r”“P”“q”“q”“q”“r”“P”]',......[“一种”“b”“b”“一种”“D”“D”“一种”“一种”]',......'variablenames',[“type1”那“type2”]);
计算每个表变量中每个字母出现的次数。
cnt = countlabels(tbl,'tablevariable'那'type1')
cnt =3×3表Type1计数百分比_____ _____ _______ p 3 37.5 q 3 37.5 r 2 25
cnt = countlabels(tbl,'tablevariable'那'type2')
cnt =3×3表Type2计数百分比_____ ____________________________________________________________________
创建一个A.rraydatastore.包含该表的对象。
广告= ArrayDataStore(TBL,'OutputType'那'相同的');
计算每个表变量中每个字母出现的次数。
cnt = countlabels(广告,'tablevariable'那'type1')
cnt =3×3表Type1计数百分比_____ _____ _______ p 3 37.5 q 3 37.5 r 2 25
cnt = countlabels(广告,'tablevariable'那'type2')
cnt =3×3表Type2计数百分比_____ ____________________________________________________________________
输入参数
输出参数
在R2021A介绍
您还可以从以下列表中选择一个网站:
