kfoldEdgegydF4y2Ba
用于观察的分类边缘不用于培训gydF4y2Ba
描述gydF4y2Ba
egydF4y2Ba= kfoldEdge (gydF4y2Bacvmdl.gydF4y2Ba)gydF4y2Bacvmdl.gydF4y2Ba.也就是说,对于每一个折叠,gydF4y2BakfoldEdgegydF4y2Ba估计分类边缘,以便在使用所有其他观察时培训它时它坚持下去。gydF4y2Ba
egydF4y2Ba包含的线性分类模型中的每个正则化强度的分类边gydF4y2Bacvmdl.gydF4y2Ba.gydF4y2Ba
egydF4y2Ba= kfoldEdge (gydF4y2Bacvmdl.gydF4y2Ba,gydF4y2Ba名称,值gydF4y2Ba)gydF4y2Ba名称,值gydF4y2Ba对参数。例如,指定一个解码方案,用于边缘计算的折叠或冗长级别。gydF4y2Ba
输入参数gydF4y2Ba
输出参数gydF4y2Ba
例子gydF4y2Ba
估计gydF4y2BakgydF4y2Ba- 折叠交叉验证边缘gydF4y2Ba
加载NLP数据集。gydF4y2Ba
负载gydF4y2BanlpdatagydF4y2Ba
XgydF4y2Ba是预测器数据的稀疏矩阵,以及gydF4y2BaYgydF4y2Ba是类标签的分类矢量。gydF4y2Ba
为简单起见,在所有的观察中使用“其他”标签gydF4y2BaYgydF4y2Ba那不是gydF4y2Ba'万博1manbetxsimulink'gydF4y2Ba,gydF4y2Ba'DSP'gydF4y2Ba, 要么gydF4y2Ba'comm'gydF4y2Ba.gydF4y2Ba
y(〜(ismember(y,{gydF4y2Ba'万博1manbetxsimulink'gydF4y2Ba,gydF4y2Ba'DSP'gydF4y2Ba,gydF4y2Ba'comm'gydF4y2Ba}))) =gydF4y2Ba'其他'gydF4y2Ba;gydF4y2Ba
交叉验证一个多类线性分类模型。gydF4y2Ba
rng (1);gydF4y2Ba重复性的%gydF4y2Bacvmdl = fitcecoc(x,y,gydF4y2Ba'学习者'gydF4y2Ba,gydF4y2Ba'线性'gydF4y2Ba,gydF4y2Ba“CrossVal”gydF4y2Ba,gydF4y2Ba“上”gydF4y2Ba);gydF4y2Ba
cvmdl.gydF4y2Ba是A.gydF4y2BaClassificationedAdearecoc.gydF4y2Ba模型。默认情况下,软件实现10倍交叉验证。您可以使用使用的折叠数gydF4y2Ba'kfold'gydF4y2Ba名称-值对的论点。gydF4y2Ba
估计出折叠边的平均值。gydF4y2Ba
e = kfoldedge(cvmdl)gydF4y2Ba
E = 0.7232.gydF4y2Ba
或者,您可以通过指定名称值对获取每个折叠边缘gydF4y2Ba“模式”,“个人”gydF4y2Ba在gydF4y2BakfoldEdgegydF4y2Ba.gydF4y2Ba
功能选择使用gydF4y2BakgydF4y2Ba倍的边缘gydF4y2Ba
进行特征选择的一种方法是进行比较gydF4y2BakgydF4y2Ba- 来自多种模型的边缘。仅基于此标准,具有最高边缘的分类器是最佳分类器。gydF4y2Ba
加载NLP数据集。预处理数据,如gydF4y2Ba估计k折交叉验证边gydF4y2Ba,并对预测器数据进行定位,使观察结果与列相对应。gydF4y2Ba
负载gydF4y2BanlpdatagydF4y2Bay(〜(ismember(y,{gydF4y2Ba'万博1manbetxsimulink'gydF4y2Ba,gydF4y2Ba'DSP'gydF4y2Ba,gydF4y2Ba'comm'gydF4y2Ba}))) =gydF4y2Ba'其他'gydF4y2Ba;X = X ';gydF4y2Ba
创建以下两个数据集:gydF4y2Ba
ullx.gydF4y2Ba包含所有预测。gydF4y2BapartXgydF4y2Ba包含随机选择的1/2的预测器。gydF4y2Ba
rng (1);gydF4y2Ba重复性的%gydF4y2Bap =尺寸(x,1);gydF4y2Ba%预测器数量gydF4y2BahalfPredIdx = randsample (p,装天花板(0.5 * p));fullX = X;partX = X (halfPredIdx:);gydF4y2Ba
创建一个线性分类模型模板,指定使用SpaRSA优化目标函数。gydF4y2Ba
t = templateLinear (gydF4y2Ba'求解'gydF4y2Ba,gydF4y2Ba“sparsa”gydF4y2Ba);gydF4y2Ba
交叉验证由二元线性分类模型组成的两个ECOC模型:一个使用所有预测器,另一个使用一半预测器。表示观察结果对应于列。gydF4y2Ba
cvmdl = fitcecoc(fullx,y,gydF4y2Ba“学习者”gydF4y2Ba,t,gydF4y2Ba“CrossVal”gydF4y2Ba,gydF4y2Ba“上”gydF4y2Ba,gydF4y2Ba......gydF4y2Ba“ObservationsIn”gydF4y2Ba,gydF4y2Ba“列”gydF4y2Ba);pcvmdl = fitcecoc(partx,y,gydF4y2Ba“学习者”gydF4y2Ba,t,gydF4y2Ba“CrossVal”gydF4y2Ba,gydF4y2Ba“上”gydF4y2Ba,gydF4y2Ba......gydF4y2Ba“ObservationsIn”gydF4y2Ba,gydF4y2Ba“列”gydF4y2Ba);gydF4y2Ba
cvmdl.gydF4y2Ba和gydF4y2BaPCVMDL.gydF4y2Ba是gydF4y2BaClassificationedAdearecoc.gydF4y2Ba楷模。gydF4y2Ba
估计gydF4y2BakgydF4y2Ba- 每个分类器的折叠边缘。gydF4y2Ba
FultEdge = KfoldEdge(CVMDL)gydF4y2Ba
fullEdge = 0.3090gydF4y2Ba
partEdge = kfoldEdge (PCVMdl)gydF4y2Ba
partEdge = 0.2617gydF4y2Ba
基于这一点gydF4y2BakgydF4y2Ba-fold edges,使用所有预测器的分类器是更好的模型。gydF4y2Ba
找到好的套索惩罚使用方法gydF4y2BakgydF4y2Ba- 折叠边缘gydF4y2Ba
为了确定使用逻辑回归学习者的线性分类模型的良好租赁强度,比较K折边缘。gydF4y2Ba
加载NLP数据集。预处理数据,如gydF4y2Ba使用k折边进行特征选择gydF4y2Ba.gydF4y2Ba
负载gydF4y2BanlpdatagydF4y2Bay(〜(ismember(y,{gydF4y2Ba'万博1manbetxsimulink'gydF4y2Ba,gydF4y2Ba'DSP'gydF4y2Ba,gydF4y2Ba'comm'gydF4y2Ba}))) =gydF4y2Ba'其他'gydF4y2Ba;X = X ';gydF4y2Ba
创建一组8个对数间隔的正则化强度gydF4y2Ba 通过gydF4y2Ba .gydF4y2Ba
λ= logspace (8 1 8);gydF4y2Ba
创建一个线性分类模型模板,指定使用Lasso惩罚的Logistic回归,使用每个正则化强度,使用Sparsa优化目标函数,并降低目标函数梯度的容差gydF4y2Ba1E-8gydF4y2Ba.gydF4y2Ba
t = templateLinear (gydF4y2Ba'学习者'gydF4y2Ba,gydF4y2Ba“物流”gydF4y2Ba,gydF4y2Ba'求解'gydF4y2Ba,gydF4y2Ba“sparsa”gydF4y2Ba,gydF4y2Ba......gydF4y2Ba“正规化”gydF4y2Ba,gydF4y2Ba“套索”gydF4y2Ba,gydF4y2Ba“λ”gydF4y2Ba,lambda,gydF4y2Ba“GradientTolerance”gydF4y2Ba1 e-8);gydF4y2Ba
交叉验证一个由二元、线性分类模型组成的ECOC模型,使用5倍交叉验证gydF4y2Ba
RNG(10)gydF4y2Ba重复性的%gydF4y2Bacvmdl = fitcecoc(x,y,gydF4y2Ba“学习者”gydF4y2Ba,t,gydF4y2Ba“ObservationsIn”gydF4y2Ba,gydF4y2Ba“列”gydF4y2Ba,gydF4y2Ba'kfold'gydF4y2Ba5)gydF4y2Ba
CVMdl = ClassificationPartitionedLinearECOC CrossValidatedModel: 'LinearECOC' ResponseName: 'Y' NumObservations: 31572 KFold: 5 Partition: [1x1 cvpartition] ClassNames: [comm dsp 万博1manbetxsimulink others] ScoreTransform: 'none'属性,方法gydF4y2Ba
cvmdl.gydF4y2Ba是A.gydF4y2BaClassificationedAdearecoc.gydF4y2Ba模型。gydF4y2Ba
估计每个折叠的边缘和正则化强度。gydF4y2Ba
eFolds = kfoldEdge (CVMdl,gydF4y2Ba“模式”gydF4y2Ba,gydF4y2Ba“个人”gydF4y2Ba)gydF4y2Ba
efolds =gydF4y2Ba5×8gydF4y2Ba0.5553 0.5555 0.5556 0.5544 0.4957 0.2938 0.1044 0.0853 0.5301 0.5306 0.5306 0.5310 0.4826 0.2944 0.1049 0.0868 0.5278 0.5284 0.5293 0.5290 0.4764 0.2906 0.1039 0.0867 0.5387 0.5398 0.5408 0.5377 0.4844 0.2897 0.1016 0.0857 0.5509 0.5569 0.5571 0.5568 0.4951 0.2938 0.1032 0.0850gydF4y2Ba
efolds.gydF4y2Ba是一个5×8的边缘矩阵。行对应于折叠,列对应于正则化强度gydF4y2BaλgydF4y2Ba.您可以使用gydF4y2Baefolds.gydF4y2Ba识别不良折叠,即异常低的边缘。gydF4y2Ba
为每个正则化强度估算所有折叠的平均边缘。gydF4y2Ba
e = kfoldedge(cvmdl)gydF4y2Ba
E =gydF4y2Ba1×8gydF4y2Ba0.5406 0.5422 0.5427 0.5418 0.4868 0.2924 0.1036 0.0859gydF4y2Ba
确定模型通过绘制每个正则化强度的5倍边缘的平均值的概括。确定最大化电网上的5倍边缘的正则化强度。gydF4y2Ba
图绘图(log10(lambda),log10(e),gydF4y2Ba“o”gydF4y2Ba) [~, maxEIdx] = max(e);maxLambda =λ(maxEIdx);持有gydF4y2Ba在gydF4y2Ba情节(log10 (maxLambda) log10 (e (maxEIdx)),gydF4y2Ba“罗”gydF4y2Ba)ylabel(gydF4y2Ba'log_ {10} 5折边缘'gydF4y2Ba)Xlabel(gydF4y2Ba“log_{10}λ的gydF4y2Ba) 传奇(gydF4y2Ba“边缘”gydF4y2Ba,gydF4y2Ba的最大优势gydF4y2Ba) 抓住gydF4y2Ba离开gydF4y2Ba
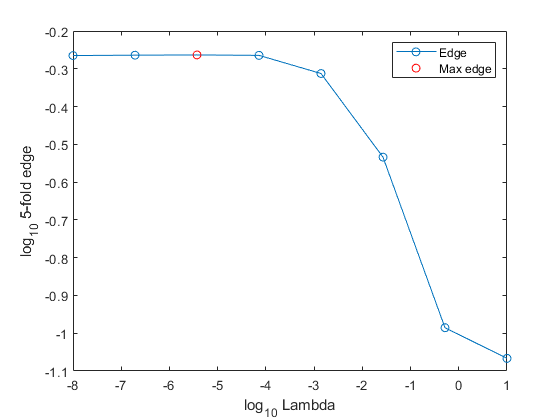
数的值gydF4y2BaλgydF4y2Ba产生类似的高边缘。更大的正则化强度值导致预测器可变稀疏性,这是一个良好的分类器质量。gydF4y2Ba
选择正常发生在边缘开始递减之前的正常化强度。gydF4y2Ba
lambdafinal = lambda(4);gydF4y2Ba
使用整个数据集培训由线性分类模型组成的ecoc模型,并指定正则化强度gydF4y2Balambdafinal.gydF4y2Ba.gydF4y2Ba
t = templateLinear (gydF4y2Ba'学习者'gydF4y2Ba,gydF4y2Ba“物流”gydF4y2Ba,gydF4y2Ba'求解'gydF4y2Ba,gydF4y2Ba“sparsa”gydF4y2Ba,gydF4y2Ba......gydF4y2Ba“正规化”gydF4y2Ba,gydF4y2Ba“套索”gydF4y2Ba,gydF4y2Ba“λ”gydF4y2Ba,lambdafinal,gydF4y2Ba“GradientTolerance”gydF4y2Ba1 e-8);MdlFinal = fitcecoc (X, Y,gydF4y2Ba“学习者”gydF4y2Ba,t,gydF4y2Ba“ObservationsIn”gydF4y2Ba,gydF4y2Ba“列”gydF4y2Ba);gydF4y2Ba
估算新观察的标签,通过gydF4y2Bamdlfinal.gydF4y2Ba和新数据到gydF4y2Ba预测gydF4y2Ba.gydF4y2Ba
更多关于gydF4y2Ba
参考文献gydF4y2Ba
艾尔温,E.夏皮尔,Y.辛格。《将多类减少为二进制:一种统一的保证金分类方法》。gydF4y2Ba机器学习研究杂志gydF4y2Ba.卷。1,2000,pp。113-141。gydF4y2Ba
Pujol, S. Escalera, S. O. Pujol, P. Radeva。《论三元纠错输出码的译码过程》。gydF4y2Ba模式分析与机器智能学报gydF4y2Ba.卷。32,第7号,2010年第70页,第120-134页。gydF4y2Ba
[3] Escalera,S.,O. Pujol和P. Radeva。“用于纠错输出代码稀疏设计的三元代码的可分离。”gydF4y2Ba模式RecogngydF4y2Ba.2009年第30卷第3期285-297页。gydF4y2Ba
扩展能力gydF4y2Ba
另请参阅gydF4y2Ba
ClassificationECOCgydF4y2Ba|gydF4y2Ba分类线性gydF4y2Ba|gydF4y2BaClassificationedAdearecoc.gydF4y2Ba|gydF4y2Ba边缘gydF4y2Ba|gydF4y2Bafitcecoc.gydF4y2Ba|gydF4y2BakfoldMargingydF4y2Ba|gydF4y2BaKfoldpredictgydF4y2Ba|gydF4y2Ba实例化gydF4y2Ba
选择一个网站gydF4y2Ba
选择一个网站,以便在可用的地方进行翻译的内容,并查看本地活动和优惠。根据您的位置,我们建议您选择:gydF4y2Ba.gydF4y2Ba
选择gydF4y2Ba网站gydF4y2Ba您还可以从以下列表中选择一个网站:gydF4y2Ba
美洲gydF4y2Ba
- 美国拉丁gydF4y2Ba(Español)gydF4y2Ba
- 加拿大gydF4y2Ba(英语)gydF4y2Ba
- 美国gydF4y2Ba(英语)gydF4y2Ba
欧洲gydF4y2Ba
- 比利时gydF4y2Ba(英语)gydF4y2Ba
- 丹麦gydF4y2Ba(英语)gydF4y2Ba
- 德意志gydF4y2Ba(德意志)gydF4y2Ba
- 西班牙gydF4y2Ba(Español)gydF4y2Ba
- 芬兰gydF4y2Ba(英语)gydF4y2Ba
- 法国gydF4y2Ba(法语)gydF4y2Ba
- 爱尔兰gydF4y2Ba(英语)gydF4y2Ba
- 意大利gydF4y2Ba(意大利语)gydF4y2Ba
- 卢森堡gydF4y2Ba(英语)gydF4y2Ba
- 荷兰gydF4y2Ba(英语)gydF4y2Ba
- 挪威gydF4y2Ba(英语)gydF4y2Ba
- 奥地利gydF4y2Ba(德意志)gydF4y2Ba
- 葡萄牙gydF4y2Ba(英语)gydF4y2Ba
- 瑞典gydF4y2Ba(英语)gydF4y2Ba
- 瑞士gydF4y2Ba
- 英国gydF4y2Ba(英语)gydF4y2Ba
亚太地区gydF4y2Ba
- 澳大利亚gydF4y2Ba(英语)gydF4y2Ba
- 印度gydF4y2Ba(英语)gydF4y2Ba
- 新西兰gydF4y2Ba(英语)gydF4y2Ba
- 中国gydF4y2Ba
- 日本语gydF4y2Ba(日本语)gydF4y2Ba
- 한국gydF4y2Ba(한국어)gydF4y2Ba
