knnsearch
找k使用Searcher对象的最佳邻居
描述
例子
搜索最近的邻居使用KD树和详尽的搜索
knnsearch接受令人疲惫的或者kdtreesearcher.模型对象,用于搜索最近邻居的训练数据到查询数据。一个令人疲惫的模型调用详尽的搜索者算法,以及一个kdtreesearcher.模型定义A.KD树,哪个knnsearch用于搜索最近的邻居。
载入费雪的虹膜数据集。从数据中随机保留5个观察值作为查询数据。
负载渔民rng (1);重复性的%1) n =大小(量;idx = randsample (n, 5);X =量(~ ismember (1: n, idx):);%培训数据y = meas(idx,:);%查询数据
变量量包含4个预测因子。
生长默认的四维KD树。
MdlKDT = KDTreeSearcher (X)
MdlKDT = KDTreeSearcher with properties: BucketSize: 50 Distance: 'euclidean' DistParameter: [] X: [145x4 double]
mdlkdt.是A.kdtreesearcher.模型对象。您可以使用点表示法更改其可写属性。
准备一个详尽的最近邻搜索。
mdles = utifiventsearcher(x)
mdles =具有属性的令人疲劳性研究员:距离:'euclidean'distparameter:[] x:[145x4双]
mdlkdt.是一个令人疲惫的模型对象。它包含选项,例如距离度量,用于查找最近的邻居。
或者,你可以成长一个KD-Tree或准备详尽的最近邻搜索者创造.
搜索对应于每个查询观察的最近邻居索引的培训数据。使用默认设置进行两种类型的搜索。默认情况下,每个查询观察搜索的邻居数量是1.
Idxkdt = knnsearch(mdlkdt,y);Idxes = knnsearch(mdles,y);[IDXKDT IDXES]
ans =.5×217 17 6 6 1 1 89 89 124 124
在这种情况下,搜索结果是相同的。
使用Minkowski距离搜索查询数据的最近邻居
种植KD-Tree最近的邻居搜索器对象通过使用创造函数。将对象和查询数据传递给knnsearch找到的功能k最近的邻居。
载入费雪的虹膜数据集。
负载渔民
从预测器数据随机删除五个虹膜以用作查询集。
rng (1);重复性的%1) n =大小(量;%样本大小qidx = randsample(n,5);%查询数据索引tidx =〜ismember(1:n,qidx);%训练数据指标Q =量(qIdx:);X =量(tIdx:);
长四维KD-Tree使用培训数据。指定Minkowski距离查找最近的邻居。
mdl = createns(x,'距离','minkowski')
Mdl = KDTreeSearcher with properties: BucketSize: 50 Distance: 'minkowski' DistParameter: 2 X: [145x4 double]
因为X有四列,距离度量是minkowski,创造创造一个kdtreesearcher.默认情况下模型对象。Minkowski距离指数是2默认情况下。
找到培训数据的指标(mdl.x.)是查询数据中每个点的两个最近邻居(问)。
idxnn = knnsearch(mdl,q,'K'2)
idxnn =.5×217 4 6 2 1 12 89 66 124 100
每一排idxnn.对应于查询数据观察,并且列顺序对应于相对于升高距离的最近邻居的顺序。例如,基于Minkowski距离,第二个最近的邻居q(3,:)是: X(12日).
在最近邻搜索中包括关系
载入费雪的虹膜数据集。
负载渔民
从预测器数据随机删除五个虹膜以用作查询集。
rng (4);重复性的%1) n =大小(量;%样本大小qidx = randsample(n,5);%查询数据索引X =量(~ ismember (1: n, qIdx):);: Y =量(qIdx);
长四维KD-Tree使用培训数据。指定Minkowski距离查找最近的邻居。
mdl = kdtreesearcher(x);
MDL.是A.kdtreesearcher.模型对象。默认情况下,查找最近邻居的距离度量是欧几里德度量标准。
找到培训数据的指标(X),即查询数据中每个点最近的7个邻居(Y)。
[Idx D] = knnsearch (Mdl Y'K'7“IncludeTies”,真的);
idx.和D是载体的五元素电池阵列,每个载体具有至少七个元素。
显示矢量的长度idx..
cellfun ('长度',IDX)
ans =.5×18 7 7 7 7
因为细胞1包含长度大于的向量k= 7,查询观察1(Y (1:))同样接近至少两个观察X.
显示最近邻居的索引Y (1:)他们的距离。
nn5 = idx {1}
nn5 =1×8.91 98 67 69 71 93 88 95
nn5d = d {1}
nn5d =1×8.0.1414 0.2646 0.2828 0.340 0.3464 0.3742 0.3873 0.3873
培训观察88.和95.距查询观察0.3873厘米1.
相比k使用不同距离指标的最佳邻居
火车二kdtreesearcher.模型使用不同的距离度量,并进行比较k用于两种型号的查询数据的最佳邻居。
载入费雪的虹膜数据集。将花瓣测量视为预测因子。
负载渔民X = MEAS(:,3:4);%预测因子y =物种;% 回复
训练kdtreesearcher.使用预测器模型对象。用指数5指定Minkowski距离。
KDTreeMdl = KDTreeSearcher (X,'距离','minkowski',“P”5)
KDTReeMDL = KDTreeSearcher具有属性:Bucketsize:50距离:'Minkowski'DistParameter:5 x:[150x2双]
找出10个最近的邻居X查询点(纽波特),首先使用Minkowski然后使用Chybochev距离指标。查询点必须具有与用于培训模型的数据相同的列维度。
newpoint = [5 1.45];[idxmk,dmk] = knnsearch(kdtreemdl,newpoint,'K',10);[idxcb,dcb] = knnsearch(kdtreemdl,newpoint,'K'10,'距离',“chebychev”);
IDXMK.和IdxCb1 × 10矩阵是否包含行索引X对应于最近的邻居纽波特使用Minkowski和Chebychev距离。元素(1,1)是最近的,元素(1,2)是下一个最近的,等等。
绘制训练数据、查询点和最近的邻居。
图;gscatter (X (: 1) X (:, 2), Y);标题('fisher'的虹膜数据 - 最近的邻居');包含('花瓣长度(cm)');ylabel('花瓣宽度(cm)');抓住在plot(newpoint(1),newpoint(2),'kx','Markersize'10,'行宽',2);%查询点绘图(x(idxmk,1),x(idxmk,2),“o”,'颜色',[。5 .5 .5],'Markersize',10);%Minkowski最近的邻居绘图(x(idxcb,1),x(idxcb,2),“p”,'颜色',[。5 .5 .5],'Markersize',10);%chebychev最近的邻居传奇('setosa','versicolor','virginica','query point',......'minkowski',“chebychev”,'地点',“最佳”);
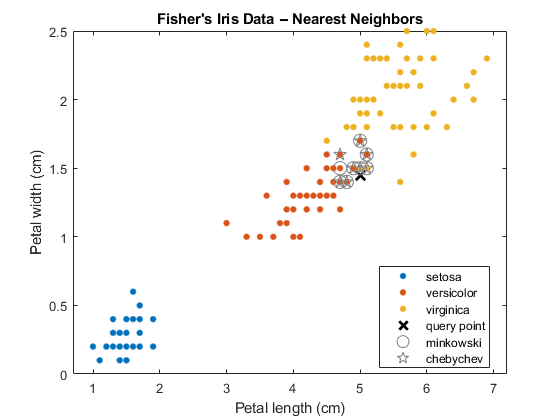
放大兴趣点。
H = GCA;%获取当前轴手柄。H.XLIM = [4.5 5.5];H.YLIM = [1 2];轴广场;
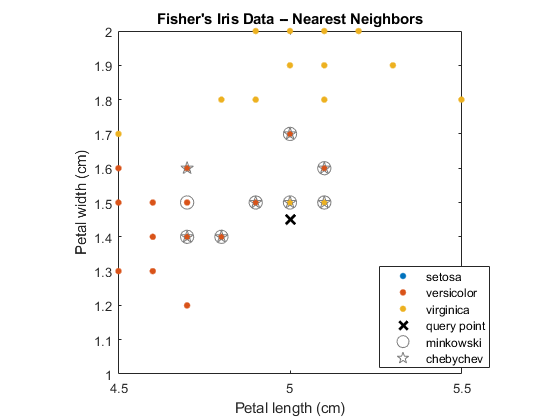
几个观察是相等的,这就是为什么在图中只识别了八个最近邻居的原因。
输入参数
输出参数
提示
knnsearch找到了k(正整数)点mdl.x.这是k- 每个人都是最初的Y点。相比之下,rangesearch.找到所有要点mdl.x.在距离内r(正标量)Y点。
替代功能
knnsearch是一个需要一个对象函数令人疲惫的或者kdtreesearcher.模型对象和查询数据。在等同条件下,knnsearch对象函数返回与此相同的结果knnsearch函数,在指定名称-值对参数时'nsmethod','穷举'或者'nsmethod','kdtree',分别。为k- 最终邻居分类,见
Fitcknn.和ClassificationKnn..
参考文献
[1] Friedman, J. H., Bentely, J.和Finkel, R. A.(1977)。"在对数预期时间内找到最佳匹配的算法"数学软件学报卷。3,第3期,977年9月,第209-226页。
扩展能力
您还可以从以下列表中选择一个网站:
