FeatureSelectionNCAClassification类
基于邻域成分分析(NCA)的分类特征选择
描述
功能选择NCA分类对象中包含的数据拟合信息,特征权重,以及邻域成分分析(NCA)模型的其他参数。fscnca公司使用NCA的对角线自适应学习特征权重,并返回功能选择NCA分类对象。该函数通过正则化特征权重来实现特征选择。
建筑
创建功能选择NCA分类对象使用fscnca公司.
属性
例子
探索功能选择NCA分类目的
加载样本数据。
负载电离层
该数据集具有34个连续预测。响应变量是雷达回波,标记为B(差)或g(好)。
飞度邻里成分分析(NCA)模型进行分类检测的相关特征。
mdl=fscnca(X,Y);
返回NCA模型,MDL,是功能选择NCA分类反对。此对象存储有关训练数据、模型和优化的信息。可以使用点表示法访问对象属性,例如要素权重。
画出要素权重。
figure()绘图(mdl特性重量,“滚”)包含('功能索引')ylabel(“特征加权”)网格上
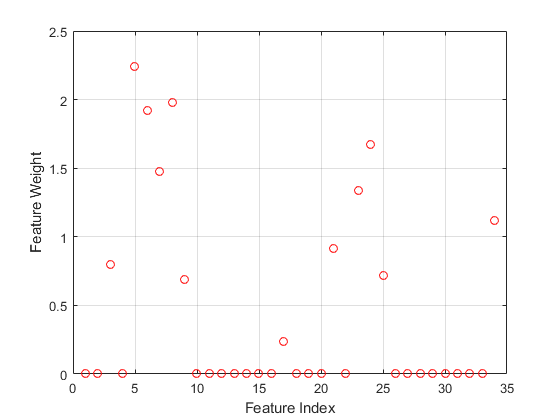
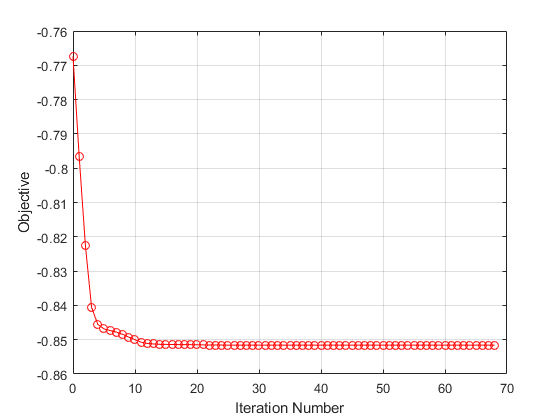
的不相关特征的权重都为零。这个“详细”,1调用中的选项fscnca公司在命令行上显示优化信息。您还可以通过绘制目标函数与迭代次数之间的关系来可视化优化过程。
图形绘图(mdl.FitInfo.Iteration迭代,mdl.FitInfo.Objective目标,“滚装”)网格上xlabel('迭代编号')ylabel(“目标”)
这个模型参数属性是结构包含有关模型的更多信息。您可以访问使用点符号此属性的领域。例如,查看数据是否被标准化与否。
mdl.ModelParameters.Standardize
ANS =符合逻辑的0个
0个该数据没有被拟合NCA模型之前标准化手段。当他们在使用非常不同的尺度可以规范预测'标准化',1调用中的名称-值对参数fscnca公司.
复制语义
值。要了解值类如何影响复制操作,请参阅复制对象(MATLAB)。
引入R2016b
您还可以选择从下面的列表中的网站:
