改装
类:FeatureSelectionNCAClassification
改装邻里成分分析(NCA)模型进行分类
句法
mdlrefit =改装(MDL,名称,值)
输入参数
输出参数
例子
改装NCA模型分类与修改后的设置
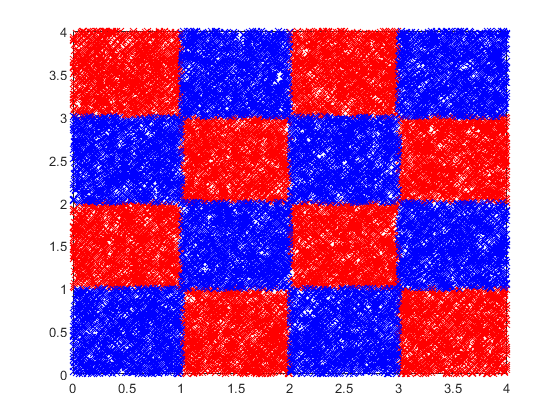
生成使用棋盘数据generateCheckerBoardData.m功能。
RNG(2016年,“扭腰”);%用于重现PPS = 1375;[X,Y] = generateCheckerBoardData(PPS);X = X + 2;
图中的数据。
图图(X(Y == 1,1),X(Y == 1,2),'RX')保持上积(X(Y == - 1,1),X(Y == - 1,2),'BX')[N,P] =尺寸(X)
N = 22000 P = 2
无关预测添加到数据。
Q = 98;Xrnd = unifrnd(0,4,N,Q);Xobs = [X,Xrnd];
这段代码创建98个的其他预测,全部为0和4之间均匀地分布。
将数据划分为训练和测试集。要创建分层分区,使每个分区都有类类似的比例,使用ÿ代替冗长)作为分区的标准。
CVP = cvpartition(Y,'坚持',2000);
cvpartition随机选择的意见2000添加到测试集和其余数据添加到训练集。创建培训和使用分配确认将存储在cvpartition目的CVP。
Xtrain = Xobs(cvp.training(1),:);ytrain = Y(cvp.training(1),:);XVAL = Xobs(cvp.test(1),:);利用yval = Y(cvp.test(1),:);
不计算特征选择误分。
NCA = fscnca(Xtrain,ytrain,'使用fitmethod','没有',“标准化”,真正,...“求解”,'lbfgs');loss_nofs =损失(NCA,XVAL,利用yval)
loss_nofs = 0.5165
'使用fitmethod', '无'选择使用默认的权重(全1),这意味着所有的功能都同样重要。
这一次,使用邻分类成分分析进行特征选择,用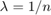 。
。
W0 =兰特(100,1);N =长度(ytrain)的λ= 1 / N;NCA =改装(NCA,'InitialFeatureWeights',W0,'使用fitmethod','精确',...“拉姆达”,λ,“求解”,“新元”);
N = 20000
绘制目标函数值与迭代次数。
图()图(nca.FitInfo.Iteration,nca.FitInfo.Objective,'RO')保持上情节(nca.FitInfo.Iteration,movmean(nca.FitInfo.Objective,10),'k.-')xlabel(“迭代次数”)ylabel(“客观价值”)
计算与特征选择的误分。
loss_withfs =损失(NCA,XVAL,利用yval)
loss_withfs = 0.0115
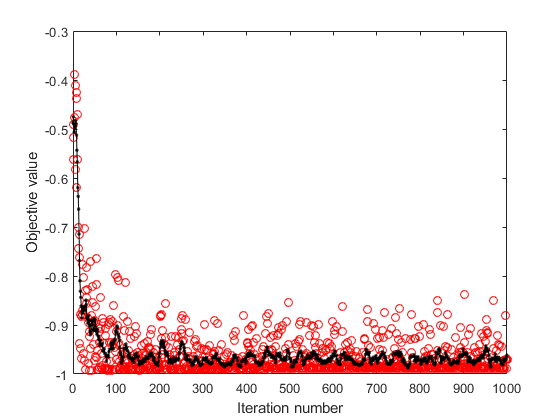
绘制选择的要素。
图semilogx(nca.FeatureWeights,'RO')xlabel(“特色指标”)ylabel(“特征权重”)网格上
使用要素权重和相对阈值选择功能。
TOL = 0.15;selidx =查找(nca.FeatureWeights> TOL *最大(1,MAX(nca.FeatureWeights)))
selidx = 1 2
特征选择提高的结果,并fscnca检测到正确的两种功能的相关性。
介绍了在R2016b
您还可以选择从下面的列表中的网站:
