损失
类:FeatureSelectionNCAClassification
评估学习的特征权重的精度测试数据
句法
ERR =损失(MDL,X,Y)
呃=损失(mdl, X, Y,名称,值)
输入参数
输出参数
例子
调NCA模型分类
加载样本数据。
加载(“twodimclassdata.mat”);
使用[1]中描述的方案对该数据集进行模拟。这是一个二维的两类分类问题。第一类(第-1类)的数据来自两个二元正态分布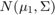 要么
要么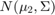 以相等的概率,其中
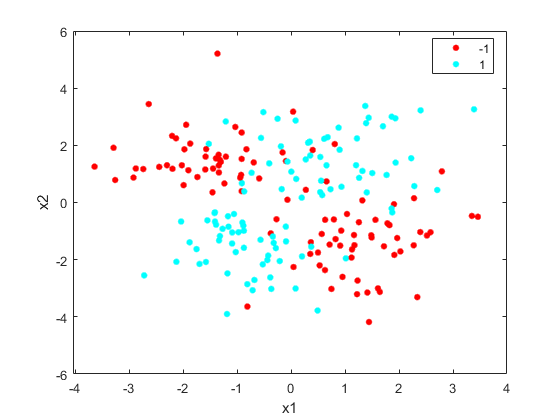
以相等的概率,其中![美元$ \ mu_1 = [-0.75, -1.5]](http://www.tianjin-qmedu.com/help/examples/stats/win64/PredictClassLabelsUsingNCAModelExample_eq03336482581861985583.png) ,
,![美元$ \ mu_2 = [0.75, 1.5]](http://www.tianjin-qmedu.com/help/examples/stats/win64/PredictClassLabelsUsingNCAModelExample_eq17527623940921012900.png) ,
,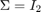 。类似地,从第二类(类别1)的数据是从两个二元正态分布绘制
。类似地,从第二类(类别1)的数据是从两个二元正态分布绘制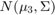 要么
要么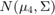 以相等的概率,其中
以相等的概率,其中![$ \ mu_3 = [1.5,-1.5] $](http://www.tianjin-qmedu.com/help/examples/stats/win64/PredictClassLabelsUsingNCAModelExample_eq02369827013796961285.png) ,
,![美元$ \ mu_4 = [-1.5, 1.5]](http://www.tianjin-qmedu.com/help/examples/stats/win64/PredictClassLabelsUsingNCAModelExample_eq10119612338443584655.png) ,。用于创建此数据集的正态分布参数会导致比[1]中使用的数据更紧密的数据簇。
,。用于创建此数据集的正态分布参数会导致比[1]中使用的数据更紧密的数据簇。
创建按类分组的数据散点图。
图gscatter (X (: 1), (:, 2), y)包含(x1的)ylabel(“x2”)
加100个无关的功能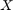 。首先生成从具有0均值和20的方差正态分布的数据。
。首先生成从具有0均值和20的方差正态分布的数据。
n =大小(X, 1);rng ('默认')XwithBadFeatures = [X,randn(N,100)* SQRT(20)];
归一化数据,使得所有的点是0和1之间。
XwithBadFeatures = bsxfun (@rdivide,...bsxfun(@减去,XwithBadFeatures,分钟(XwithBadFeatures,[],1)),...范围(XwithBadFeatures,1));X = XwithBadFeatures;
使用默认值对数据拟合邻域成分分析(NCA)模型λ(正则化参数,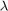 )值。使用LBFGS求解器并显示收敛信息。
)值。使用LBFGS求解器并显示收敛信息。
ncaMdl = fscnca(X,Y,'使用fitmethod','精确',“详细”,1...“求解”,“lbfgs”);
ø求解= LBFGS,HessianHistorySize = 15,LineSearchMethod = weakwolfe | ==================================================================================================== ||ITER |FUN VALUE |NORM GRAD |NORM STEP |CURV |GAMMA |ALPHA |接受| |====================================================================================================| | 0 | 9.519258e-03 | 1.494e-02 | 0.000e+00 | | 4.015e+01 | 0.000e+00 | YES | | 1 | -3.093574e-01 | 7.186e-03 | 4.018e+00 | OK | 8.956e+01 | 1.000e+00 | YES | | 2 | -4.809455e-01 | 4.444e-03 | 7.123e+00 | OK | 9.943e+01 | 1.000e+00 | YES | | 3 | -4.938877e-01 | 3.544e-03 | 1.464e+00 | OK | 9.366e+01 | 1.000e+00 | YES | | 4 | -4.964759e-01 | 2.901e-03 | 6.084e-01 | OK | 1.554e+02 | 1.000e+00 | YES | | 5 | -4.972077e-01 | 1.323e-03 | 6.129e-01 | OK | 1.195e+02 | 5.000e-01 | YES | | 6 | -4.974743e-01 | 1.569e-04 | 2.155e-01 | OK | 1.003e+02 | 1.000e+00 | YES | | 7 | -4.974868e-01 | 3.844e-05 | 4.161e-02 | OK | 9.835e+01 | 1.000e+00 | YES | | 8 | -4.974874e-01 | 1.417e-05 | 1.073e-02 | OK | 1.043e+02 | 1.000e+00 | YES | | 9 | -4.974874e-01 | 4.893e-06 | 1.781e-03 | OK | 1.530e+02 | 1.000e+00 | YES | | 10 | -4.974874e-01 | 9.404e-08 | 8.947e-04 | OK | 1.670e+02 | 1.000e+00 | YES | Infinity norm of the final gradient = 9.404e-08 Two norm of the final step = 8.947e-04, TolX = 1.000e-06 Relative infinity norm of the final gradient = 9.404e-08, TolFun = 1.000e-06 EXIT: Local minimum found.
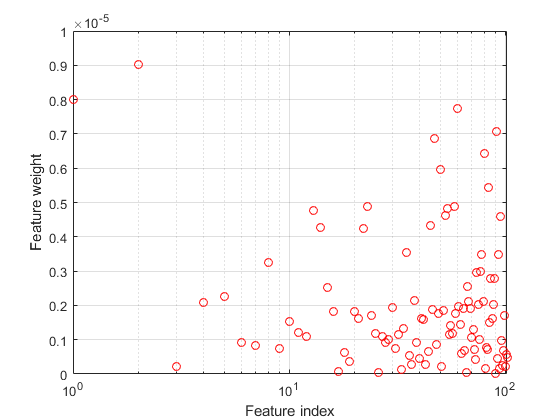
绘制特征权重。的不相关特征的权重应该是非常接近于零。
图semilogx(ncaMdl.FeatureWeights,'RO')xlabel(“特色指标”)ylabel(“特征权重”网格)上
使用NCA模型预测类并计算混淆矩阵。
ypred =预测(ncaMdl X);ypred confusionchart (y)

混淆矩阵显示,是在类数据-1的40被预测为属于类-1。从类的数据的60 -1被预测为在类1。类似地,从1类的数据的94被预测为从1类和它们的6被预测为从类-1。类的预测精度-1不好。
所有重量都非常接近零,这表明价值在训练中使用的模型太大。当 ,所有特征权重接近于零。因此,在大多数情况下,调整正则化参数来检测相关特征是很重要的。
,所有特征权重接近于零。因此,在大多数情况下,调整正则化参数来检测相关特征是很重要的。
使用五倍交叉验证进行调优为特征选择使用fscnca。调音手段找到值将产生最小分类损失。调使用交叉验证:
1.分区数据成五倍。对于每个倍,cvpartition分配数据的五分之四作为训练集和五分之一中的数据作为测试组。再次对于每个倍,cvpartition创建一个分层分区,其中每个分区具有大致的类相同的比例。
本量利= cvpartition (y,“kfold”5);numtestsets = cvp.NumTestSets;lambdavalues = linspace(0、2、20) /长度(y);lossvalues = 0(长度(lambdavalues), numtestsets);
2.列车附近成分分析(NCA)模型为每个在每条折线中使用训练集。
3.计算用于使用NCA模型在折叠相应的测试集的分类损失。记录的损耗值。
4.重复此过程为所有的折叠和所有值。
为I = 1:长度(lambdavalues)为k = 1: numtestsets%从分区对象中提取训练集Xtrain = X (cvp.training (k):);ytrain = y (cvp.training (k):);%提取从分区对象测试集Xtest = X (cvp.test (k):);欧美= y (cvp.test (k):);利用训练集%的火车模型NCA分类ncaMdl = fscnca (Xtrain ytrain,'使用fitmethod','精确',...“求解”,“lbfgs”,“拉姆达”lambdavalues(我));%计算用于使用NCA测试集的分类损失%的模型lossvalues (i (k) =损失(ncaMdl Xtest,欧美,...'LossFunction',“二次”);结束结束
绘制的褶皱相对于平均损耗值值。如果与最小损失相对应的值落在被测物的边界上值,范围价值观应该被重新考虑。
图绘制(lambdavalues,意味着(lossvalues, 2),“ro - - - - - -”)xlabel(“λ值”)ylabel(“损失价值”网格)上

找到值,该值对应于最小平均损失。
[~,idx] = min(意味着(lossvalues, 2));%查找索引bestlambda = lambdavalues(IDX)%找到最好的lambda值
bestlambda = 0.0037
用最好的方法使NCA模型适合所有的数据价值。使用LBFGS求解器并显示收敛信息。
ncaMdl = fscnca(X,Y,'使用fitmethod','精确',“详细”,1...“求解”,“lbfgs”,“拉姆达”,bestlambda);
ø求解= LBFGS,HessianHistorySize = 15,LineSearchMethod = weakwolfe | ==================================================================================================== ||ITER |FUN VALUE |NORM GRAD |NORM STEP |CURV |GAMMA |ALPHA |接受| |====================================================================================================| | 0 | -1.246913e-01 | 1.231e-02 | 0.000e+00 | | 4.873e+01 | 0.000e+00 | YES | | 1 | -3.411330e-01 | 5.717e-03 | 3.618e+00 | OK | 1.068e+02 | 1.000e+00 | YES | | 2 | -5.226111e-01 | 3.763e-02 | 8.252e+00 | OK | 7.825e+01 | 1.000e+00 | YES | | 3 | -5.817731e-01 | 8.496e-03 | 2.340e+00 | OK | 5.591e+01 | 5.000e-01 | YES | | 4 | -6.132632e-01 | 6.863e-03 | 2.526e+00 | OK | 8.228e+01 | 1.000e+00 | YES | | 5 | -6.135264e-01 | 9.373e-03 | 7.341e-01 | OK | 3.244e+01 | 1.000e+00 | YES | | 6 | -6.147894e-01 | 1.182e-03 | 2.933e-01 | OK | 2.447e+01 | 1.000e+00 | YES | | 7 | -6.148714e-01 | 6.392e-04 | 6.688e-02 | OK | 3.195e+01 | 1.000e+00 | YES | | 8 | -6.149524e-01 | 6.521e-04 | 9.934e-02 | OK | 1.236e+02 | 1.000e+00 | YES | | 9 | -6.149972e-01 | 1.154e-04 | 1.191e-01 | OK | 1.171e+02 | 1.000e+00 | YES | | 10 | -6.149990e-01 | 2.922e-05 | 1.983e-02 | OK | 7.365e+01 | 1.000e+00 | YES | | 11 | -6.149993e-01 | 1.556e-05 | 8.354e-03 | OK | 1.288e+02 | 1.000e+00 | YES | | 12 | -6.149994e-01 | 1.147e-05 | 7.256e-03 | OK | 2.332e+02 | 1.000e+00 | YES | | 13 | -6.149995e-01 | 1.040e-05 | 6.781e-03 | OK | 2.287e+02 | 1.000e+00 | YES | | 14 | -6.149996e-01 | 9.015e-06 | 6.265e-03 | OK | 9.974e+01 | 1.000e+00 | YES | | 15 | -6.149996e-01 | 7.763e-06 | 5.206e-03 | OK | 2.919e+02 | 1.000e+00 | YES | | 16 | -6.149997e-01 | 8.374e-06 | 1.679e-02 | OK | 6.878e+02 | 1.000e+00 | YES | | 17 | -6.149997e-01 | 9.387e-06 | 9.542e-03 | OK | 1.284e+02 | 5.000e-01 | YES | | 18 | -6.149997e-01 | 3.250e-06 | 5.114e-03 | OK | 1.225e+02 | 1.000e+00 | YES | | 19 | -6.149997e-01 | 1.574e-06 | 1.275e-03 | OK | 1.808e+02 | 1.000e+00 | YES | |====================================================================================================| | ITER | FUN VALUE | NORM GRAD | NORM STEP | CURV | GAMMA | ALPHA | ACCEPT | |====================================================================================================| | 20 | -6.149997e-01 | 5.764e-07 | 6.765e-04 | OK | 2.905e+02 | 1.000e+00 | YES | Infinity norm of the final gradient = 5.764e-07 Two norm of the final step = 6.765e-04, TolX = 1.000e-06 Relative infinity norm of the final gradient = 5.764e-07, TolFun = 1.000e-06 EXIT: Local minimum found.
绘制特征权重。
图semilogx(ncaMdl.FeatureWeights,'RO')xlabel(“特色指标”)ylabel(“特征权重”网格)上
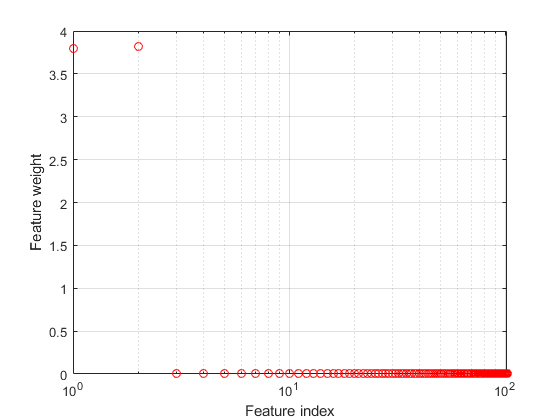
fscnca正确地计算出前两个特征是相关的,并且其余的都没有。前两个特点是不单独提供信息,但服用时一起导致一个准确的分类模型。
使用新的模型预测类和计算的准确性。
ypred =预测(ncaMdl X);ypred confusionchart (y)

混淆矩阵表明,对-1类的预测精度有所提高。88个来自类-1的数据预测来自类-1,12个来自类-1。第1类的数据中有92个预测来自第1类,其中有8个预测来自第1类。
参考
[1]杨,W.,K.王,W.佐。“居委会组件特征选择高维数据。”计算机学报。2012年1月,第7卷第1期
介绍了在R2016b
您也可以从以下列表中选择网站:
