fsrftest
单因素功能使用回归排名F-tests
句法
描述
IDX= fsrftest(TBL,ResponseVarName)TBL包含预测变量和响应变量,和ResponseVarName是在响应变量的名称TBL。该函数返回IDX,其中包含预测的指数下令预测的重要性,这意味着IDX(1)是最重要的预测指数。您可以使用IDX选择回归问题的重要预测指标。
例子
排名预测因素矩阵
在数字矩阵的秩预测和创建预测的重要性分数的柱状图。
加载样本数据。
加载robotarm.mat
该robotarm数据集包含7168条培训意见(Xtrain和ytrain)和1024个测试观测(XTEST和ytest)与32层的功能[1][2]。
排名使用的训练观察的预测。
[IDX,分数] = fsrftest(Xtrain,ytrain);
中的数值分数是的负面记录p- 值。如果一个p- 值小于EPS(0),则对应的得分值是天道酬勤。创建柱状图之前,确定是否分数包括天道酬勤值。
找到(isinf(分数))
ANS = 1X0空双行向量
分数不包括天道酬勤值。如果分数包括天道酬勤值,可以更换天道酬勤通过建立可视化的目的柱状图前大数字号码。有关详细信息,请参阅预测指标排名表。
创建预测重要性分数的柱状图。
巴(分数(IDX))xlabel(“预测排名”)ylabel(“预测变量重要性评分”)
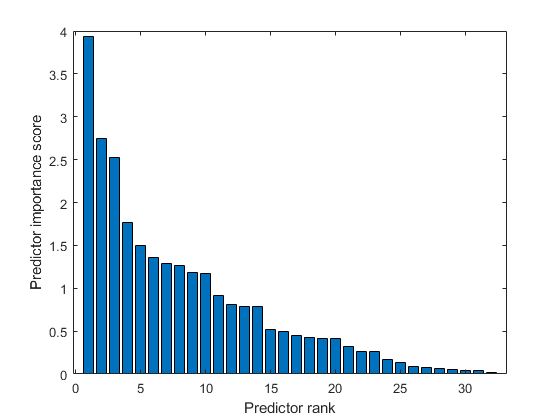
选择最上面的五个最重要的预测指标。找到这些预测的列Xtrain。
IDX(1:5)
ANS =1×530 24 10 4 5
第30列Xtrain是最重要的预测ytrain。
预测指标排名表
表中的排名预测和创建预测的重要性分数的柱状图。
如果你的数据是在一个表,fsrftest排名仅使用子集表中的变量,那么该功能指标变量的一个子集。因此,一个好的做法是将你不想列在表的末尾的预测。移动响应变量和观察权重向量,以及。然后,输出参数的索引是表的索引一致。您可以使用一个表中移动变量movevars功能。
此示例使用鲍鱼数据[3][4]从UCI机器学习库[5]。下载数据,并将其与名称保存在当前文件夹'abalone.data'。
在表中存储数据。
TBL = readtable('abalone.data','文件类型','文本','ReadVariableNames',假);tbl.Properties.VariableNames = {'性别','长度','直径','高度',...'WWeight','SWeight','VWeight','ShWeight','NoShellRings'};
预览表的前几行。
头(TBL)
ANS =8×9表性别长度直径高度WWeight SWeight VWeight ShWeight NoShellRings _____ ______ ________ ______ _______ _______ ________ ____________ { 'M'} 0.455 0.365 0.095 0.514 0.2245 0.101 0.15 15 { 'M'} 0.35 0.265 0.09 0.2255 0.0995 0.0485 0.07 7 { 'F'} 0.530.42 0.135 0.677 0.2565 0.1415 0.21 9 { 'M'} 0.44 0.365 0.125 0.516 0.2155 0.114 0.155 10 { 'I'} 0.33 0.255 0.08 0.205 0.0895 0.0395 0.055 7 { 'I'} 0.425 0.3 0.095 0.3515 0.141 0.0775 0.12 8 { 'F'} 0.53 0.415 0.15 0.7775 0.237 0.1415 0.33 20 { 'F'} 0.545 0.425 0.125 0.768 0.294 0.1495 0.26 16
该表中的最后一个变量是响应变量。
排在预测TBL。指定的最后一列NoShellRings作为响应变量。
[IDX,分数] = fsrftest(TBL,'NoShellRings')
IDX =1×83 4 5 7 8 2 6 1
分数=1×8447.6891 736.9619天道酬勤天道酬勤天道酬勤天道酬勤604.6692天道酬勤
中的数值分数是的负面记录p- 值。如果一个p- 值小于EPS(0),则对应的得分值是天道酬勤。创建柱状图之前,确定是否分数包括天道酬勤值。
idxInf =找到(isinf(得分))
idxInf =1×53 4 5 7 8
分数包括五个天道酬勤值。
创建预测的重要性分数的柱状图。使用该预测名称X轴刻度标记。
巴(分数(IDX))xlabel(“预测排名”)ylabel(“预测变量重要性评分”)xticklabels(strrep(tbl.Properties.VariableNames(IDX),'_','\ _'))xtickangle(45)
该酒吧功能无法绘制的任何条天道酬勤值。为了天道酬勤值,即具有相同的长度作为最大的有限得分图吧。
保持上巴(分数(IDX(长度(idxInf)+1))*酮(长度(idxInf),1))图例(“有限分数”,“天道酬勤成绩”)保持离
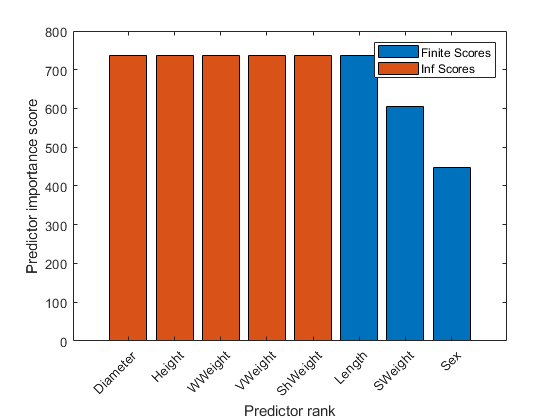
条形图显示有限使用不同的颜色得分和INF分数。
输入参数
输出参数
提示
如果您使用的输入参数中指定的响应变量和预测变量
式,则在公式中的变量名必须在两个变量名TBL(Tbl.Properties.VariableNames)和有效的MATLAB标识符。您可以验证的变量名中
TBL通过使用isvarname功能。下面的代码返回的逻辑1(真正)对于具有合法的变量名每个变量。如果变量名中cellfun(@ isvarname,Tbl.Properties.VariableNames)
TBL是无效的,然后使用它们转换matlab.lang.makeValidName功能。Tbl.Properties.VariableNames = matlab.lang.makeValidName(Tbl.Properties.VariableNames);
算法
参考
[1] Rasmussen的,C. E.,R. M.尼尔,G. E.欣顿,D.面包车营,M. Revow,Z. Ghahramani,R. Kustra和R. Tibshirani。该DELVE手册,1996。
[2]多伦多大学计算机科学系。藏坑的数据集。
[3]纳什,沃里克J.,编鲍鱼的种群生物学(鲍物种)在塔斯马尼亚。1:黑蝶鲍鱼(H.赤芍)从北海岸和巴斯海峡的岛屿。海洋渔业技术报告/部,塔斯马尼亚48 Taroona:海洋研究实验室,1994年。
[4]沃,S.“扩展和基准级联相关性”。博士论文。计算机科学系,塔斯马尼亚州,1995年大学。
[5] Lichman,M. UCI机器学习知识库。尔湾,CA:加州大学信息与计算机科学学院,2013年http://archive.ics.uci.edu/ml。
介绍了在R2020a
您还可以选择从下面的列表中的网站:
