生成相关数据使用等级相关
此示例示出了如何使用一个连接函数和等级相关,以生成从概率分布相关的数据不具有可用的逆CDF功能,如皮尔逊柔性分布族。
步骤1.生成皮尔森随机数。
从两个不同的皮尔逊分布产生1000张随机数,使用pearsrnd功能。第一分布具有的参数值亩等于0,当δ等于1,歪斜等于1,和峰度等于4。第二分布具有的参数值亩等于0,当δ等于1,歪斜等于0.75,和峰度等于3。
RNG默认%用于重现P1 = pearsrnd(0,1,-1,4,1000,1);P2 = pearsrnd(0,1,0.75,3,1000,1);
在这个阶段,P1和P2是从它们各自的皮尔逊分布独立样本,并且是不相关的。
第2步画出皮尔森随机数。
创建一个scatterhist绘制可视化皮尔森随机数。
图scatterhist(P1,P2)

直方图显示的边缘分布P1和P2。散点图显示了联合分布P1和P2。缺乏格局的散点图显示P1和P2是独立的。
第3步:生成使用高斯系词随机数。
用copularnd产生具有相关系数1000张相关的随机数等于-0.8,使用高斯连接函数。创建一个scatterhist绘制可视化从Copula函数产生的随机数。
U = copularnd(“高斯”,-0.8,1000);图scatterhist(U(:,1)中,u(:,2))
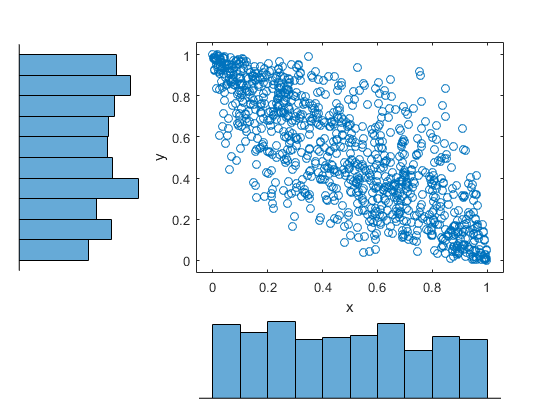
直方图显示的是,在接合装置的每列中的数据有一个边缘均匀分布。散点图显示在两列中的数据是负相关的。
第4步排序Copula函数随机数。
使用Spearman秩相关,改造两个独立皮尔逊样品放入相关的数据。
使用分类功能,从最小到最大的系词随机数进行排序,并返回描述该号码的重新排列的顺序索引的矢量。
[S1,I1] =排序(U(:,1));[S2,I2] =排序(U(:,2));
S1和S2从连接函数的第一和第二列包括数字,ü,排序依次从最小到最大。I1和I2是所描述的元素的重新排列的顺序为索引矢量S1和S2。例如,如果在排序矢量的第一个值S1是在原未排序矢量第三值,则在索引向量的第一个值I13。
第5步:使用Spearman秩相关变换皮尔逊样本。
创建零的两个向量,X1和X2中,对大小排序的连接函数矢量相同,S1和S2。排序中的值P1和P2从最小到最大。放置值代入X1和X2在相同的顺序指数I1和I2通过排序连接函数的随机数生成。
X1 =零(尺寸(S1));X2 =零(尺寸(S2));X1(I1)=排序(P1);X2(I2)=排序(P2);
步骤6,绘制相关皮尔逊随机数。
创建一个scatterhist剧情以可视化的相关Pearson数据。
图scatterhist(X1,X2)

直方图显示数据的每列中的边际皮尔逊分布。散点图显示的联合分布P1和P2,并表示该数据正在呈负相关。
步骤7.确认Spearman秩相关系数的值。
确认的Spearman等级相关系数是为连接函数的随机数和所述相关皮尔逊随机数相同。
copula_corr =更正件(U,'类型',“斯皮尔曼)
copula_corr =2×21.0000 -0.7858 -0.7858 1.0000
pearson_corr =科尔([X1,X2],'类型',“斯皮尔曼)
pearson_corr =2×21.0000 -0.7858 -0.7858 1.0000
Spearman等级相关性是系词与皮尔森的随机数相同。
也可以看看
相关话题
您还可以选择从下面的列表中的网站:
