Copulas:产生相关的样本
连系动词是描述变量之间依赖关系的函数,并提供一种方法来创建建模相关多元数据的分布。通过使用关联函数,您可以通过指定边际单变量分布来构建一个多元分布,然后选择一个关联函数来提供变量之间的相关结构。二元分布,以及高维分布是可能的。
确定模拟输入之间的依赖性
Monte Carlo仿真的设计决策之一是随机输入的概率分布的选择。选择每个单独变量的分发通常很简单,但决定在输入之间应存在哪些依赖关系。理想情况下,对模拟的输入数据应反映您对您正在建模的实际数量之间的了解。然而,可能很少或没有关于在模拟中基于任何依赖的信息。在这种情况下,实验不同的可能性是为了确定模型的敏感性。
当它们的分布不是来自标准的多元分布时,很难产生具有依赖性的随机输入。此外,一些标准的多元分布只能模拟有限类型的依赖。让输入独立总是可能的,虽然这是一个简单的选择,但并不总是明智的,可能会导致错误的结论。
例如,金融风险的Monte-Carlo模拟可能有两个随机投入,代表不同的保险损失来源。您可以将这些输入模型为逻辑正常随机变量。询问的合理问题是这两个输入之间的依赖性如何影响模拟结果。实际上,您可能知道来自相同随机条件影响两个来源的真实数据;忽略模拟中可能导致错误的结论。
生成正态随机变量并取其指数
的lognrnd.功能模拟独立的Lognormal随机变量。在以下示例中,mvnrnd.函数生成n对独立的正常随机变量对,然后以代误来计算它们。请注意,这里使用的协方差矩阵是对角线。
n = 1000;σ= 5;SigmaInd =σ。^2 .* [1;0 1]
sigmaind =2×20.2500 0 0 0.2500
RNG('默认');重复性的%zind = mvnrnd([0 0],sigmaind,n);Xind = Exp(Zind);情节(Xind(:,1),Xind(:,2),“。”)轴([0 5 0 5])轴平等的Xlabel(X1的)ylabel('x2')
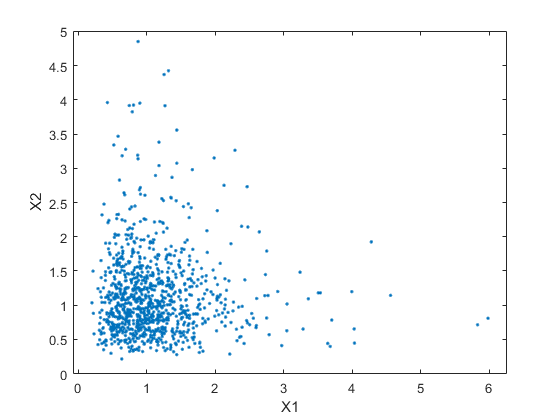
依赖性双变量逻辑随机变量也很容易使用具有非零对角线术语的协方差矩阵来生成。
rho = .7;sigmadep = sigma。^ 2。* [1 rho;rho 1]
sigmadep =2×20.2500 0.1750 0.1750 0.2500
zdep = mvnrnd([0 0],sigmadep,n);xdep = exp(zdep);
第二个散点图显示了这两个二元分布之间的差异。
情节(XDep (: 1) XDep (:, 2),“。”)轴([0 5 0 5])轴平等的Xlabel(X1的)ylabel('x2')
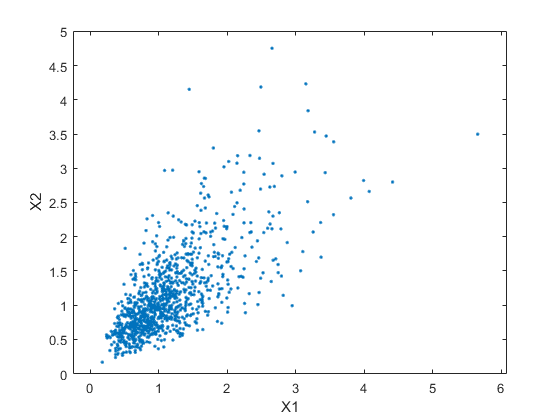
很明显,对于大量值,第二个数据趋势X1与大值相关联X2,并且类似地占小值。相关参数
潜在的双方正常确定这种依赖。从模拟中得出的结论很可能取决于你是生成的X1和X2依赖。在这种情况下,双变量的Lognormal分布是一种简单的解决方案;在边际分布是不同的逻辑正运的情况下,它很容易推广到更高的尺寸。
其他多变量分布也存在。例如,多变量t并且dirichlet分布模拟依赖t和β随机变量分别。但简单的多变量分布的列表不长,它们仅适用于边际的案件,其中包括在同一个家庭(甚至是完全相同的分布)。这可能是许多情况下的严重限制。
构建依赖性的双变量分布
虽然上一节中讨论的结构创建了一个简单的双变量逻辑,但是它用于说明更普遍适用的方法。
从二元正态分布生成值对。这两个变量之间有统计依赖关系,每个变量都有正态边际分布。
将转换(指数函数)单独应用于每个变量,将边缘分布更改为Lognormals。转换的变量仍然具有统计依赖性。
如果能找到合适的变换,该方法可以推广到具有其他边际分布的相依二元随机向量。事实上,构造这样一个变换的一般方法是存在的,尽管它不像单独的取幂那么简单。
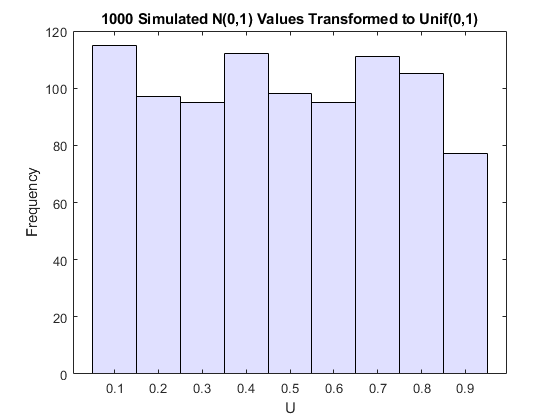
根据定义,应用正常的累积分布函数(CDF),该函数由φ表示,到标准的正常随机变量导致在间隔内均匀的随机变量[0,1]。看到这个,如果Z具有标准的正态分布,然后是CDFU=Φ(Z)是
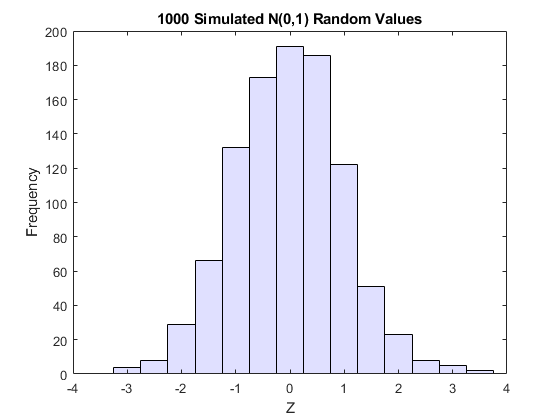
这是一个Unif(0,1)随机变量的cdf。一些模拟的正态值和转换值的直方图证明了这一事实:
n = 1000;RNG.默认的%的再现性z = normrnd(0,1,n,1);%生成标准正常数据直方图(z,-3.75:.5:3.75,'facecholor',[。8 .8 1])%绘制数据的直方图xlim(4[4])标题('1000模拟n(0,1)随机值')Xlabel('Z')ylabel('频率')
u = normcdf(z);%计算样本数据的CDF值图表直方图(U,.05:.1:.95,'facecholor',[。8 .8 1])%绘制CDF值的直方图标题('1000模拟n(0,1)值转换为UNIF(0,1)')Xlabel('U')ylabel('频率')
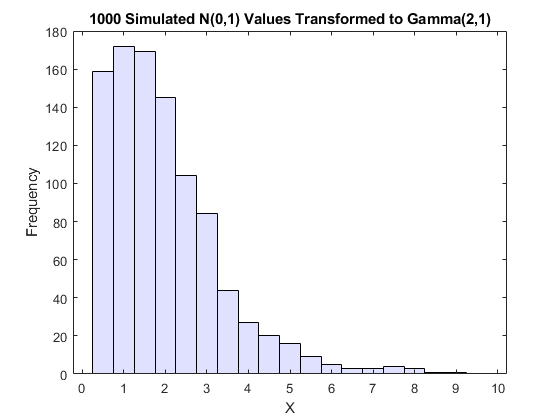
从单变量随机数发电的理论借用,应用任何分布的逆CDF,F,到一个Unif(0,1)随机变量导致随机变量,其分发正好F(看反转方法)。证明基本上与前后案例的先前证明相反。另一个直方图说明了对伽马分布的转换:
x = gaminv (u 2 1);%转换为伽玛值图直方图(x)为:.5:9.75,'facecholor',[。8 .8 1])%绘制伽马值的直方图标题('1000模拟N(0,1)值转换为Gamma(2,1)')Xlabel('X')ylabel('频率')
你可以将这个两步变换应用到一个标准二元正态的每个变量上,创建具有任意边际分布的相关随机变量。由于变换对每个分量单独进行,因此得到的两个随机变量甚至不需要具有相同的边际分布。转换定义为:
在哪里 和 是两种可能不同的分布的逆CDF。例如,下面生成与双变量分布的随机向量 和γ(2,1)的人:
n = 1000;rho = .7;z = mvnrnd([0 0],[1 rho; rho 1],n);u = normcdf(z);x = [gaminv(u(:,1),2,1)tinv(u(:,2),5)];用直方图绘制数据的散点图图scatterhist (X (: 1), (:, 2),“方向”,'出去')
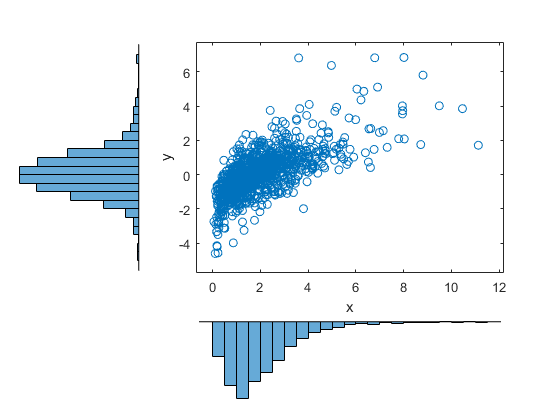
这个图有直方图和散点图来显示边缘分布和依赖。
使用等级相关系数
相关参数,ρ,决定了之间的依赖关系X1和X2在这个建设中。但是,线性相关性X1和X2不是ρ.例如,在原始对数正态情况下,该相关性的闭合形式是:
哪个严格小于ρ, 除非ρ就是1。在更一般的情况下,比如Gamma/t施工,线性相关性X1和X2难以表达或不可能ρ,但模拟表明发生了相同的效果。
即,因为线性相关系数表示随机变量之间的线性依赖性,并且当非线性变换应用于那些随机变量时,不保留线性相关性。相反,等级相关系数,例如肯德尔的τ.斯皮尔曼的ρ,更合适。
粗略地说,这些等级相关性测量一个随机变量的大值或小值与另一个的大值或小值的程度。然而,与线性相关系数不同,它们仅在等级中测量关联。结果,在任何单调转化下都保留了等级相关性。特别地,刚刚描述的转换方法保留了等级相关性。因此,了解一致正常的等级相关性Z恰好确定最终变换的随机变量的秩相关,X.而线性相关系数,ρ,仍然需要参数化底层的双匹凡芯正常,肯德尔τ.斯皮尔曼的ρ更有用的是在描述随机变量之间的依赖性,因为它们是不变的选择边际分布。
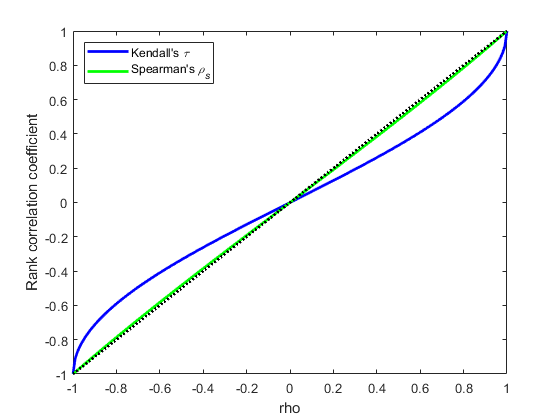
对于Bivariate Normal,Kendall之间存在简单的一对一映射τ.斯皮尔曼的ρ,线性相关系数ρ:
下面的图表显示了这种关系。
ρ= 1:.01:1;τ= 2 * asin(ρ)。/π;rho_s = 6。* asin (rho. / 2)。/π;情节(ρ,τ,'B-',“线宽”,2)持有在情节(rho,rho_s,“g -”,“线宽”,2) plot([-1 1],[-1 1],'k:',“线宽”2)轴([ - 1 1 -1 1])xlabel('rho')ylabel(等级相关系数的)传说('肯德尔'的{\它\ tau}',...'spearman'的{\它\ rho_s}',...'地点','nw')
因此,很容易创建所需的等级相关性之间X1和X2,无论他们的边缘分布如何,选择正确ρ用于线性相关性的参数值Z1和Z2.
对于多元正态分布,Spearman的秩相关几乎与线性相关性相同。但是,一旦转换为最终随机变量,这不是真的。
使用二抗体共用
上一节中描述的构造的第一步定义了所谓的二芳像素Copula。Copula是多元概率分布,其中每个随机变量对单位间隔具有均匀的边缘分布[0,1].这些变量可以是完全独立的,确定性相关的(例如,U2 = U1)或者之间的任何东西。由于有可能在变量之间依赖,您可以使用Copula构建新的多变量分布以进行依赖变量。通过使用倒置方法分别地将Copula中的每个变量转换,可能使用不同的CDF,所得到的分布可以具有任意的边际分布。这种多变量分布通常在模拟中是有用的,当您知道不同的随机输入彼此不独立时。
统计和机器学习工具箱功能计算:
概率密度函数(
Copulapdf.)和累积分配功能(Copulacdf.)对于高斯金属蛋白由线性相关而来的秩相关(
copulastat),反之亦然(copulaparam)随机向量(
copularnd.)适合数据的copula参数(
copulafit)
例如,使用copularnd.函数从一分差异的高斯Copula创建随机值的散点图,以进行各种级别的ρ,以说明不同依赖结构的范围。二元高斯copulas家族由线性相关矩阵参数化:
U1和U2接近线性依赖ρ接近±1,接近完全独立为ρ接近零:
n = 500;RNG('默认')%的再现性U = copularnd ('高斯',[1 .8;.8 1],n);子图(2,2,1)绘图(U(:,1),U(:,2),“。”) 标题('{\它\ rho} = 0.8')Xlabel('U1')ylabel('U2')u = copularnd('高斯',[1 .1;.1 1],n);子图(2,2,2)绘图(U(:,1),U(:,2),“。”) 标题(“{\ \ρ}= 0.1”)Xlabel('U1')ylabel('U2')u = copularnd('高斯'约[1;-.1],n);子图(2,2,3)绘图(U(:,1),U(:,2),“。”) 标题('{\它\ rho} = -0.1')Xlabel('U1')ylabel('U2')u = copularnd('高斯',(1。8;-.8 1],n);子图(2,2,4)绘图(U(:,1),U(:,2),“。”) 标题('{\它\ rho} = -0.8')Xlabel('U1')ylabel('U2')
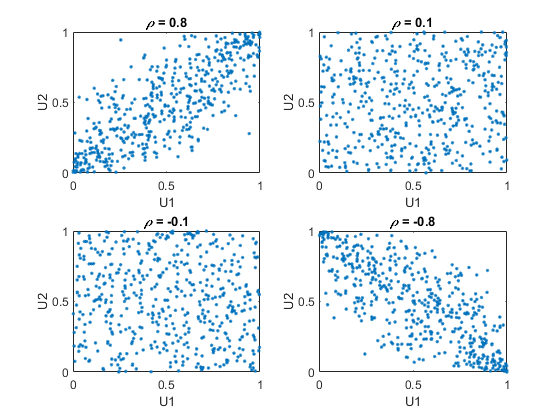
之间的依赖U1和U2是完全独立于边缘分布的x1 = g(u1)和X2 = G (U2).X1和X2可以给出任意的边际分布,并且仍然具有相同的秩相关。这是联系词的主要吸引力之一——它们允许独立说明依赖和边际分布。你亦可计算pdf (Copulapdf.)及公积金基金(Copulacdf.)作为一个联结词。例如,这些图显示了的pdf和cdfρ= .8:
u1 = linspace (1 e - 3 1-1e-3 50);u2 = linspace (1 e - 3 1-1e-3 50);[U1, U2] = meshgrid (U1, U2);Rho = [1.8;1。8);f = copulapdf (“t”, (U1 (:) U2(:)),ρ,5);f =重塑(f,大小(U1));图冲浪(u1, u2,日志(f),'facecholor','interp','Edgecolor','没有任何')视图([-15,20])包含('U1')ylabel('U2')Zlabel('概率密度')
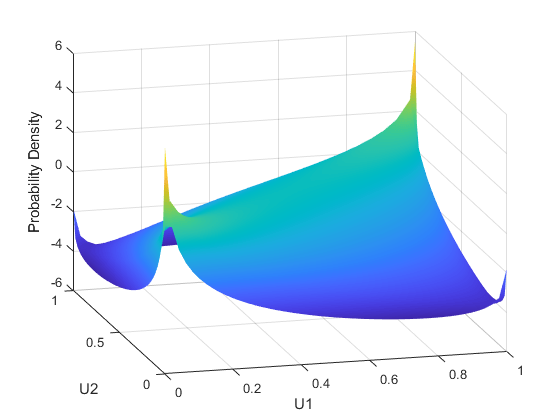
u1 = linspace (1 e - 3 1-1e-3 50);u2 = linspace (1 e - 3 1-1e-3 50);[U1, U2] = meshgrid (U1, U2);F = copulacdf (“t”, (U1 (:) U2(:)),ρ,5);f =重塑(f,尺寸(U1));图()冲浪(U1,U2,F,'facecholor','interp','Edgecolor','没有任何')视图([-15,20])包含('U1')ylabel('U2')Zlabel('累积概率')
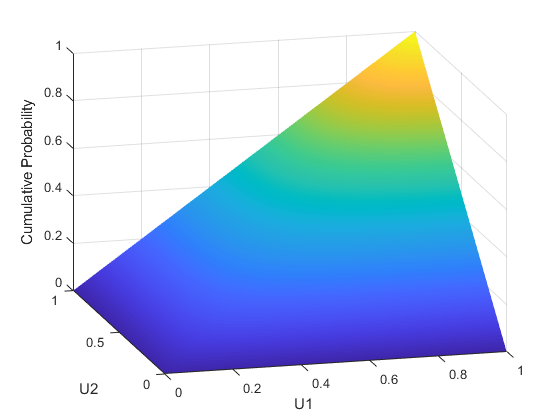
通过从一分偏见开始构建不同的Copulas系列t使用相应的分布和转换tcdf。二元的t分发是参数化的P,线性相关矩阵,和ν,自由度。因此,例如,你可以说一个 或者 copula,基于多变量t分别有一个和五次自由。
就像高斯copula,统计学和机器学习工具箱函数t连系动词计算:
概率密度函数(
Copulapdf.)和累积分配功能(Copulacdf.) 为了t连系动词由线性相关而来的秩相关(
copulastat),反之亦然(copulaparam)随机向量(
copularnd.)适合数据的copula参数(
copulafit)
例如,使用copularnd.函数用于从二元变量中创建随机值的散点图
拷贝拉为各种水平ρ,以说明不同依赖结构的范围:
n = 500;nu = 1;RNG('默认')%的再现性U = copularnd (“t”,[1 .8;.8 1],nu,n);子图(2,2,1)绘图(U(:,1),U(:,2),“。”) 标题('{\它\ rho} = 0.8')Xlabel('U1')ylabel('U2')u = copularnd(“t”,[1 .1;.1 1],nu,n);子图(2,2,2)绘图(U(:,1),U(:,2),“。”) 标题(“{\ \ρ}= 0.1”)Xlabel('U1')ylabel('U2')u = copularnd(“t”约[1;-.11],nu,n);子图(2,2,3)绘图(U(:,1),U(:,2),“。”) 标题('{\它\ rho} = -0.1')Xlabel('U1')ylabel('U2')u = copularnd(“t”,(1。8;-.8 1],ν,n);子图(2,2,4)绘图(U(:,1),U(:,2),“。”) 标题('{\它\ rho} = -0.8')Xlabel('U1')ylabel('U2')
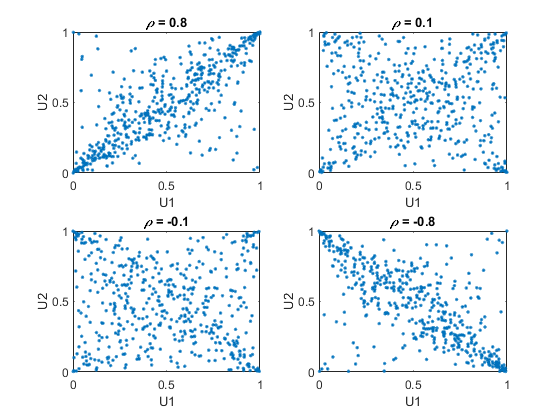
一个tCopula具有均匀的边缘分布U1和U2,就像高斯联系符一样。的等级相关τ.要么
在a中的组件之间tcopula也是相同的功能ρ至于高斯。然而,随着这些地块展示,a
copula与高斯copula有很大的不同,即使它们的成分有相同的秩相关。区别在于它们的依赖结构。不出所料,作为自由度参数
是更大的,一个
copula趋向于相应的高斯copula。
与高斯关联函数一样,任意的边际分布都可以加在t连系动词。例如,使用atcopula与一个自由度,你可以再次从一个二元分布生成随机向量与(2,1)和
边缘使用copularnd.:
n = 1000;rho = .7;nu = 1;RNG('默认')%的再现性U = copularnd (“t”,(1ρ;ρ1],ν,n);X = [gaminv(U(:,1),2,1) tinv(U(:,2),5)];图scatterhist (X (: 1), (:, 2),“方向”,'出去')
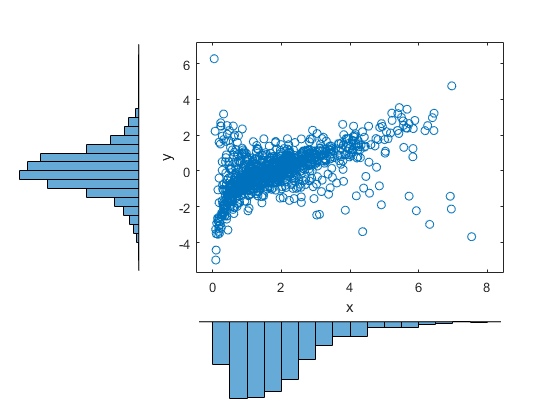
与双变量Gamma/相比t先前构造的分布,基于高斯谱系,该分布在此基于a Copula,具有相同的边际分布和变量之间的等级相关性,但依赖结构非常不同。这说明了多变量分布不是由边缘分布的唯一定义,或者通过它们的相关性。应用中的特定谱系的选择可以基于实际观察到的数据,或者可以使用不同的Copulas作为确定模拟结果对输入分布的灵敏度的方式。
更高的维度金属贴花
高斯和t连杆称为椭圆连杆。很容易将椭圆联结推广到更高的维数。例如,用Gamma(2,1)、Beta(2,2)和
使用高斯谱系的边缘copularnd., 如下:
n = 1000;rho = [1 .4 .2;.4 1 -.8;.2 -.8 1];RNG('默认')%的再现性U = copularnd ('高斯',rho,n);x = [gaminv(u(:,1),2,1)贝纳韦(U(:,2),2,2)Tinv(U(:,3),5)];
绘制数据。
次要情节(1 1 1)plot3 (X (: 1), (:, 2), X (:, 3),“。”) 网格在查看([ - 55,15])xlabel(X1的)ylabel('x2')Zlabel('x3')
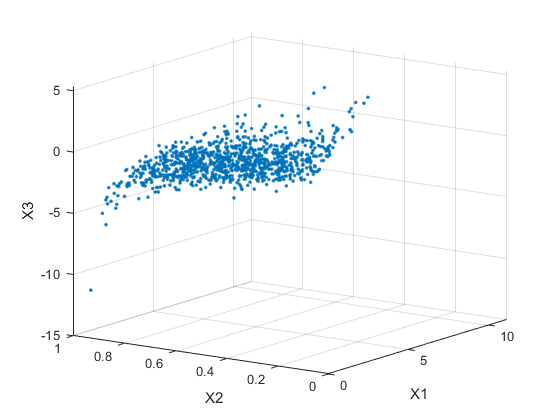
注意线性相关参数之间的关系ρ而且,例如,肯德尔的τ.,对于相关矩阵中的每一项都成立P这里使用。你可以验证数据的样本秩相关性近似等于理论值:
tautheorate = 2. * Asin(rho)./ pi
tautheoratic =.3×31.0000 0.2620 0.1282 0.2620 1.0000 0.5903 0.1282 0.5903 1.0000
tausample = cor(x,'类型','肯德尔')
tausample =3×31.0000 0.2581 0.1414 0.2581 1.0000 0.5790 0.1414 -0.5790 1.0000
阿基米德连系动词
统计和机器学习工具箱功能适用于三个二佛亚州Archimedean Copula系列:
Clayton Copulas.
弗兰克金普拉斯
Gumbel Copulas.
这些是在CDF方面直接定义的一个参数系列,而不是使用标准多变量分布的建设性地定义。
将这三个Archimedean Copulas比较到高斯和高斯和t二元copula,首先使用copulastat函数来寻找高斯或t用线性相关参数为0.8的Copula,然后用copulaparam函数,以找到与该等级相关性相对应的Clayton copula参数:
τ= copulastat ('高斯',.8 ,'类型','肯德尔')
τ= 0.5903
alpha = copulaparam('克莱顿',tau,'类型','肯德尔')
alpha = 2.8820.
最后,从克莱顿的联系图中随机抽取一个样本copularnd..重复弗兰克和Gumbel Copulas的相同程序:
n = 500;U = copularnd ('克莱顿',alpha,n);子图(3,1,1)绘图(U(:,1),U(:,2),“。”);标题(['Clayton Copula,{\ it \ alpha} =',Sprintf('%0.2f',alpha)])xlabel('U1')ylabel('U2') alpha = copulaparam('坦率',tau,'类型','肯德尔');U = copularnd ('坦率',alpha,n);子图(3,1,2)绘图(U(:,1),U(:,2),“。”) 标题(['弗兰克copula,{\它\ alpha} =',Sprintf('%0.2f',alpha)])xlabel('U1')ylabel('U2') alpha = copulaparam('gumbel',tau,'类型','肯德尔');U = copularnd ('gumbel',alpha,n);子图(3,1,3)绘图(U(:,1),U(:,2),“。”) 标题(['gumbel copula,{\ it \ alpha} =',Sprintf('%0.2f',alpha)])xlabel('U1')ylabel('U2')
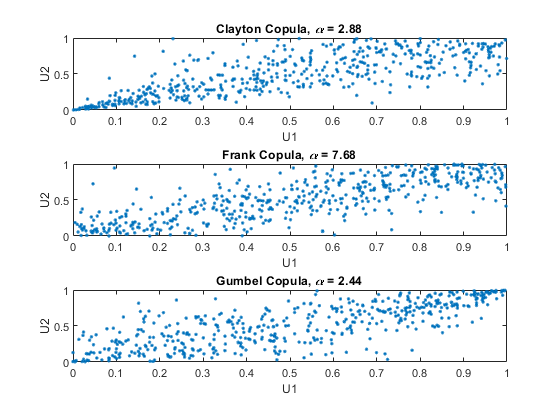
用copula模拟相关的多元数据
要使用copula模拟依赖多变量数据,必须指定以下每个:
Copula系列(以及任何形状参数)
变量之间的等级相关性
每个变量的边缘分布
假设您有两个股票的返回数据,并希望运行一个蒙特卡罗模拟,其输入遵循与数据相同的分布:
加载stockreturnsnobs =尺寸(股票,1);子图(2,1,1)直方图(库存(:,1),10,'facecholor',[。8 .8 1])XLIM([ - 3.5 3.5])XLabel(X1的)ylabel('频率')子图(2,1,2)直方图(库存(:,2),10,'facecholor',[。8 .8 1])XLIM([ - 3.5 3.5])XLabel('x2')ylabel('频率')
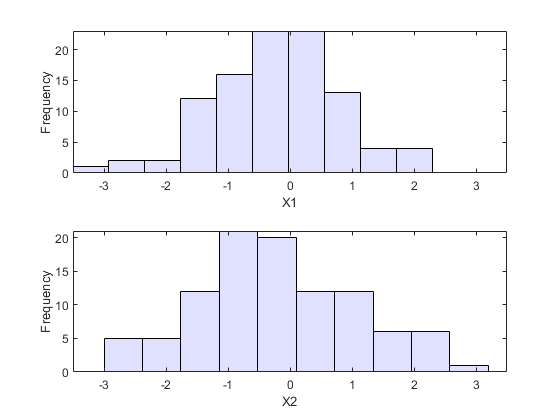
您可以将参数模型分别适合每个数据集,并使用这些估计作为边际分布。然而,参数模型可能不具有足够的灵活性。相反,您可以使用非参数模型转换为边缘分布。所需要的只是一种计算非参数模型的反义CDF的方法。
最简单的非参数模型是经验的CDF,由此计算ecdf.功能。对于离散边际分布,这是合适的。但是,对于连续分布,使用比计算的阶梯函数更平滑的模型ecdf..一种方法是估计经验cdf,并用分段线性函数在步骤的中点之间进行插值。另一种方法是使用核平滑ksdity.例如,将经验cdf与第一个变量的核平滑cdf估计进行比较:
[fi,xi] = ecdf(股票(:1));图()楼梯(xi,fi,“b”,“线宽”,2)持有在fi_sm = ksdenty(库存(:,1),xi,'功能','CDF','宽度',酒精含量);绘图(xi,fi_sm,的r -,“线宽”(1.5)包含X1的)ylabel('累积概率')传说('经验',“平滑”,'地点','nw') 网格在
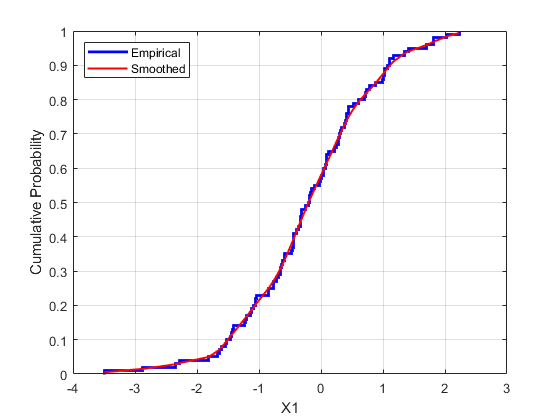
用于模拟,用不同的Copulas和相关性进行实验。在这里,您将使用一分匹配tCopula具有相当小的自由参数。对于关联参数,您可以计算数据的等级相关性。
nu = 5;tau = erc(股票(:,1),股票(:,2),'类型','肯德尔')
Tau = 0.5180.
找到相应的线性相关参数tcopula使用copulaparam.
rho = copulaparam(“t”τ,ν,'类型','肯德尔')
rho = 0.7268.
接下来,使用copularnd.来生成随机值tCopula和变换使用非参数逆cdfs。的ksdity函数允许你在一个步骤中对分布进行核估计,并评估copula点的反CDF:
n = 1000;U = copularnd (“t”,(1ρ;ρ1],ν,n);X1 = ksdensity(股票(:1),U (: 1),...'功能',“icdf”,'宽度',酒精含量);X2 = ksdensity(股票(:,2),U (:, 2),...'功能',“icdf”,'宽度',酒精含量);
或者,当您有大量数据或需要模拟一组以上的值时,在区间内的值网格上计算反cdf可能更有效(0,1)并使用插值来计算copula点上的值:
p = linspace(0.00001,0.99999,1000);G1 = ksdenty(库存(:,1),p,'功能',“icdf”,'宽度', 0.15);x1 = Interp1(p,g1,u(:,1),'样条曲线');G2 = ksdenty(股票(:,2),p,'功能',“icdf”,'宽度', 0.15);X2 = interp1 (p, G2 U (:, 2),'样条曲线');散点图(x1,x2,“方向”,'出去')
模拟数据的边缘直方图是原始数据的直方图的平滑版本。平滑量由带宽输入控制ksdity.
拟合COPULAS到数据
这个例子展示了如何使用copulafit用数据校准连接图。生成数据XSIM.分布“就像”(在边际分布和相关性方面)矩阵中的数据分发X,你需要将边缘分布与X,使用适当的CDF函数进行转换X来U,所以U有0到1之间的值,使用copulafit使联系符适合于U,生成新数据Usim从copula,并使用适当的反CDF函数进行变换Usim来XSIM..
加载并绘制模拟的股票回报数据。
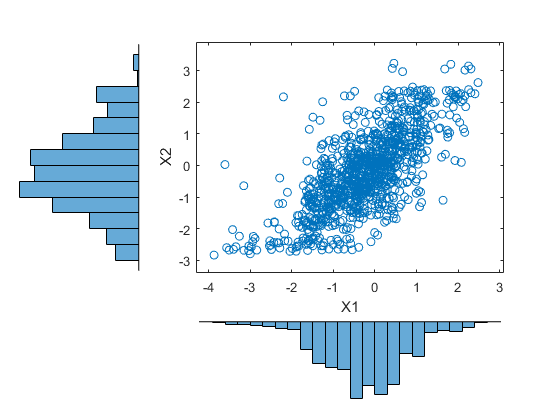
加载stockreturnsX =股票(:,1);Y =股票(:,2);散点图(x,y,“方向”,'出去')
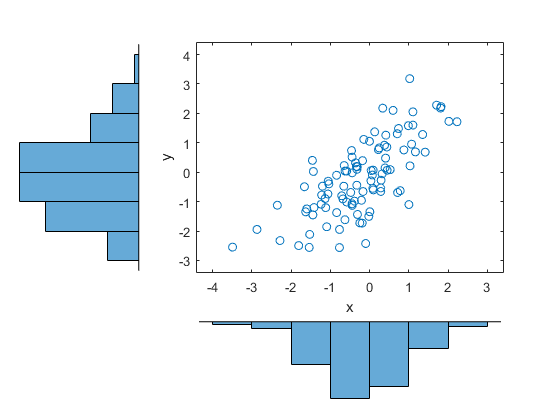
使用累积分布函数的内核估计器将数据转换为copula秤(单位方形)。
u = ksdensity (x, x,'功能','CDF');v = ksdenty(y,y,'功能','CDF');散点图(U,V,“方向”,'出去')Xlabel('U')ylabel('v')
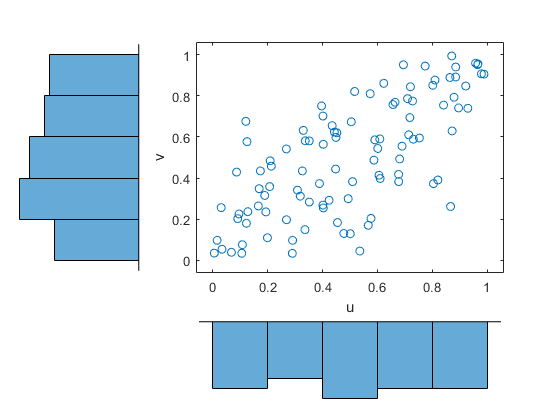
适合A.t连系动词。
[rho,nu] = copulafit(“t”(u v),“方法”,“ApproximateML”)
rho =2×21.0000 0.7220 0.7220 1.0000
nu = 3.2727e + 06
生成一个随机样本t连系动词。
r = copularnd(“t”,rho,nu,1000);U1 = R(:,1);v1 = r(:,2);散点图(U1,V1,“方向”,'出去')Xlabel('U')ylabel('v'甘氨胆酸)组(get (,“孩子”),“标记”,“。”)
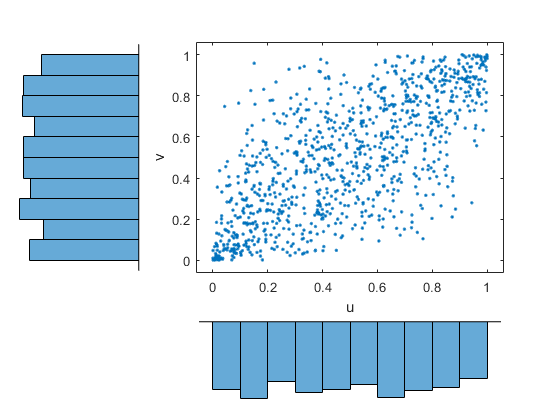
将随机样本转换回数据的原始比例。
x1 = ksdenty(x,u1,'功能',“icdf”);日元= ksdensity (y, v1,'功能',“icdf”);scatterhist (x1, y1,“方向”,'出去'甘氨胆酸)组(get (,“孩子”),“标记”,“。”)
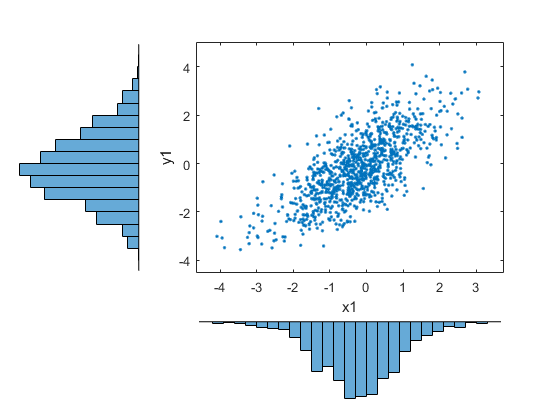
如例子所示,copula与其他分布拟合函数自然结合。
另请参阅
Copulacdf.|copulafit|copulaparam|Copulapdf.|copularnd.|copulastat
相关话题
您还可以从以下列表中选择一个网站:
