COPULAFIT.
适合数据
句法
描述
___= copulafit(___那返回任何以前的语法,其中一个或多个指定的其他选项名称,价值)名称,价值对论点。例如,您可以使用选项结构指定要计算的置信区间来计算或指定迭代参数估计算法的控制参数。
例子
适合A.T.copula到数据
负载和绘图模拟库存退回数据。
加载储存者X =股票(:,1);Y =股票(:,2);数字;散点图(x,y)

使用累积分布函数的内核估计器将数据转换为copula秤(单位方形)。
u = ksdenty(x,x,'功能'那'CDF');v = ksdenty(y,y,'功能'那'CDF');数字;散点图(U,V)Xlabel('U')ylabel('v')
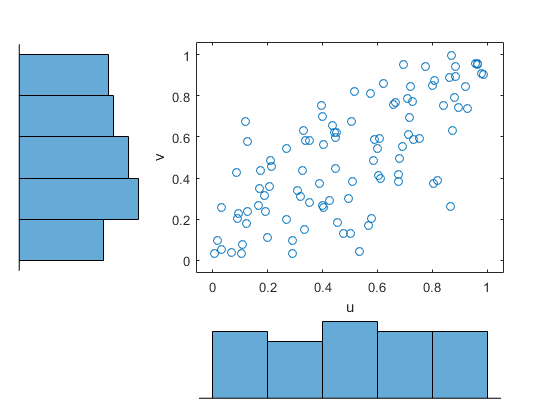
适合A.T.copula到数据。
RNG.默认重复性的%[rho,nu] = copulafit('T',[紫外线],'方法'那'近似值')
RHO = 1.0000 0.7220 0.7220 1.0000 NU = 3.2017E + 06
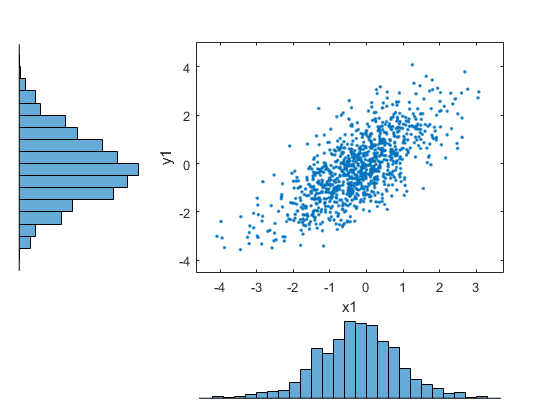
从中生成随机样本T.系词。
r = copularnd('T',rho,nu,1000);U1 = R(:,1);v1 = r(:,2);数字;散点图(U1,v1)xlabel('U')ylabel('v')设置(get(gca,'孩子们'),'标记'那'。')

将随机样本转换回数据的原始比例。
x1 = ksdenty(x,u1,'功能'那'ICDF');Y1 = ksdenty(y,v1,'功能'那'ICDF');数字;散点图(x1,y1)设置(get(gca,'孩子们'),'标记'那'。')
输入参数
输出参数
算法
默认,COPULAFIT.使用最大可能性来适应谱系你。什么时候你包含通过参数估计其边缘累积分布函数的参数估计转换为单元超级别的数据,这被称为利润率推断功能(IFM)方法。什么时候你包含由经验CDF转换的数据(参见ecdf.),这被称为规范最大可能性(CML)。
参考
[1]Bouyé,E.,V.Durrleman,A.Nikeghbali,G. Riboulet和T. Roncalli。“金融金融:阅读指南和一些应用。”工作文件。Groupe de RechercheOpélationnelle,CréditLyonnais,巴黎,2000年。
在R2007B中介绍
您还可以从以下列表中选择一个网站:
