回归学习程序中的超参数优化
选择要训练的特定类型的模型(例如决策树或支持向量机(SVM))后,可以通过选择不同的高级选项来调整模型。例如,可以更改决策树的最小叶大小或SVM的框约束。其中一些选项是模型的万博1manbetx内部参数或超参数,可能会严重影响其性能。您可以在回归学习器应用程序中使用超参数优化来自动选择超参数值,而不是手动选择这些选项。对于给定的模型类型,应用程序通过使用优化方案尝试超参数值的不同组合,该优化方案寻求最小化模型均方误差(MSE),并返回具有优化超参数的模型。可以像使用任何其他经过训练的模型一样使用生成的模型。
笔记
由于超参数优化可能导致模型过度拟合,建议的方法是在将数据导入回归学习应用程序之前创建一个单独的测试集。在训练可优化模型后,您可以看到它在测试集上的表现。例如,请参见在回归学习程序中使用超参数优化训练回归模型.
要在回归学习器中执行超参数优化,请执行以下步骤:
选择要优化的超参数
在回归学习者应用中,在模型类型部分回归的学习者选项卡,单击箭头以打开图库。该图库包括可优化的模型,您可以使用超参数优化对其进行培训。
选择一个可优化模型后,可以选择要优化的超参数。在模型类型部分中,选择高级>高级.应用程序会打开一个对话框,你可以在其中进行选择优化要优化的超参数的复选框。在下面价值观,为不希望优化或不可优化的超参数指定固定值。
该表描述了可以针对每种模型类型进行优化的超参数,以及每个超参数的搜索范围。它还包括额外的超参数,您可以为其指定固定值。
| 模型 | Optimizable Hyperparameters | 额外Hyperparameters | 笔记 |
|---|---|---|---|
| 可优化树 |
|
|
有关更多信息,请参见高级回归树选项. |
| Optimizable支持向量机 |
|
有关更多信息,请参见高级SVM选项. |
|
| Optimizable探地雷达 |
|
|
有关更多信息,请参见高级高斯过程回归选项. |
| 可优化系综 |
|
有关更多信息,请参见高级合奏选项. |
优化选项
默认情况下,回归学习器应用程序通过使用贝叶斯优化执行超参数调整。贝叶斯优化和一般优化的目标是找到一个使目标函数最小化的点。在应用程序中的超参数调整上下文中,一个点是一组超参数值,目标函数是损失函数或均方误差(MSE)。有关贝叶斯优化基础知识的更多信息,请参见贝叶斯优化工作流程.
您可以指定如何执行超参数调优。例如,可以将优化方法改为网格搜索或限制训练时间。在回归的学习者选项卡,模型类型部分中,选择高级>优化选项. 应用程序将打开一个对话框,您可以在其中选择优化选项。
该表描述了可用的优化选项及其默认值。
| 选项 | 描述 |
|---|---|
| 优化器 | 优化器的值是:
|
| 获取函数 | 当应用程序对超参数进行贝叶斯优化调优时,它使用获取函数确定下一组超参数值进行尝试。 获取函数值为:
有关这些获取功能如何在贝叶斯优化上下文中工作的详细信息,请参见采集功能类型. |
| 迭代 | 每次迭代都对应于应用程序尝试的超参数值的组合。当您使用贝叶斯优化或随机搜索时,请指定一个设置迭代次数的正整数。默认值为 使用网格搜索时,应用程序会忽略迭代计算并评估整个网格中每个点的损耗。您可以设置培训时间限制以提前停止优化过程。 |
| 训练时限 | 要设置培训时间限制,请选择此选项并设置最大训练时间,以秒为单位选择。默认情况下,应用程序没有训练时间限制。 |
| 最大训练时间,以秒为单位 | 将训练时间限制(以秒为单位)设置为正实数。默认值为300.运行时间可能会超过训练时间限制,因为这个限制不会中断迭代计算。 |
| 网格分区数 | 当您使用网格搜索时,设置一个正整数作为应用程序为每个数值超参数尝试的值的数量。对于分类超参数,应用程序忽略这个值。默认值为10. |
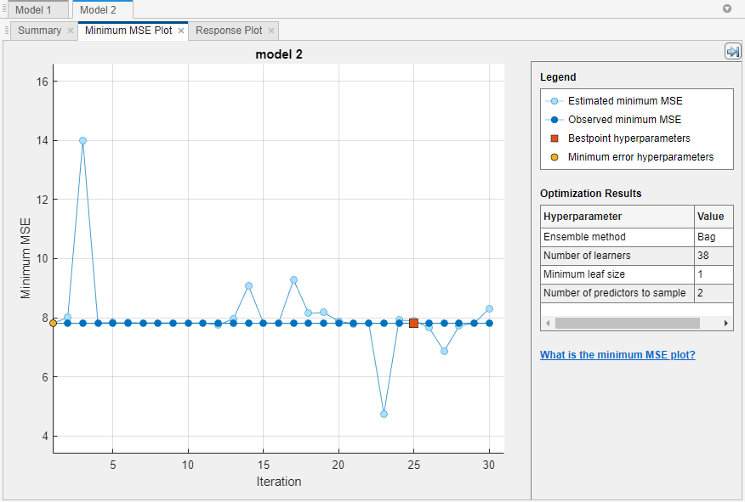
最小均方误差图
在指定要优化的模型超参数和设置任何额外的优化选项(可选)之后,训练可优化的模型。在回归的学习者选项卡,培训部分中,点击火车.应用程序创建一个最小均方误差图它会随着优化的运行而更新。
笔记
当你训练一个可优化的模型时,应用程序会禁用使用并行按钮。培训完成后,当您选择一个不可优化的模型时,应用程序使按钮再次可用。该按钮默认关闭。
最小均方误差(MSE)图显示了以下信息:
最小均方误差估计–当考虑到目前为止尝试的所有超参数值集(包括当前迭代)时,每个浅蓝色点对应于优化过程计算的最小MSE估计值。
估计是基于当前MSE目标模型的上置信区间,如上文所述最佳点超参数描述。
如果你使用网格搜索或随机搜索来执行超参数优化,应用程序不会显示这些浅蓝色的点。
观察到的最小均方误差-每个深蓝色点对应的是到目前为止通过优化过程计算到的观测到的最小MSE。例如,在第三次迭代时,蓝色点对应于在第一次、第二次和第三次迭代中观测到的MSE的最小值。
最佳点超参数–红方块表示与优化超参数对应的迭代。您可以在下的绘图右上角找到列出的优化超参数值优化结果.
优化的超参数并不总是提供观测到的最小均方误差。当应用程序使用贝叶斯优化执行超参数优化时(请参阅优化选项(简单介绍),它选择最小化MSE目标模型的上置信区间的超参数值集合,而不是最小化MSE的集合。有关更多信息,请参阅
“标准”、“min-visited-upper-confidence-interval”的名称-值对参数bestPoint.最小误差hyperparameters—黄点表示对应于产生观测最小MSE的超参数的迭代。
有关更多信息,请参阅
“标准”,“最小观察值”的名称-值对参数bestPoint.如果使用网格搜索执行超参数优化,则最佳点超参数和最小误差hyperparameters都是一样的。
图中缺失的点对应于楠最小均方误差值。
优化结果
当应用程序完成模型超参数的调优时,它返回一个用优化过的超参数值训练过的模型(最佳点超参数).模型度量、显示的图形和导出的模型对应于这个具有固定超参数值的训练模型。
为了检查经过训练的可优化模型的优化结果,在模型看看窗格当前模型的总结窗格。
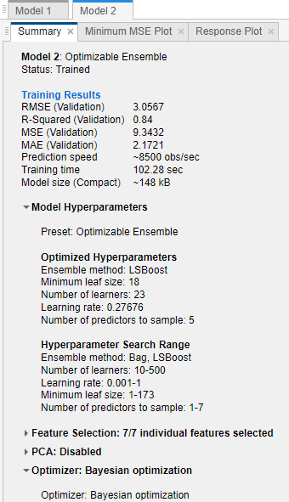
这个当前模型的总结窗格包括以下部分:
培训结果–显示可优化模型的性能。看见查看和比较模型统计信息
模型类型-显示可优化模型的类型,并列出任何固定的超参数值
优化Hyperparameters–列出优化超参数的值
Hyperparameter搜索范围—显示优化后超参数的搜索范围
优化器选项–显示选定的优化器选项
当您使用贝叶斯优化执行超参数调优,并将训练有素的可优化模型作为结构导出到工作空间时,该结构包括BayesianOptimization对象HyperParameterOptimizationResult字段。对象包含应用程序中执行的优化结果。
当你生成MATLAB时®代码来自训练有素的可优化模型,生成的代码使用模型的固定和优化超参数值对新数据进行训练。生成的代码不包括优化过程。有关在使用拟合函数时如何执行贝叶斯优化的信息,请参见使用拟合函数的贝叶斯优化.
相关的话题
你也可以从以下列表中选择一个网站:
