nlmefitgydF4y2Ba
非线性mixed-effects估计gydF4y2Ba
语法gydF4y2Ba
β= nlmefit (X, y,, V,有趣,beta0)gydF4y2Ba
(β,PSI) = nlmefit (X, y,, V,有趣,beta0)gydF4y2Ba
-β,PSI,统计] = nlmefit(X,Y,组,V,乐趣,beta0)gydF4y2Ba
-β,PSI,统计数据,B] = nlmefit(X,Y,组,V,乐趣,beta0)gydF4y2Ba
(β,PSI,统计数据,B) = nlmefit (X, y,, V,有趣,beta0,”gydF4y2Ba的名字gydF4y2Ba',gydF4y2Ba价值gydF4y2Ba)gydF4y2Ba
描述gydF4y2Ba
β= nlmefit (X, y,, V,有趣,beta0)gydF4y2Ba拟合一个非线性混合效应回归模型和收益估计的固定效应gydF4y2Ba公测gydF4y2Ba。默认情况下,gydF4y2BanlmefitgydF4y2Ba适合的模型,其中每个参数是一个固定的和随机效应的总和,和随机效应是不相关的(它们的协方差矩阵是对角线)。gydF4y2Ba
XgydF4y2Ba是一个gydF4y2BangydF4y2Ba——- - - - - -gydF4y2BahgydF4y2Ba矩阵的gydF4y2BangydF4y2Ba观察gydF4y2BahgydF4y2Ba预测因子。gydF4y2Ba
ygydF4y2Ba是一个gydF4y2BangydF4y2Ba响应向量的-乘1。gydF4y2Ba
集团gydF4y2Ba分组变量是否指示gydF4y2Ba米gydF4y2Ba观察组。gydF4y2Ba集团gydF4y2Ba是分类变量,数字载体,具有行组名,一个字符串数组,或字符向量的单元阵列的字符矩阵。有关分组变量的更多信息,请参阅gydF4y2Ba分组变量gydF4y2Ba。gydF4y2Ba
VgydF4y2Ba是一个gydF4y2Ba米gydF4y2Ba——- - - - - -gydF4y2BaggydF4y2Ba的矩阵或单元数组gydF4y2BaggydF4y2Ba特定组的预测因子。这些是采取一组中的所有观测值相同的预测。的行gydF4y2BaVgydF4y2Ba被分配到组使用gydF4y2Bagrp2idxgydF4y2Ba,根据所述顺序指定由gydF4y2Bagrp2idx(集团)gydF4y2Ba。使用单元格数组gydF4y2BaVgydF4y2Ba如果群体预测因子在不同群体中大小不同。使用gydF4y2Ba[]gydF4y2Ba为gydF4y2BaVgydF4y2Ba如果没有群体特有的预测因子。gydF4y2Ba
开玩笑gydF4y2Ba是一个函数的句柄,该函数接受预测值和模型参数,并返回符合的值。gydF4y2Ba开玩笑gydF4y2Ba的形式gydF4y2Ba
yfit = modelfun(φ,XFUN VFUN)gydF4y2Ba
的参数是:gydF4y2Ba
PHIgydF4y2Ba- A 1逐gydF4y2BapgydF4y2Ba模型参数向量。gydF4y2BaXFUNgydF4y2Ba——一个gydF4y2BakgydF4y2Ba——- - - - - -gydF4y2BahgydF4y2Ba预测器,其中的阵列:gydF4y2BakgydF4y2Ba= 1,如果gydF4y2Ba
XFUNgydF4y2Ba是单排gydF4y2BaXgydF4y2Ba。gydF4y2BakgydF4y2Ba=gydF4y2BangydF4y2Ba我gydF4y2Ba如果gydF4y2Ba
XFUNgydF4y2Ba包含gydF4y2BaXgydF4y2Ba对于一个单一群体的规模gydF4y2BangydF4y2Ba我gydF4y2Ba。gydF4y2BakgydF4y2Ba=gydF4y2BangydF4y2Ba如果gydF4y2Ba
XFUNgydF4y2Ba包含gydF4y2BaXgydF4y2Ba。gydF4y2Ba
VFUNgydF4y2Ba-由其中一个给出的群特异性预测因子:gydF4y2BaA 1逐gydF4y2BaggydF4y2Ba向量对应于的单个组和单个行gydF4y2Ba
VgydF4y2Ba。gydF4y2Ba一个gydF4y2BangydF4y2Ba——- - - - - -gydF4y2BaggydF4y2Ba数组,gydF4y2BajgydF4y2Ba第一行是V(gydF4y2Ba
我gydF4y2Ba:)如果gydF4y2BajgydF4y2Ba观察是分组的gydF4y2Ba我gydF4y2Ba。gydF4y2Ba
如果gydF4y2Ba
VgydF4y2Ba是空的,gydF4y2BanlmefitgydF4y2Ba调用gydF4y2BamodelfungydF4y2Ba只有两个输入。gydF4y2BayfitgydF4y2Ba——一个gydF4y2BakgydF4y2Ba拟合值的-1乘1向量gydF4y2Ba
当gydF4y2BaPHIgydF4y2Ba要么gydF4y2BaVFUNgydF4y2Ba包含单个行,它对应于其他两个输入参数的所有行。gydF4y2Ba
请注意gydF4y2Ba
如果gydF4y2BamodelfungydF4y2Ba可以计算gydF4y2BayfitgydF4y2Ba对于每个调用的多个模型参数向量,使用gydF4y2Ba“矢量”gydF4y2Ba参数(稍后描述)以改进性能。gydF4y2Ba
beta0gydF4y2Ba是一个gydF4y2Ba问gydF4y2Ba的-乘1向量的初始估计gydF4y2Ba问gydF4y2Ba固定效应。默认情况下,gydF4y2Ba问gydF4y2Ba是模型参数的数gydF4y2BapgydF4y2Ba。gydF4y2Ba
nlmefitgydF4y2Ba拟合模型,最大限度逼近积分出随机效应的边际似然值,假设:gydF4y2Ba
随机效应是多变量正态分布,组间独立。gydF4y2Ba
观测误差是独立的,相同的正态分布,以及独立的随机效应。gydF4y2Ba
(β,PSI) = nlmefit (X, y,, V,有趣,beta0)gydF4y2Ba同样的回报gydF4y2BaψgydF4y2Ba,一个gydF4y2BargydF4y2Ba——- - - - - -gydF4y2BargydF4y2Ba估计协方差矩阵的随机效应。默认情况下,gydF4y2BargydF4y2Ba等于模型参数的数量gydF4y2BapgydF4y2Ba。gydF4y2Ba
-β,PSI,统计] = nlmefit(X,Y,组,V,乐趣,beta0)gydF4y2Ba同样的回报gydF4y2Ba统计gydF4y2Ba,一个带有字段的结构:gydF4y2Ba
教育部gydF4y2Ba- 该模型的误差自由度gydF4y2BaloglgydF4y2Ba- 最大化的对数似然拟合模型gydF4y2BaRMSEgydF4y2Ba- 所估计的误差方差的平方根(计算上为对数标度gydF4y2Ba指数gydF4y2Ba误差模型)gydF4y2BaerrorparamgydF4y2Ba-误差方差模型的估计参数gydF4y2BaAICgydF4y2Ba- Akaike信息标准,计算为gydF4y2BaAICgydF4y2Ba= 2 *gydF4y2BaloglgydF4y2Ba+ 2 *gydF4y2BanumParamgydF4y2Ba,在那里gydF4y2BanumParamgydF4y2Ba是拟合参数,包括自由度为的随机效应的协方差矩阵,固定效应的数目和误差模型的参数的数目的数目,并且gydF4y2BaloglgydF4y2Ba字段是在gydF4y2Ba统计gydF4y2Ba结构体gydF4y2BabicgydF4y2Ba- 贝叶斯信息准则,计算为gydF4y2BabicgydF4y2Ba= 2 *gydF4y2BaloglgydF4y2Ba+日志(gydF4y2Ba米gydF4y2Ba)*gydF4y2BanumParamgydF4y2Ba米gydF4y2Ba是组数。gydF4y2BanumParamgydF4y2Ba和gydF4y2BaloglgydF4y2Ba被定义为在gydF4y2BaAICgydF4y2Ba。gydF4y2Ba
注意,一些文献表明gydF4y2Ba
bicgydF4y2Ba应该是,gydF4y2BabicgydF4y2Ba= 2 *gydF4y2BaloglgydF4y2Ba+日志(gydF4y2BaNgydF4y2Ba)*gydF4y2BanumParamgydF4y2Ba,在那里gydF4y2BaNgydF4y2Ba为观测次数。gydF4y2BacovbgydF4y2Ba-估计的协方差矩阵的参数估计gydF4y2BasebetagydF4y2Ba-的标准误差gydF4y2Ba公测gydF4y2Ba忿怒gydF4y2Ba-人口残差gydF4y2Ba(y-y_population)gydF4y2Ba,在那里gydF4y2Bay_populationgydF4y2Ba个体的预测值是多少gydF4y2BaPRESgydF4y2Ba-人口残差gydF4y2Ba(y-y_population)gydF4y2Ba,在那里gydF4y2Bay_populationgydF4y2Ba人口是预测值吗gydF4y2BaiwresgydF4y2Ba-个别加权残差gydF4y2Ba压水式反应堆gydF4y2Ba-人口加权残差gydF4y2BacwresgydF4y2Ba-条件加权残差gydF4y2Ba
-β,PSI,统计数据,B] = nlmefit(X,Y,组,V,乐趣,beta0)gydF4y2Ba同样的回报gydF4y2BaBgydF4y2Ba,一个gydF4y2BargydF4y2Ba——- - - - - -gydF4y2Ba米gydF4y2Ba的所估计的随机效应矩阵gydF4y2Ba米gydF4y2Ba组。默认情况下,gydF4y2BargydF4y2Ba等于模型参数的数量gydF4y2BapgydF4y2Ba。gydF4y2Ba
(β,PSI,统计数据,B) = nlmefit (X, y,, V,有趣,beta0,”gydF4y2Ba指定一个或多个可选参数名称/值对。指定gydF4y2Ba的名字gydF4y2Ba',gydF4y2Ba价值gydF4y2Ba)gydF4y2Ba的名字gydF4y2Ba里面的单引号。gydF4y2Ba
使用以下参数来适应不同于默认值的模型。(通过设置两者获得默认模型gydF4y2BaFEConstDesigngydF4y2Ba和gydF4y2BaREConstDesigngydF4y2Ba来gydF4y2Ba眼(p)gydF4y2Ba或由两者设置gydF4y2BaFEParamsSelectgydF4y2Ba和gydF4y2BaREParamsSelectgydF4y2Ba来gydF4y2Ba1: pgydF4y2Ba)。参数最多只能使用一个gydF4y2Ba'FE'gydF4y2Ba前缀和一个参数gydF4y2Ba“重新”gydF4y2Ba前缀。的gydF4y2BanlmefitgydF4y2Ba功能需要至少指定一个固定的效果和一个随机效应。gydF4y2Ba
| 参数gydF4y2Ba | 值gydF4y2Ba |
|---|---|
FEParamsSelectgydF4y2Ba |
一个向量,指定参数向量的哪些元素gydF4y2Ba |
FEConstDesigngydF4y2Ba |
一个gydF4y2BapgydF4y2Ba——- - - - - -gydF4y2Ba问gydF4y2Ba设计矩阵gydF4y2Ba |
FEGroupDesigngydF4y2Ba |
一个gydF4y2BapgydF4y2Ba——- - - - - -gydF4y2Ba问gydF4y2Ba——- - - - - -gydF4y2Ba米gydF4y2Ba数组指定不同的gydF4y2BapgydF4y2Ba——- - - - - -gydF4y2Ba问gydF4y2Ba每个固定效果设计矩阵gydF4y2Ba米gydF4y2Ba组。gydF4y2Ba |
FEObsDesigngydF4y2Ba |
一个gydF4y2BapgydF4y2Ba——- - - - - -gydF4y2Ba问gydF4y2Ba——- - - - - -gydF4y2BangydF4y2Ba数组指定不同的gydF4y2BapgydF4y2Ba——- - - - - -gydF4y2Ba问gydF4y2Ba每个固定效果设计矩阵gydF4y2BangydF4y2Ba观察。gydF4y2Ba |
REParamsSelectgydF4y2Ba |
一个向量,指定参数向量的哪些元素gydF4y2Ba |
REConstDesigngydF4y2Ba |
一个gydF4y2BapgydF4y2Ba——- - - - - -gydF4y2BargydF4y2Ba设计矩阵gydF4y2Ba |
REGroupDesigngydF4y2Ba |
一个gydF4y2BapgydF4y2Ba——- - - - - -gydF4y2BargydF4y2Ba——- - - - - -gydF4y2Ba米gydF4y2Ba数组指定不同的gydF4y2BapgydF4y2Ba——- - - - - -gydF4y2BargydF4y2Ba随机效应设计矩阵为每个gydF4y2Ba米gydF4y2Ba组。gydF4y2Ba |
REObsDesigngydF4y2Ba |
一个gydF4y2BapgydF4y2Ba——- - - - - -gydF4y2BargydF4y2Ba——- - - - - -gydF4y2BangydF4y2Ba数组指定不同的gydF4y2BapgydF4y2Ba——- - - - - -gydF4y2BargydF4y2Ba随机效应设计矩阵为每个gydF4y2BangydF4y2Ba观察。gydF4y2Ba |
使用以下参数来控制迭代算法来最大化似然值:gydF4y2Ba
参数gydF4y2Ba |
值gydF4y2Ba |
|---|---|
RefineBeta0gydF4y2Ba |
决定gydF4y2Ba |
ErrorModelgydF4y2Ba |
字符向量或标量的字符串指定误差项的形式。默认值是gydF4y2Ba
如果给定此参数,则输出gydF4y2Ba
|
ApproximationTypegydF4y2Ba |
用来近似模型的可能性的方法。的选择是:gydF4y2Ba
|
向量化gydF4y2Ba |
参数的可接受大小gydF4y2Ba
|
CovParameterizationgydF4y2Ba |
指定内部用于缩放协方差矩阵的参数化。的选择是gydF4y2Ba |
CovPatterngydF4y2Ba |
指定一个gydF4y2BargydF4y2Ba——- - - - - -gydF4y2BargydF4y2Ba逻辑或数字矩阵gydF4y2Ba 另外,gydF4y2Ba |
ParamTransformgydF4y2Ba |
一个向量的gydF4y2BapgydF4y2Ba- 值指定的变换函数gydF4y2BafgydF4y2Ba()为每个gydF4y2Ba
|
选项gydF4y2Ba |
返回的窗体的结构gydF4y2Ba
|
OptimFungydF4y2Ba |
指定用于最大化可能性的优化函数。的选择是gydF4y2Ba |
例子gydF4y2Ba
非线性Mixed-Effects模型gydF4y2Ba
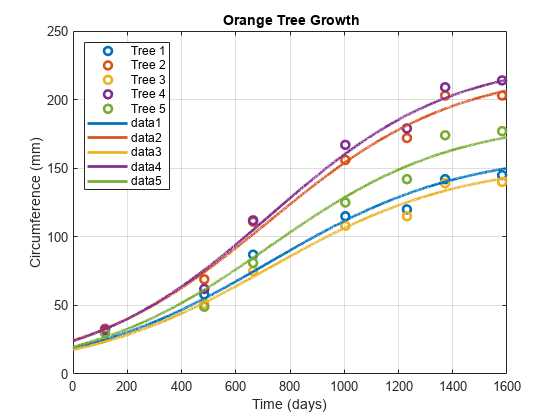
输入和五种橘树生长显示数据。gydF4y2Ba
CIRC = [30 58 87 115 120 142 145;33 69 111 156 172 203 203;30 51 75 108 115 139 140;32 62 112 167 179 209 214;30 49 81 125 142 174 177];时间= [118 484 664 1004 1231 1372 1582];h =情节(时间,保监会”,gydF4y2Ba“o”gydF4y2Ba,gydF4y2Ba“线宽”gydF4y2Ba2);包含(gydF4y2Ba“时间(天)”gydF4y2Ba)ylabel(gydF4y2Ba“圆周(毫米)”gydF4y2Ba)标题(gydF4y2Ba'{\ BF橙树生长}'gydF4y2Ba) ([repmat传奇(gydF4y2Ba“树”gydF4y2Ba5 1) num2str ((1:5) '),gydF4y2Ba…gydF4y2Ba'位置'gydF4y2Ba,gydF4y2Ba'NW'gydF4y2Ba网格)gydF4y2Ba上gydF4y2Ba持有gydF4y2Ba上gydF4y2Ba

使用匿名函数指定逻辑增长模型。gydF4y2Ba
模型= @(PHI,T)(PHI(:,1))./(1 + EXP( - (叔PHI(:,2))./ PHI(:,3)));gydF4y2Ba
使用以下方法拟合模型gydF4y2BanlmefitgydF4y2Ba默认设置(即假设每个参数是一个固定效果和一个随机效果的总和,随机效果之间不存在相关性):gydF4y2Ba
TIME = repmat(时间,5,1);NUMS = repmat((1:5)”,大小(时间));beta0 = [100 100 100]。[β1,PSI1,stats1] = nlmefit(TIME(:),CIRC(:),NUMS(:),gydF4y2Ba…gydF4y2Ba[],模型,beta0)gydF4y2Ba
beta1 =gydF4y2Ba3×1gydF4y2Ba191.3189 723.7608 346.2517gydF4y2Ba
形式=gydF4y2Ba3×3gydF4y2Ba962.1535 0 0 0 0.0000 0 0 0 297.9879gydF4y2Ba
stats1 =gydF4y2Ba同场的结构:gydF4y2BaDFE:28 logl:-131.5457 MSE:59.7882 RMSE:7.9016 errorparam:7.7323 AIC:277.0913 BIC:274.3574 covb:[3×3双]瑟伯塔:[15.2249 33.1579 26.8235] IRES:[35x1双] PRES:[35x1双] iwres:35x1加倍] pwres:[35x1双] cwres:[35x1双]gydF4y2Ba
第二个随机效应的可忽略的方差,gydF4y2Ba的形式(2,2)gydF4y2Ba,建议可以删除它以简化模型。gydF4y2Ba
[β2,PSI2,stats2,B2] = nlmefit(TIME(:),CIRC(:),gydF4y2Ba…gydF4y2Banum(:),[],模型,beta0,gydF4y2Ba“REParamsSelect”gydF4y2Ba1, [3])gydF4y2Ba
beta2 =gydF4y2Ba3×1gydF4y2Ba191.0490 722.5560 344.1624gydF4y2Ba
PSI2 =gydF4y2Ba2×2gydF4y2Ba991.1515 00 0.0000gydF4y2Ba
stats2 =gydF4y2Ba同场的结构:gydF4y2BaDFE:29 logl:-131.5846 MSE:61.5637 RMSE:7.9935 errorparam:7.8463 AIC:275.1692 BIC:272.8258 covb:[3×3双]瑟伯塔:[15.4462 33.6107 25.9579] IRES:[35x1双] PRES:[35x1双] iwres:35x1加倍] pwres:[35x1双] cwres:[35x1双]gydF4y2Ba
b2 =gydF4y2Ba2×5gydF4y2Ba-29.4038 31.5648 -37.0002 40.0183 -5.1791 0.0000 -0.0000 0.0000 -0.0000 -0.0000 -0.0000 -0.0000gydF4y2Ba
在对数似然gydF4y2BaloglgydF4y2Ba, Akaike和Bayesian信息标准(gydF4y2BaAICgydF4y2Ba和gydF4y2BabicgydF4y2Ba)被减少,支持从模型中删除第二万博1manbetx个随机效应的决定。gydF4y2Ba
使用估计的固定效果gydF4y2Baβ2gydF4y2Ba以及每棵树的估计随机效应gydF4y2Bab2gydF4y2Ba通过数据绘制模型。gydF4y2Ba
= repmat(beta2,1,5) +gydF4y2Ba…gydF4y2Ba%的固定效果gydF4y2Ba(b2(1:); 0(1、5);b2 (2:)];gydF4y2Ba%随机效应gydF4y2Batplot = 0:0.1:1600;gydF4y2Ba为gydF4y2Ba我= 1:5 fitted_model = @ (t)(φ(我))。/ (1 + exp (- (t-PHI(我)2)。/gydF4y2Ba…gydF4y2BaPHI(3,I)));图(tplot,fitted_model(tplot)gydF4y2Ba“颜色”gydF4y2Ba中,h(I)。颜色,gydF4y2Ba…gydF4y2Ba“线宽”gydF4y2Ba, 2)gydF4y2Ba结束gydF4y2Ba
参考文献gydF4y2Ba
[1] Lindstrom的,M.J.,和D. M.贝茨。“非线性混合效应模型重复测量数据。”gydF4y2Ba生物识别技术gydF4y2Ba。第46卷,1990年,第673-687页gydF4y2Ba
大卫,M.和D. M.吉尔提南。gydF4y2Ba重复测量数据的非线性模型gydF4y2Ba。纽约:查普曼和霍尔,1995年。gydF4y2Ba
[3] Pinheiro j.c.和d。m。Bates。"非线性混合效应模型中对数似然函数的近似"gydF4y2Ba杂志计算和图形统计gydF4y2Ba。1995年第4卷第12-35页gydF4y2Ba
[4] Demidenko E。gydF4y2Ba混合模型:理论与应用gydF4y2Ba。新泽西州霍博肯:约翰威利父子公司,2004年。gydF4y2Ba
介绍了R2008bgydF4y2Ba
选择网站gydF4y2Ba
选择一个网站,在可用的地方获得翻译内容,并查看当地的活动和优惠。根据您的位置,我们建议您选择:gydF4y2Ba。gydF4y2Ba
选择gydF4y2Ba网站gydF4y2Ba您还可以选择从下面的列表中的网站:gydF4y2Ba
美洲gydF4y2Ba
- 美国拉丁gydF4y2Ba(西班牙语)gydF4y2Ba
- 加拿大gydF4y2Ba(英语)gydF4y2Ba
- 美国gydF4y2Ba(英语)gydF4y2Ba
欧洲gydF4y2Ba
- 比利时gydF4y2Ba(英语)gydF4y2Ba
- 丹麦gydF4y2Ba(英语)gydF4y2Ba
- 德国gydF4y2Ba(德语)gydF4y2Ba
- 西班牙gydF4y2Ba(西班牙语)gydF4y2Ba
- 芬兰gydF4y2Ba(英语)gydF4y2Ba
- 法国gydF4y2Ba(法语)gydF4y2Ba
- 爱尔兰gydF4y2Ba(英语)gydF4y2Ba
- 意大利gydF4y2Ba(意大利语)gydF4y2Ba
- 卢森堡gydF4y2Ba(英语)gydF4y2Ba
- 荷兰gydF4y2Ba(英语)gydF4y2Ba
- 挪威gydF4y2Ba(英语)gydF4y2Ba
- 奥地利gydF4y2Ba(德语)gydF4y2Ba
- 葡萄牙gydF4y2Ba(英语)gydF4y2Ba
- 瑞典gydF4y2Ba(英语)gydF4y2Ba
- 瑞士gydF4y2Ba
- 联合王国gydF4y2Ba(英语)gydF4y2Ba
亚太地区gydF4y2Ba
- 澳大利亚gydF4y2Ba(英语)gydF4y2Ba
- 印度gydF4y2Ba(英语)gydF4y2Ba
- 新西兰gydF4y2Ba(英语)gydF4y2Ba
- 中国gydF4y2Ba
- 日本gydF4y2Ba(日本語)gydF4y2Ba
- 한국gydF4y2Ba(한국어)gydF4y2Ba
