基于谱聚类的数据分割
本主题介绍了光谱聚类,并提供了一个估计聚类数量和执行光谱聚类的示例。
谱聚类简介
谱聚类是一种基于图形的算法,用于将数据点或观测值划分为k集群。统计和机器学习工具箱™功能光谱团对输入数据矩阵或数据集执行群集相似度矩阵从数据中得到的相似图。光谱团返回群集索引,一个矩阵包含k特征向量的拉普拉斯算子的矩阵,以及对应于特征向量的特征值向量。
光谱团需要指定集群的数量k.然而,您可以验证您的估计k是正确的,请使用以下方法之一:
计算拉普拉斯矩阵的零特征值的个数。零特征值的多重性是数据中集群数量的指标。
使用MATLAB在相似性矩阵中查找连接组件的数量®作用
conncomp.
算法描述
谱聚类是基于图的查找算法吗k数据中任意形状的簇。该技术涉及在低维中表示数据。在低维中,数据中的簇被更广泛地分离,使您能够使用以下算法:k——或k-medoids集群。这个低维是基于特征向量对应的k拉普拉斯矩阵的最小特征值。拉普拉斯矩阵是一种表示相似性图的方法,它将数据点之间的局部邻域关系建模为无向图。光谱聚类算法从你的数据中得到一个相似图的相似矩阵,找到拉普拉斯矩阵,然后使用拉普拉斯矩阵来找到k用于将相似图拆分为k分区。当您知道簇的数量时,可以使用谱簇,但是算法还提供了一种方法来估计数据中的簇的数量。
默认情况下,用于光谱团使用Shi Malik描述的方法计算归一化随机游动拉普拉斯矩阵[1].光谱团还支持使用万博1manbetxNg Jordan-Weiss方法的非规范化拉普拉斯矩阵和规范化对称拉普拉斯矩阵[2]这个光谱团函数实现的集群如下:
对于每个数据点
X,使用半径搜索方法或最近邻方法定义局部邻域,如“SimilarityGraph”名称-值对参数(请参见相似图).然后,找出成对距离 所有要点我和j在附近。使用核变换将距离转换为相似性度量 . 矩阵年代是相似度矩阵和σ是否为内核的比例因子,如使用
“内核尺度”名称-值对的论点。计算非规范拉普拉斯算子的矩阵l,归一化随机游动拉普拉斯矩阵lrw,即归一化对称拉普拉斯矩阵l年代,这取决于
“拉普拉斯归一化”名称-值对的论点。创建一个矩阵 包含列 ,其中列是k特征向量对应于k拉普拉斯矩阵的最小特征值。如果使用l年代,将V有单位长度。
处理每行V作为一个点,集群n点使用k-表示集群(默认)或k-medoids集群,由
“ClusterMethod”名称-值对的论点。把原始点赋值进去
X到相同的集群的对应行V.
估计聚类数并执行谱聚类
此示例演示了两种执行光谱聚类的方法。
第一种方法利用拉普拉斯矩阵的特征值估计聚类个数,并对数据集进行谱聚类。
第二种方法利用相似图估计聚类个数,并在相似矩阵上进行谱聚类。
生成样本数据
随机生成一个样本数据集,包含三个分离良好的聚类,每个聚类包含20个点。
rng (“默认”);%为了再现性n=20;X=[randn(n,2)*0.5+3;randn(n,2)*0.5;randn(n,2)*0.5-3];
对数据执行谱聚类
利用拉普拉斯矩阵的特征值估计数据中的聚类数,并对数据集进行谱聚类。
计算五个最小的特征值(在大小上)的拉普拉斯矩阵使用光谱团默认情况下,该函数使用规范化的随机行走拉普拉斯矩阵。
[~,V_-temp,D_-temp]=光谱簇(X,5)
V_temp =60×50.2236 -0.0000 0.0000 0.1534 0.0000 0.2236 -0.0000 0.0000 -0.3093 -0.0000 0.2236 -0.0000 0.0000 0.2225 0.0000 0.2236 -0.0000 0.0000 0.1776 0.0000 0.2236 -0.0000 0.0000 0.1331 -0.0000 0.2236 -0.0000 0.0000 0.2176 0.0000 0.2236 -0.0000 0.0000 0.1967 0.0000 0.2236 -0.0000 0.0000 -0.0088 -0.0000 0.2236 -0.0000 0.0000 -0.2844 -0.0000 0.2236 -0.0000 0.0000 -0.3275 -0.0000 ⋮
D_temp=5×1-0.0000 -0.0000 -0.0000 0.0876 0.1653
只有前三个特征值近似为零。零特征值的数量是相似图中连接组件数量的一个很好的指示器,因此,是对数据中集群数量的一个很好的估计。所以,k=3是一个很好的集群数量估计X.
通过使用光谱团函数。指定k=3集群。
k = 3;[idx1 V D] = spectralcluster (X, k)
idx1 =60×11 1 1 1 1 1 1 1 1⋮
五=60×30.2236 -0.0000 -0.0000 0.2236 -0.0000 -0.0000 0.2236 -0.0000 -0.0000 0.2236 -0.0000 -0.0000 0.2236 -0.0000 -0.0000 0.2236 -0.0000 -0.0000 0.2236 -0.0000 -0.0000 0.2236 -0.0000 -0.0000 0.2236 -0.0000 -0.0000 0.2236 -0.0000 -0.0000 ⋮
D=3×110-16× -0.0740 -0.1589 -0.3613
的元素D对应于拉普拉斯矩阵的三个最小特征值。的列V包含与特征值对应的特征向量D.对于分离良好的聚类,特征向量是指标向量。特征向量的值为零(或接近零)的点不属于一个特定的群集,和非零值的点属于一个特定的群集。
可视化聚类的结果。
gscatter (X (: 1) X (:, 2), idx1);
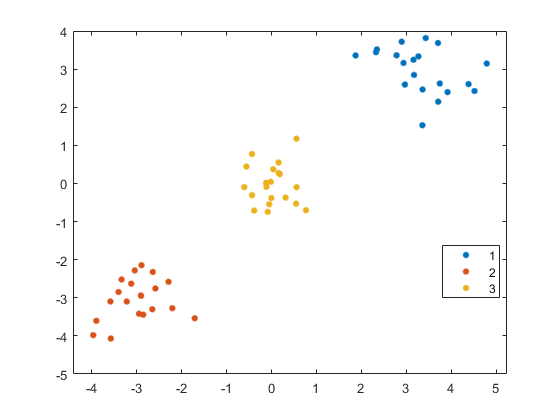
的光谱团函数正确地识别数据集中的三个集群。
而不是使用光谱团函数,你可以通过V_temp到K均值功能来聚类数据点。
idx2=kmeans(V_temp(:,1:3),3);gscatter(X(:,1),X(:,2),idx2);
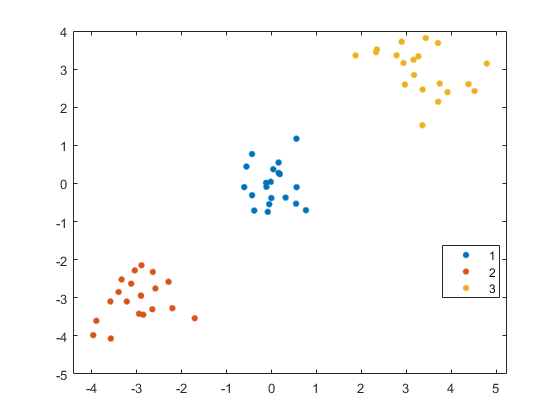
中的群集分配顺序idx1和idx2是不同的,即使数据点以相同的方式聚集。
进行光谱分析群集关于相似矩阵
使用相似度图估计聚类数,并在相似度矩阵上执行谱聚类。
在中找到每对观测值之间的距离X通过使用pdist和方形具有默认欧几里德距离度量的函数。
dist_temp = pdist (X);dist = squareform (dist_temp);
从成对距离构造相似矩阵,并确认相似矩阵是对称的。
S = exp(经销。^ 2);issymmetric (S)
ans=逻辑1
将相似值限制为0.5使得相似图只连接成对距离小于搜索半径的点。
S_eps = S;S_eps (S_eps < 0.5) = 0;
创建一个图反对年代.
G_eps=图形(S_eps);
形象化相似图。
情节(G_eps)
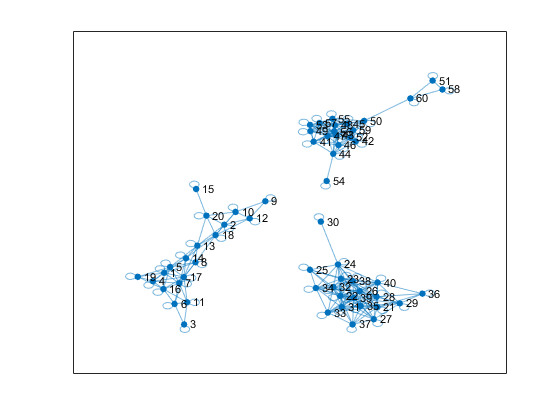
在图中识别连接组件的数量G_eps通过使用独特的和conncomp功能。
独特的(conncomp (G_eps))
ans=1×31 2 3
相似图显示了三组连通组件。相似图中连接组件的数量是对数据中集群数量的一个很好的估计。因此,k=3对于中的群集数量而言,是一个很好的选择X.
对数据集的相似度矩阵进行谱聚类X.
k = 3;idx3 = spectralcluster (S_eps k“距离”,“预算”);gscatter (X (: 1) X (:, 2), idx3);
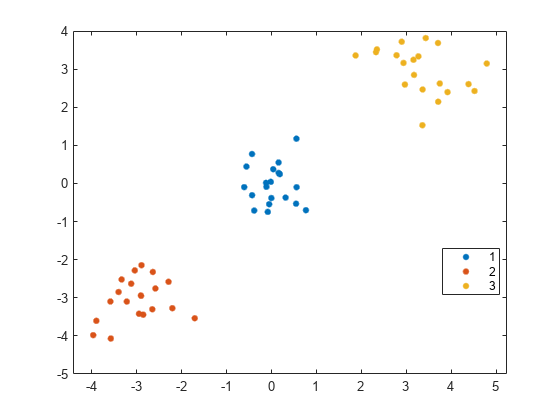
的光谱团函数正确地识别数据集中的三个集群。
参考文献
Shi, J.和J. Malik。"归一化切割和图像分割"关于模式分析和机器智能的IEEE交易.2000年第22卷,第888-905页。
Ng, a.y., M. Jordan和Y. Weiss。《关于光谱聚类:分析与算法》在神经信息处理系统进展14.麻省理工学院出版社,2001,页849-856。
另请参阅
光谱团|pdist2|pdist|方形|邻接|conncomp
相关的话题
您还可以从以下列表中选择网站:
