迈向自动化选型使用贝叶斯优化
这个例子说明了如何构建一个给定的训练数据集多种分类模型,使用贝叶斯优化优化其超参数,并选择模型表现最好的测试数据集。
训练几个模型并调优它们的超参数通常需要几天或几周的时间。创建一个脚本来自动开发和比较多个模型会快得多。您还可以使用贝叶斯优化来加快这个过程。不是使用不同的超参数集训练每个模型,而是选择几个不同的模型,并使用贝叶斯优化调优它们的默认超参数。贝叶斯优化通过最小化模型的目标函数来为给定的模型找到最优的超参数集。该优化算法在每次迭代中战略性地选择新的超参数,通常比简单的网格搜索更快地得到最优的超参数集。您可以使用本例中的脚本对给定的训练数据集使用贝叶斯优化来训练几个分类模型,并确定在测试数据集上表现最好的模型。
或者,要自动选择分类模型,这些分类器类型和超参数值,使用fitcauto..例如,请参见自动分类器选择贝叶斯优化.
加载样本数据
此示例使用存储在1994年人口普查数据census1994.mat.该数据集由美国人口普查局(US Census Bureau)的人口统计数据组成,用来预测一个人的年收入是否超过5万美元。分类任务是拟合一个模型,根据年龄、工人阶级、教育水平、婚姻状况、种族等因素预测人们的工资类别。
装入样本数据census1994并显示在数据集中的变量。
负载census1994谁是
名称大小字节类属性描述20x74 2960字符adultdata 32561x15 1872567表adulttest 16281x15 944467表
census1994包含培训数据集adultdata和测试数据集adulttest.对于此示例,要从原始表中减少运行时间,每个训练和测试观察adultdata和adulttest,通过使用datasample.函数。(如果您想使用完整的数据集可以跳过此步骤。)
NUMSAMPLES = 5000;S = RandStream('mlfg6331_64');%用于重现AdultData = DataMple(S,AdultData,Numsamples,'代替',错误的);adulttest = datasample(S,adulttest,NUMSAMPLES,'代替',错误的);
预览培训数据集的前几行。
头(adultdata)
ANS =8×15表年龄workClass fnlwgt教育education_num婚姻状况职业关系种族性别capital_gain capital_loss hours_per_week NATIVE_COUNTRY工资___ ___________ __________ ____________ _____________ __________________ _________________ ______________ _____ ______ ____________ ____________ ______________ ______________ ______ 39私人4.91e + 05 13学士学位从未结婚Exec的-管理其他相对黑色男性00 45美国 - 美国<= 50K 25私人2.2022e + 05 11 7未婚处理程序的清洁剂自己孩子的白人男性0 0 45美国 - 美国<= 50K 24私人2.2761e + 05 10 6离婚处理程序,清洁剂未婚白女0 0 58美国 - 美国<= 50K 51私人1.7329e + 05 HS-毕业生9离婚其他服务不在位家庭的白人女性0 0 40美国 - 美国<= 50K 54私人2.8029e + 05部分,大专10已婚,CIV配偶销售丈夫白男0 0 32美国 - 美国<= 50K 53联邦政务39643 HS-毕业生9丧偶Exec的-管理不在位家庭的白人女性0 0 58美国 - 美国<= 50K体52private 81859 HS-毕业生9已婚,CIV配偶机运inspct丈夫白人男性0 0 48美国 - 美国> 50K 37私人1.2429e + 05部分,大专10已婚,CIV配偶ADM-文书丈夫白人男性0 0美国50-美国<= 50K
每一行代表一个成人的属性,如年龄,学历和职业。最后一列薪水展示一个人是否有薪水小于或等于每年50,000美元或每年大于50,000美元。
理解数据,选择分类模型
统计和机器学习工具箱™提供了分类几个选项,包括分类树,判别分析,朴素贝叶斯,最近的邻居,支持向量机(SVM),并分类合奏。万博1manbetx对于算法的完整列表,请参阅分类.
在为你的问题选择算法之前,检查你的数据集。人口普查数据有几个值得注意的特点:
数据是表格的,包含数字和分类变量。
数据包含缺失值。
响应变量(
薪水)有两个课程(二进制分类)。
在不制定任何假设或使用您希望在数据上运行的算法的先验知识,您只需培训支持表格数据和二进制分类的所有算法。万博1manbetx纠错输出代码(ECOC)模型用于多个类的数据。判别分析和最近的邻居算法不分析包含数字和分类变量的数据。因此,适合于该示例的算法是SVM,决策树,决策树的集合,以及天真的贝叶斯模型。
构建模型和调谐覆盖率
为了加快这一进程,定制超参数优化选项。指定'ShowPlots'作为假和“详细”作为0分别禁用绘图和消息。另外,指定'使用指平行'作为真的并行运行贝叶斯优化,这需要并行计算工具箱™。由于并行时序的不可递容性,并行贝叶斯优化不一定会产生可重复的结果。
hypopts =结构('ShowPlots',错误的,“详细”0,'使用指平行',真的);
开始并行池。
poolobj = gcp;
您可以通过调用每个拟合函数并设置其培训数据集和调谐参数。“OptimizeHyperparameters”名称 - 值对参数'汽车'.创建分类模型。
支持向量机%:SVM与多项式核及SVM与高斯核mdls {1} = fitcsvm (adultdata,'薪水'那'KernelFunction'那“多项式”那“标准化”那“上”那......“OptimizeHyperparameters”那'汽车'那“HyperparameterOptimizationOptions”,低管);MDLS {2} = FITCSVM(AdultData,'薪水'那'KernelFunction'那'高斯'那“标准化”那“上”那......“OptimizeHyperparameters”那'汽车'那“HyperparameterOptimizationOptions”,低管);%决策树MDLS {3} = fitctree(adultdata,'薪水'那......“OptimizeHyperparameters”那'汽车'那“HyperparameterOptimizationOptions”,低管);决策树的%集团MDLS {4} = fitcensemble(adultdata,'薪水'那'学习者'那'树'那......“OptimizeHyperparameters”那'汽车'那“HyperparameterOptimizationOptions”,低管);%朴素贝叶斯mdls {5} = fitcnb(Adultiandata,'薪水'那......“OptimizeHyperparameters”那'汽车'那“HyperparameterOptimizationOptions”,低管);
警告:建议您优化朴素贝叶斯“宽度”参数时,第一个标准化的所有数字预测。如果你这样做,是忽略此警告。
绘制最低目标曲线
从每个模型中提取贝叶斯优化结果,并在超参数优化的每一次迭代中绘制出每个模型目标函数的最小观测值。目标函数值对应于使用训练数据集进行五次交叉验证所测得的误分类率。该图比较了每个模型的性能。
身材保持在n =长度(mdls);为I = 1:N MDL = MDLS {I};结果= MDLS {I} .HyperparameterOptimizationResults;图(results.ObjectiveMinimumTrace,“标记”那'O'那'MarkerSize'5);结束名称= {'svm-polynomial'那“SVM-Gaussian”那'决策树'那“合奏树”那'天真的贝叶斯'};传说(姓名,'地点'那'东北') 标题(“贝叶斯优化”)xlabel(“迭代次数”)ylabel(“最低客观价值”)
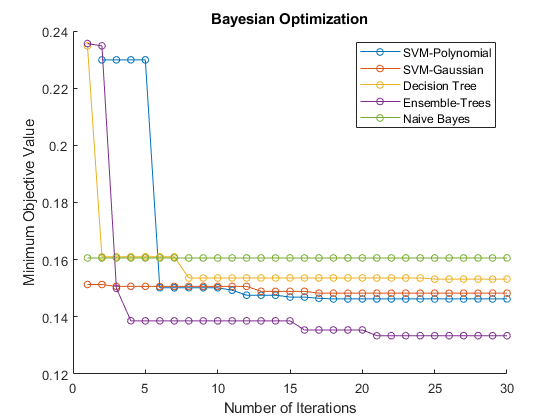
使用贝叶斯优化来找到更好的超参数集可以在多次迭代中提高模型的性能。在这种情况下,图表明决策树集成对数据的预测精度最好。该模型在多次迭代和不同的贝叶斯优化超参数集中均表现良好。
使用测试集检查性能
使用混淆矩阵和受试者工作特征(ROC)曲线,用测试数据集检查分类器性能。
找到预测标签和测试数据集的得分值。
标记=细胞(N,1);得分=细胞(N,1);为I = 1:N [标号{I},得分{I}] =预测(MDLS {I},adulttest);结束
混乱矩阵
方法获取每个测试观察的最可能的类预测各模型的功能。然后利用预测类和测试数据集的已知(真)类计算混淆矩阵困惑的园林函数。
图C =细胞(N,1);为I = 1:N副区(2,3,i)的13 C {I} = confusionchart(adulttest.salary,标签{I});标题(名称{I})结束

对角线元素指示给定类的正确归类实例的数量。非对角线元素是错误分类观察的实例。
ROC曲线
通过绘制每个分类器的ROC曲线更紧密地检查分类器性能。使用perfcurve函数来获取X和yROC曲线的坐标和计算的曲线下的区域(AUC)值X和y.
绘制ROC曲线对于与标签对应的分数值'<= 50k',检查从中返回的分数值的列顺序预测函数。列顺序与训练数据集中的响应变量的类别顺序相同。显示类别顺序。
C =类别(AdultData.Salary)
C =2×1细胞{ '<= 50K'} { '> 50K'}
绘制ROC曲线。
身材保持在AUC =零(1,N);为i = 1:n [x,y,〜,auc(i)] = perfcurve(apulementtest.salary,score {i}(:,1),'<= 50k');图(X,Y)结束标题('ROC曲线')xlabel(的假阳性率)ylabel(“真阳性率”)传奇(名字,'地点'那'东南')

ROC曲线显示了对分类器输出的不同阈值的假阳性率(或,灵敏度与1特异性)的真正阳性率。
现在用条形图绘制AUC值。对于一个完美的分类器,无论阈值如何,其真实阳性率始终为1,则AUC = 1。对于随机分配观察到的类的分类器,AUC = 0.5。AUC值越大表示分类器性能越好。
图酒吧(AUC)标题(“曲线下面积”)xlabel('模型')ylabel('AUC')xticklabels(地名)xtickangle(30)ylim([0.85,0.925])

基于混淆矩阵和AUC柱状图,决策树和支持向量机模型的集成比决策树和朴素贝叶斯模型的精度更高。
最有前途的模型的恢复优化
在所有模型上运行贝叶斯优化以进行进一步的迭代,在计算上可能会非常昂贵。相反,选择一个迄今为止运行良好的模型子集,并通过使用恢复函数。绘制每一次贝叶斯优化迭代的目标函数的最小观测值。
身材保持在selectedMdls = MDLS([1,2,4]);newresults =细胞(1,长度(selectedMdls));为newresults{i} = resume(selectedmls {i}. result = 1);HyperparameterOptimizationResults,'MaxObjectiveEvaluations',30);绘图(newresults {i} .ObjectiveminimumTrace,“标记”那'O'那'MarkerSize',5)结束标题(“贝叶斯优化与简历”)xlabel(“迭代次数”)ylabel(“最低客观价值”) 传奇({'svm-polynomial'那“SVM-Gaussian”那“合奏树”},'地点'那'东北')

前30次迭代对应第一轮贝叶斯优化。接下来的30次迭代对应于恢复函数。恢复优化是有用的,因为在前30次迭代之后损失会进一步减少。
也可以看看
BayesianOptimization|困惑的园林|perfcurve|恢复
相关话题
您还可以从以下列表中选择一个网站:
