基于YOLO v3深度学习的目标检测
这个例子展示了如何训练一个YOLO v3意思对象探测器。
深度学习是一种强大的机器学习技术,你可以用它来训练健壮的对象检测器。目前有几种用于目标检测的技术,包括Faster R-CNN、只看一次(YOLO) v2和单次探测(SSD)。这个例子展示了如何训练YOLO v3对象检测器。YOLO v3在YOLO v2的基础上进行了改进,增加了多个尺度的检测,以帮助检测较小的对象。将用于训练的损失函数分为均方误差进行边界盒回归和二元交叉熵进行目标分类,提高检测精度。
注意:这个例子需要YOLO v3对象检测的计算机视觉工具箱™模型。您可以从外接程序资源管理器安装YOLO v3对象检测的计算机视觉工具箱模型。有关安装外接程序的详细信息,请参见获取和管理外接组件.
下载预训练网络
使用helper函数下载预训练的网络downloadPretrainedYOLOv3Detector避免等待训练完成。如果要用一组新数据训练网络,请设置doTraining变量来真正的.
doTraining = false;如果~doTraining preTrainedDetector = downloadPretrainedYOLOv3Detector();结束
加载数据
本例使用了一个包含295张图像的小型标记数据集。这些图片大多来自加州理工学院汽车1999年和2001年的数据集,由Pietro Perona创建并获得许可使用。每张图像包含一个或两个标记的车辆实例。一个小的数据集对于探索YOLO v3训练过程是有用的,但在实践中,需要更多的标记图像来训练一个健壮的网络。
解压缩车辆图像并加载车辆地面真相数据。
解压缩vehicleDatasetImages.zip数据=负载(“vehicleDatasetGroundTruth.mat”);vehicleDataset = data.vehicleDataset;在本地车辆数据文件夹中添加全路径。vehicleDataset。imageFilename = fullfile(pwd, vehicleDataset.imageFilename);
注意:在多个类的情况下,数据也可以组织为三列,其中第一列包含带有路径的图像文件名,第二列包含边界框,第三列必须是包含每个边界框对应的标签名称的单元格向量。有关如何安排包围框和标签的详细信息,请参见boxLabelDatastore.
所有的边界框都必须在表单中[x y宽高].这个向量指定左上角和边界框的大小(以像素为单位)。
将数据集分割为训练网络的训练集和评估网络的测试集。将60%的数据用于训练集,其余数据用于测试集。
rng (0);shuffledIndices = randperm(height(vehicleDataset));idx =地板(0.6 *长度(shuffledIndices));trainingDataTbl = vehicleDataset(shuffledIndices(1:idx),:);testDataTbl = vehicleDataset(shuffledIndices(idx+1:end),:);
创建用于加载映像的映像数据存储。
imdsTrain = imageDatastore(trainingDataTbl.imageFilename);imdsTest = imageDatastore(testDataTbl.imageFilename);
为地面真值边界框创建一个数据存储。
bldsTrain = boxLabelDatastore(trainingDataTbl(:, 2:end));bldsTest = boxLabelDatastore(testDataTbl(:, 2:end));
组合图像和框标签数据存储。
trainingData = combine(imdsTrain, bldsTrain);testData = combine(imdsTest, bldsTest);
使用validateInputData检测无效图像、包围框或标签,即
图像格式无效或包含nan的样本
包含零/ nan / inf /空的包围框
失踪/ non-categorical标签。
边界框的值应该是有限的、正的、非分数的、非nan的,并且应该在图像边界内具有正的高度和宽度。任何无效的样品必须丢弃或进行适当的培训。
validateInputData (trainingData);validateInputData (testData);
数据增加
数据增强是通过在训练过程中随机转换原始数据来提高网络的准确性。通过使用数据增强,您可以为训练数据添加更多的多样性,而无需实际增加标记训练样本的数量。
使用变换函数将自定义数据增强应用于训练数据。的augmentData示例末尾列出的Helper函数对输入数据应用以下扩充。
HSV空间中的颜色抖动增强
随机水平翻转
随机缩放10%
augmentedTrainingData = transform(trainingData, @augmentData);
读取同一图像四次,并显示增强训练数据。
可视化增强图像。augmentedData = cell(4,1);为k = 1:4 data = read(augmentedTrainingData);augmentedData{k} = insertShape(数据{1,1},“矩形”、数据{1,2});重置(augmentedTrainingData);结束图蒙太奇(augmentedData,“BorderSize”, 10)

定义YOLO v3对象检测器
本例中的YOLO v3检测器基于SqueezeNet,使用了SqueezeNet中的特征提取网络,并在末端增加了两个检测头。第二个探测头的大小是第一个探测头的两倍,因此能够更好地探测小物体。请注意,您可以根据想要检测的对象的大小指定不同大小的任意数量的检测头。YOLO v3检测器使用训练数据估计的锚盒,以获得与数据集类型相对应的更好的初始先验,并帮助检测器学习准确地预测这些锚盒。有关锚框的信息,请参见用于对象检测的锚框.
YOLO v3检测器中的YOLO v3网络如下图所示。
你可以使用深度网络设计器(深度学习工具箱)创建图中所示的网络。

指定网络输入大小。在选择网络输入大小时,要考虑运行网络本身所需的最小大小,训练图像的大小,以及在所选大小下处理数据所产生的计算成本。在可行的情况下,选择一个接近训练图像大小且大于网络所需输入大小的网络输入大小。为了减少运行示例的计算成本,请指定网络输入大小为[227 227 3]。
networkInputSize = [227 227 3];
首先,使用变换为了预处理用于计算锚框的训练数据,因为本例中使用的训练图像大于227 * 227并且大小不同。指定锚的数量为6,以实现锚的数量和平均IoU之间的良好权衡。使用estimateAnchorBoxes函数来估计锚框。有关估算锚盒的详细信息,请参见从训练数据估计锚箱.在使用预训练的YOLOv3对象检测器的情况下,需要指定在特定训练数据集上计算的锚框。注意,估计过程不是确定的。为了防止在调优其他超参数时改变估计的锚框,在使用rng进行估计之前设置随机种子。
rng(0) trainingdatafestimtimation = transform(trainingData, @(data)preprocessData(data, networkInputSize));numAnchors = 6;[主播,meanIoU] = estimateAnchorBoxes(trainingdatafestimate, numAnchors)
锚=6×241 34 163 130 98 93 144 125 33 24 69 66
meanIoU = 0.8507
指定anchorBoxes用于两个检测头。anchorBoxes为[Mx1]的单元格数组,其中M为检测头数。每个探测头由一个[Nx2]矩阵组成锚,其中N为要使用的锚的数量。选择anchorBoxes对于每个检测头基于特征图的大小。使用更大的锚在更小的规模上锚在更高的尺度上。要这样做,请对锚首先使用较大的锚盒,并将前三个锚盒分配给第一个检测头,将后三个锚盒分配给第二个检测头。
Area = anchors(:, 1).*anchors(:, 2);[~, idx] = sort(area,“下”);锚=锚(idx,:);锚箱={锚(1:3,:)锚(4:6,:)};
在Imagenet数据集上加载预训练的SqueezeNet网络,然后指定类名。您还可以选择在COCO数据集上加载不同的预训练网络,例如tiny-yolov3-coco或darknet53-coco或Imagenet数据集,如MobileNet-v2或ResNet-18。当您使用预训练的网络时,YOLO v3性能更好,训练更快。
baseNetwork =挤压网;classNames = trainingDataTbl.Properties.VariableNames(2:结束);
接下来,创建yolov3ObjectDetector对象添加检测网络源。选择最优的检测网络源需要反复试验,可以使用analyzeNetwork在网络中查找潜在检测网络源的名称。对于本例,使用fire9-concat而且fire5-concat层,DetectionNetworkSource.
yolov3Detector = yolov3ObjectDetector(baseNetwork, classNames, anchorBoxes,“DetectionNetworkSource”, {“fire9-concat”,“fire5-concat”}, InputSize = networkInputSize);
或者,与上面使用SqueezeNet创建的网络不同,使用MS-COCO等更大的数据集训练的其他预训练YOLOv3架构可以用于自定义对象检测任务的检测器转移学习。迁移学习可以通过改变类名和锚定框来实现。
预处理训练数据
对增强训练数据进行预处理,为训练做准备。的进行预处理方法yolov3ObjectDetector,对输入数据执行以下预处理操作。
通过保持纵横比将图像调整为网络输入大小。
在范围内缩放图像像素
[0 1].
preprocessedTrainingData = transform(augmentedTrainingData, @(data)预处理(yolov3Detector, data));
读取预处理的训练数据。
data = read(preprocessedTrainingData);
显示带有包围框的图像。
I = data{1,1};Bbox = data{1,2};annotatedImage = insertShape(I,“矩形”, bbox);annotatedImage = imresize(annotatedImage,2);图imshow (annotatedImage)

重置数据存储。
重置(preprocessedTrainingData);
指定培训项目
指定这些培训选项。
将epoch的数量设置为80。
将迷你批大小设置为
8.当使用更大的小批量时,可以实现稳定的训练和更高的学习率.不过,这应该根据可用内存来设置。将学习率设置为0.001。
设置预热周期为
1000迭代。该参数表示根据公式以指数方式提高学习率的迭代次数 .它有助于在较高的学习率下稳定梯度。将L2正则化因子设置为0.0005。
将惩罚阈值指定为0.5。与地面真实值重叠小于0.5的检测将被惩罚。
初始化梯度的速度为
[].SGDM使用它来存储梯度的速度。
numEpochs = 80;miniBatchSize = 8;learningRate = 0.001;warmupPeriod = 1000;l2Regularization = 0.0005;惩罚阈值= 0.5;速度= [];
火车模型
在GPU上训练(如果有的话)。使用GPU需要并行计算工具箱™和支持CUDA®的NVIDIA®GPU。有关受支持的计算功能的信息,请参见万博1manbetxGPU计算要求(并行计算工具箱).
使用minibatchqueue函数将预处理后的训练数据进行批量分割,并带有支持函数万博1manbetxcreateBatchData它返回批处理的图像和边界框,并结合各自的类id。为了更快地提取批量数据进行训练,dispatchInBackground应设置为“true”,以确保并行池的使用。
minibatchqueue自动检测GPU的可用性。如果您没有GPU,或不想使用GPU进行训练,请设置OutputEnvironment参数“cpu”.
如果canUseParallelPool dispatchInBackground = true;其他的dispatchInBackground = false;结束mbqTrain = minibatchqueue(preprocsedtrainingdata, 2,...“MiniBatchSize”miniBatchSize,...“MiniBatchFcn”, @(图像,框,标签)createBatchData(图像,框,标签,classNames),...“MiniBatchFormat”, (“SSCB”,""),...“DispatchInBackground”dispatchInBackground,...“OutputCast”, ("",“替身”]);
使用辅助功能创建训练进度绘图仪万博1manbetxconfigureTrainingProgressPlotter在使用自定义训练循环训练检测器对象时查看绘图。
最后,指定自定义训练循环。对于每个迭代:
从
minibatchqueue.如果没有更多数据,则重置minibatchqueue和洗牌。评估模型梯度使用
dlfeval和modelGradients函数。这个函数modelGradients,作为支持函数,返回损失相对万博1manbetx于中可学习参数的梯度网,对应的小批损耗,以及当前批的状态。将权重衰减因子应用于梯度正则化,以获得更健壮的训练。
方法确定基于迭代的学习率
piecewiseLearningRateWithWarmup万博1manbetx支持功能。方法更新检测器参数
sgdmupdate函数。更新
状态移动平均探测器的参数。显示每次迭代的学习率、总损耗和个体损耗(盒子损耗、对象损耗和类损耗)。这些可以用来解释在每次迭代中各自的损失是如何变化的。例如,在几次迭代之后,盒损失突然出现峰值,这意味着预测中存在Inf或nan。
更新培训进度图。
如果损失已经饱和了几个周期,训练也可以终止。
如果doTraining为学习率和小批损失创建子图。图;[lossPlotter, learningRatePlotter] = configureTrainingProgressPlotter(fig);迭代= 0;%自定义训练循环。为epoch = 1:numEpochs reset(mbqTrain);洗牌(mbqTrain);而(hasdata(mbqTrain))迭代=迭代+ 1;[XTrain, YTrain] = next(mbqTrain);使用dlfeval和% modelGradients函数。[gradients, state, lossInfo] = dlfeval(@modelGradients, yolov3Detector, XTrain, YTrain,刑罚阈值);应用L2正则化。gradients = dlupdate(@(g,w) g + l2Regularization*w, gradients, yolov3Detector.Learnables);确定当前学习率值。currentLR = piecewiseLearningRateWithWarmup(迭代,epoch, learningRate, warmupPeriod, numEpochs);使用SGDM优化器更新检测器可学习参数。[yolov3Detector。学习性,速度]= sgdmupdate(yolov3Detector。学习性,梯度,速度,currentLR);更新dlnetwork的状态参数。yolov3Detector。状态=状态;显示进度。displayLossInfo(纪元,迭代,currentLR, lossInfo);用新的点更新训练图。updatePlots(lossPlotter, learningRatePlotter,迭代,currentLR, lossInfo.totalLoss);结束结束其他的yolov3Detector = preTrainedDetector;结束
评估模型
计算机视觉工具箱™提供对象检测器评估功能,以测量常见指标,如平均精度(evaluateDetectionPrecision)和对数平均失误率(evaluateDetectionMissRate).在本例中,使用平均精度度量。平均精度提供了一个单一的数字,其中包括探测器进行正确分类的能力(精度)和探测器找到所有相关对象的能力(召回率)。
结果=检测(yolov3Detector,testData,“MiniBatchSize”8);使用平均精度度量来评估目标探测器。[ap,recall,precision] = evaluateDetectionPrecision(results,testData);
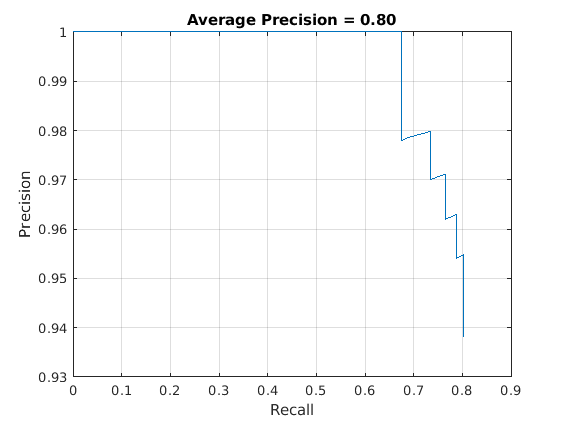
精度-召回(PR)曲线显示了探测器在不同召回级别下的精确程度。理想情况下,所有召回级别的精度都为1。
绘制精度-召回率曲线。图(召回率,精度)“回忆”) ylabel (“精度”网格)在标题(sprintf ('平均精度= %.2f'据美联社)),
使用YOLO v3检测对象
使用探测器进行物体检测。
读取数据存储。data = read(testData);获取图像。I =数据{1};[bboxes,scores,labels] = detect(yolov3Detector,I);在图像上显示检测结果。I = insertObjectAnnotation(I,“矩形”bboxes,分数);图imshow(我)

万博1manbetx支持功能
模型梯度函数
这个函数modelGradients以yolov3ObjectDetector对象的一个小批输入数据XTrain与相应的地面真值框YTrain,指定的惩罚阈值作为输入参数,并返回损失相对于中的可学习参数的梯度yolov3ObjectDetector,对应的小批丢失信息,以及当前批的状态。
模型梯度函数通过执行这些操作计算总损失和梯度。
方法从输入的图像批生成预测
向前方法。收集对CPU的预测,以便后处理。
将YOLO v3网格单元坐标的预测转换为边界框坐标,以便与地面真实数据进行比较
anchorBoxGenerator的方法yolov3ObjectDetector.通过使用转换后的预测和地面真实数据生成损失计算目标。这些目标是根据边界框位置(x、y、宽度、高度)、对象置信度和类别概率生成的。参见支持函数万博1manbetx
generateTargets.计算预测边界框坐标与目标框的均方误差。参见支持函数万博1manbetx
bboxOffsetLoss.确定预测对象置信度得分与目标对象置信度得分的二元交叉熵。参见支持函数万博1manbetx
objectnessLoss.确定预测类别的对象与目标的二进制交叉熵。参见支持函数万博1manbetx
classConfidenceLoss.将总损失计算为所有损失的总和。
计算关于总损失的可学习知识的梯度。
函数[gradients, state, info] = modelGradients(detector, XTrain, YTrain,刑罚阈值)inputImageSize = size(XTrain,1:2);在CPU中收集ground truth用于后期处理。YTrain = gather(extractdata(YTrain));从检测器中提取预测。[gatheredforecasts, YPredCell, state] = forward(检测器,XTrain);从地面真实数据生成预测目标。[boxTarget, objectnessTarget, classTarget, objectMaskTarget, boxErrorScale] = generateTargets(gatheredprediction,...YTrain, inputImageSize,检测器。AnchorBoxes penaltyThreshold);计算损失。boxLoss = bboxOffsetLoss(YPredCell(:,[2 3 7 8]),boxTarget,objectMaskTarget,boxErrorScale);objLoss = objectnessLoss(YPredCell(:,1),objectnessTarget,objectMaskTarget);clsLoss = classConfidenceLoss(YPredCell(:,6),classTarget,objectMaskTarget);totalLoss = boxLoss + objLoss + clsLoss;信息。boxLoss = boxLoss;信息。objLoss = objLoss;信息。clsLoss = clsLoss; info.totalLoss = totalLoss;计算关于损失的可学习知识的梯度。。gradients = dlgradient(totalLoss, detector.Learnables);结束函数boxLoss = bboxOffsetLoss(boxPredCell, boxDeltaTarget, boxMaskTarget, boxErrorScaleTarget)包围框位置的均方误差。lossX = sum(cellfun(@(a,b,c,d) mse(a.*c.*d,b.*c.*d),boxPredCell(:,1),boxDeltaTarget(:,1),boxMaskTarget(:,1),boxErrorScaleTarget));lossY = sum(cellfun(@(a,b,c,d) mse(a.*c.*d,b.*c.*d),boxPredCell(:,2),boxDeltaTarget(:,2),boxMaskTarget(:,1),boxErrorScaleTarget));lossW = sum(cellfun(@(a,b,c,d) mse(a.*c.*d,b.*c.*d),boxPredCell(:,3),boxDeltaTarget(:,3),boxMaskTarget(:,1),boxErrorScaleTarget));lossH = sum(cellfun(@(a,b,c,d) mse(a.*c.*d,b.*c.*d),boxPredCell(:,4),boxDeltaTarget(:,4),boxMaskTarget(:,1),boxErrorScaleTarget));boxLoss = lossX+lossY+lossW+lossH;结束函数objLoss = objectnessLoss(objectnessPredCell, objectnessDeltaTarget, boxMaskTarget)客观性评分的二元交叉熵损失。objLoss = sum(cellfun(@(a,b,c) crossentropy(a.*c,b.*c,“TargetCategories”,“独立”)、objectnessPredCell objectnessDeltaTarget boxMaskTarget (:, 2)));结束函数clsLoss = classConfidenceLoss(classPredCell, classTarget, boxMaskTarget)类置信度分数的二元交叉熵损失。clsLoss = sum(cellfun(@(a,b,c) crossentropy(a.*c,b.*c,“TargetCategories”,“独立”)、classPredCell classTarget boxMaskTarget (:, 3)));结束
增强和数据处理功能
函数数据= augmentData(A)应用随机水平翻转,随机X/Y缩放。盒子%缩放到边界外,如果重叠大于0.25则被剪切。同时,%抖动图像颜色。data = cell(size(A));为ii = 1:size(A,1) I = A{ii,1};bboxes = A{ii,2};标签= A{ii,3};sz = size(I);如果== 3 && sz(3) == 3 I = jitterColorHSV(I,...“对比”, 0.0,...“颜色”, 0.1,...“饱和”, 0.2,...“亮度”, 0.2);结束%随机翻转图像。tform = randomAffine2d(“XReflection”,真的,“规模”1.1 [1]);rout = affineOutputView(sz,tform,“BoundsStyle”,“centerOutput”);I = imwarp(I,tform,“OutputView”,溃败);对方框应用相同的变换。[bboxes, indexes] = bboxwarp(bboxes,tform,rout,“OverlapThreshold”, 0.25);Bboxes = round(Bboxes);标签=标签(索引);%仅当所有方框通过扭曲删除时才返回原始数据。如果isempty(indexes) data(ii,:) = A(ii,:);其他的data(ii,:) = {I, bboxes, labels};结束结束结束函数data = preprocessData(data, targetSize)调整图像大小并将像素缩放到0到1之间。同时缩放%对应的包围框。为ii = 1:size(data,1) I = data{ii,1};imgSize = size(I);将单通道的输入图像转换为3通道。如果I = repmat(I,1,1,3);结束Bboxes =数据{ii,2};I = im2single(imresize(I,targetSize(1:2)));/imgSize(1:2);Bboxes = bboxresize(Bboxes,scale);data(ii, 1:2) = {I, bboxes};结束结束函数[XTrain, YTrain] = createBatchData(data, groundTruthBoxes, groundTruthClasses, classNames)返回XTrain和中沿批处理维度组合的图像%归一化边界框与YTrain中的classid连接沿批处理维度连接图像。XTrain = cat(4, data{:,1});从类名中获取类id。classNames = repmat({categorical(classNames')}, size(groundTruthClasses));[~, classIndices] = cellfun(@(a,b)ismember(a,b), groundTruthClasses, classNames,“UniformOutput”、假);%将标签索引和训练图像大小附加到缩放的包围框中%,并创建响应的单单元格数组。combinedResponses = cellfun(@(bbox, classid)[bbox, classid], groundTruthBoxes, classIndices,“UniformOutput”、假);len = max(cellfun(@(x)size(x,1), combinedResponses));paddedBBoxes = cellfun(@(v) padarray(v,[透镜大小(v,1),0],0,“职位”)、combinedResponses“UniformOutput”、假);YTrain = cat(4, paddedBBoxes{:,1});结束
学习率表命令功能
函数currentLR = piecewiseLearningRateWithWarmup(迭代,epoch, learningRate, warmupPeriod, numEpochs)分段elearningratewithwarmup函数计算当前%基于迭代数的学习率。持续的warmUpEpoch;如果iteration <= warmupPeriod增加热身期迭代次数的学习率。currentLR = learningRate * ((iteration/warmupPeriod)^4);warmUpEpoch = epoch;elseif迭代>= warmupPeriod && epoch < warmUpEpoch+floor(0.6*(numEpochs-warmUpEpoch))在预热期结束后,如果剩余的epoch数小于60%,则保持学习率不变。currentLR = learningRate;elseifepoch >= warmUpEpoch+floor(0.6*(numEpochs-warmUpEpoch)) && epoch < warmUpEpoch+floor(0.9*(numEpochs-warmUpEpoch)))%如果剩余的epoch数大于60%但小于60%%大于90%,学习率乘以0.1。currentLR = learningRate*0.1;其他的如果剩余的时间超过90%,将学习加倍%率0.01。currentLR = learningRate*0.01;结束结束
效用函数
函数[lossPlotter, learningRatePlotter] = configureTrainingProgressPlotter(f)创建子图以显示损失和学习率。图(f);clf次要情节(2,1,1);ylabel (学习速率的);包含(“迭代”);learningRatePlotter = animatedline;次要情节(2,1,2);ylabel (“全损”);包含(“迭代”);lossPlotter = animatedline;结束函数displayLossInfo(epoch, iteration, currentLR, lossInfo)显示每次迭代的损失信息。disp (“时代:”+ epoch +" |迭代:"+迭代+“|学习率:”+ currentLR +...全损:" |+ double(gather(extractdata(lossInfo.totalLoss))) +...“|盒子丢失:”+ double(gather(extractdata(lossInfo.boxLoss))..." |物品丢失:"+ double(gather(extractdata(lossInfo.objLoss))...“|类损失:”+双(收集(extractdata (lossInfo.clsLoss))));结束函数updatePlots(lossPlotter, learningRatePlotter,迭代,currentLR, totalLoss)更新损失和学习率图。addpoints(lossPlotter,迭代,double(extractdata(gather(totalLoss))));addpoints(learningRatePlotter,迭代,currentLR);drawnow结束函数检测器= downloadPretrainedYOLOv3Detector()下载预先训练的yolov3检测器。。如果~ (“yolov3SqueezeNetVehicleExample_21aSPKG.mat”,“文件”)如果~ (“yolov3SqueezeNetVehicleExample_21aSPKG.zip”,“文件”) disp (“下载预训练的检测器……”);pretrainedURL =“https://ssd.mathworks.com/万博1manbetxsupportfiles/vision/data/yolov3SqueezeNetVehicleExample_21aSPKG.zip”;websave (“yolov3SqueezeNetVehicleExample_21aSPKG.zip”, pretrainedURL);结束解压缩(“yolov3SqueezeNetVehicleExample_21aSPKG.zip”);结束预训练=负荷(“yolov3SqueezeNetVehicleExample_21aSPKG.mat”);检测器=预训练的。结束
参考文献
雷蒙,约瑟夫和阿里·法哈蒂。“YOLOv3:渐进式改进。”预印本,2018年4月8日提交。https://arxiv.org/abs/1804.02767。
另请参阅
检测|进行预处理|向前|yolov3ObjectDetector|analyzeNetwork(深度学习工具箱)|evaluateDetectionPrecision|evaluateDetectionMissRate
相关的话题
您也可以从以下列表中选择一个网站: