语音数字识别与小波散射和深度学习
这个例子展示了如何使用机器和分类说数字深度学习技巧。在这个例子中,您执行分类使用小波时间散射与支持向量机(SVM)和短期记忆(LSTM)网络。万博1manbetx你也应用贝叶斯优化来确定合适的hyperparameters改善LSTM网络的准确性。此外,该示例演示了一个方法使用卷积神经网络(CNN)和mel-frequency声谱图。
数据
克隆或下载免费的数字数据集(FSDD),口语可以在https://github.com/Jakobovski/free-spoken-digit-dataset。FSDD是一个开放的数据集,这意味着它能随着时间的推移而增长。这个示例使用版本提交1月29日,2019年,2000年由数字0到9的英文录音来自四个扬声器。在这个版本中,其中两个扬声器是母语为英语的美国人,一位发言者是一种非本地的扬声器与比利时法国口音的英语,和一个扬声器是一个非本地人说英语与德语口音。数据采样在8000赫兹。
使用audioDatastore管理数据访问录音,确保随机分为训练集和测试集。设置位置房地产的位置FSDD录音文件夹在您的计算机上。在本例中,数据存储在一个文件夹下tempdir。
pathToRecordingsFolder = fullfile (tempdir,“free-spoken-digit-dataset”,“录音”);位置= pathToRecordingsFolder;
点audioDatastore到新位置。
广告= audioDatastore(位置);
辅助函数helpergenLabels创建一个分类数组FSDD标签的文件。的源代码helpergenLabels列在附录中。列表的类和例子的数量在每个类。
ads.Labels = helpergenLabels(广告);总结(ads.Labels)
0 300 300 300 300 300 4 300 5 6 300 7 300 300 300 9
FSDD数据集包含10平衡类200录音。的录音FSDD不相等的时间。FSDD不是非常大,因此阅读FSDD文件并构建一个信号长度的柱状图。
LenSig = 0(元素个数(ads.Files), 1);nr = 1;而hasdata(广告)数字=阅读(广告);LenSig (nr) =元素个数(数字);nr = nr + 1;结束重置(广告)直方图(LenSig)网格在包含(的信号长度(样本))ylabel (“频率”)
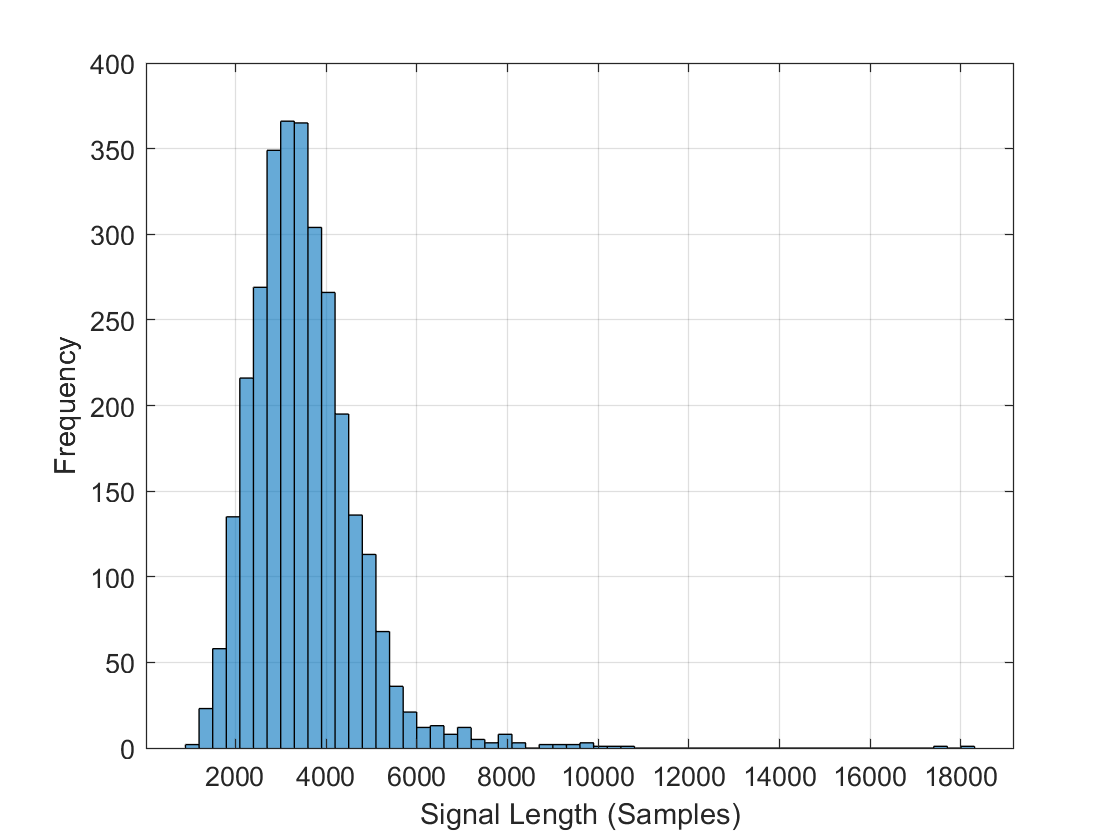
直方图显示,记录长度的分布是积极倾斜。分类,这个示例使用常见的8192个样本信号的长度,一个保守的价值,确保删除再录音不切断演讲内容。如果信号大于8192个样本长度(1.024秒),8192个样本记录被截断。如果信号小于8192样本长度、信号前置液和postpadded对称零长度为8192个样本。
小波时间散射
使用waveletScattering创建一个小波散射时间框架使用一个不变的规模0.22秒。在这个示例中,您创建的特征向量样本平均散射变换在所有时间。有足够数量的每个时间窗口平均散射系数,集OversamplingFactor2生产的数量增加到了原来的4倍散射系数为每个路径对批判性downsampled价值。
科幻小说= waveletScattering (“SignalLength”,8192,“InvarianceScale”,0.22,…“SamplingFrequency”,8000,“OversamplingFactor”2);
把FSDD分成训练集和测试集。分配80%的数据训练集和测试集保留20%。训练分类器的训练数据是基于散射变换。试验数据验证模型。
rng默认的;广告= shuffle(广告);[adsTrain, adsTest] = splitEachLabel(广告,0.8);countEachLabel (adsTrain)
ans =10×2表标签数_____ _____ 0 240 240 240 240 240 4 240 5 6 240 7 240 240 240 9
countEachLabel (adsTest)
ans =10×2表标签数_____ _____ 60 0 60 60 60 1 60 2 3 4 5 6 60 60 60 60 60 7 8 9
辅助函数helperReadSPData截断或垫8192和规范的数据长度记录的最大值。的源代码helperReadSPData列在附录中。创建一个8192 -,- 1600矩阵,其中每一列是一个spoken-digit录音。
Xtrain = [];scatds_Train =变换(adsTrain @ (x) helperReadSPData (x));而hasdata (scatds_Train) smat =阅读(scatds_Train);Xtrain =猫(2 Xtrain smat);结束
重复测试集的过程。由此产生的矩阵是8192 - 400。
Xtest = [];scatds_Test =变换(adsTest @ (x) helperReadSPData (x));而hasdata (scatds_Test) smat =阅读(scatds_Test);Xtest =猫(2 Xtest smat);结束
小波散射变换应用到训练集和测试集。
应变= sf.featureMatrix (Xtrain);圣= sf.featureMatrix (Xtest);
获得的平均散射特性的训练集和测试集。排除零阶散射系数。
TrainFeatures =应变(2:,:,);TrainFeatures =挤压(平均(TrainFeatures, 2))的;TestFeatures =圣(2:,:,);TestFeatures =挤压(平均(TestFeatures, 2))的;
支持向量机分类器
现在数据已经减少为每个记录一个特征向量,下一步是使用这些特性进行分类记录。创建一个支持向量机学习模板与一个二次多项式的内核。支持向量机的训练数据。
模板= templateSVM (…“KernelFunction”,多项式的,…“PolynomialOrder”2,…“KernelScale”,“汽车”,…“BoxConstraint”,1…“标准化”,真正的);classificationSVM = fitcecoc (…TrainFeatures,…adsTrain.Labels,…“学习者”模板,…“编码”,“onevsone”,…“类名”分类({' 0 ';' 1 ';' 2 ';“3”;“4”;“5”;“6”;“7”;“8”;“9”}));
使用k-fold交叉验证预测模型的泛化精度基于训练数据。将训练集分成五组。
partitionedModel = crossval (classificationSVM,“KFold”5);[validationPredictions, validationScores] = kfoldPredict (partitionedModel);validationAccuracy = (1 - kfoldLoss (partitionedModel“LossFun”,“ClassifError”))* 100
validationAccuracy = 97.4167
估计泛化精度约为97%。使用训练SVM预测spoken-digit类在测试集。
predLabels =预测(classificationSVM TestFeatures);testAccuracy = (predLabels = = adsTest.Labels) /元素个数之和(predLabels) * 100
testAccuracy = 97.1667
总结的性能模型在测试集上的混乱。显示每个类的精度和召回通过使用列和行摘要。表的底部的混乱图表显示了每个类的精度值。桌子右边的图表显示混乱召回值。
图(“单位”,“归一化”,“位置”(0.2 - 0.2 0.5 - 0.5));ccscat = confusionchart (adsTest.Labels predLabels);ccscat。Title =“小波散射分类”;ccscat。ColumnSummary =“column-normalized”;ccscat。RowSummary =“row-normalized”;
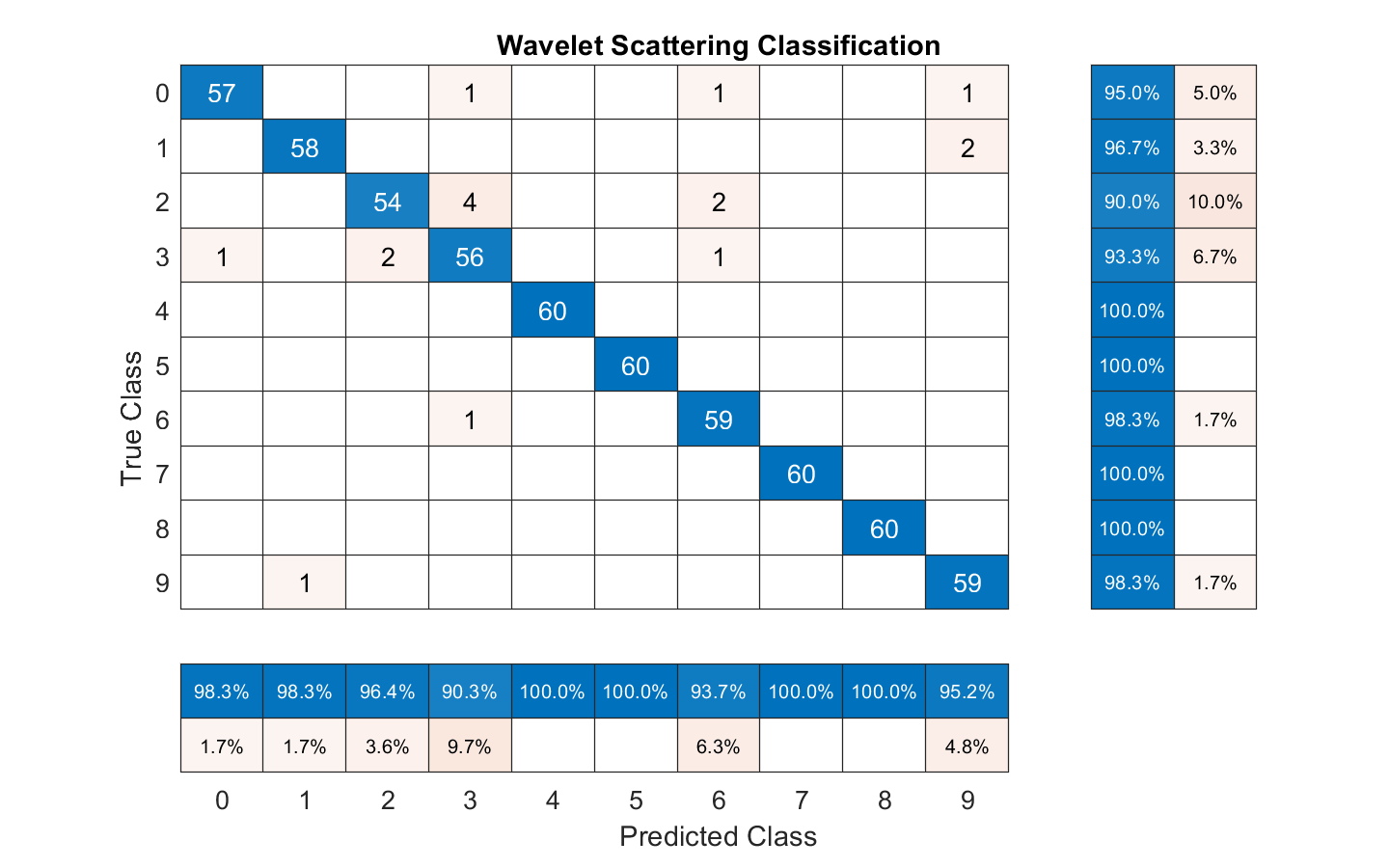
散射变换结合支持向量机分类器分类测试集的数字口语的准确性达98%(或2%的错误率)。
长短期记忆(LSTM)网络
LSTM网络是一种递归神经网络(RNN)。RNNs是专门用于神经网络使用顺序或时间数据,如语音数据。因为小波散射系数序列,它们可以用作输入LSTM。通过使用散射特性而不是原始数据,可以减少您的网络需要学习的变化。
修改培训和测试被用于LSTM网络散射特性。排除零阶散射系数和特征转换为细胞数组。
TrainFeatures =应变(2:,:,);TrainFeatures =挤压(num2cell (TrainFeatures [1 - 2]));TestFeatures =圣(2:,:,);TestFeatures =挤压(num2cell (TestFeatures [1 - 2]));
构建一个简单的LSTM网络512隐藏层。
[inputSize ~] =大小(TrainFeatures {1});YTrain = adsTrain.Labels;numHiddenUnits = 512;numClasses =元素个数(独特(YTrain));层= […sequenceInputLayer inputSize lstmLayer (numHiddenUnits,“OutputMode”,“最后一次”)fullyConnectedLayer (numClasses) softmaxLayer classificationLayer];
设置hyperparameters。用亚当优化和mini-batch大小为50。时代的最大数量设置为300。使用1的军医的学习速率。你可以关掉培训进展情节如果你不想使用阴谋跟踪进展。培训使用GPU在默认情况下,如果一个是可用的。否则,它使用一个CPU。有关更多信息,请参见trainingOptions(深度学习工具箱)。
maxEpochs = 300;miniBatchSize = 50;选择= trainingOptions (“亚当”,…“InitialLearnRate”,0.0001,…“MaxEpochs”maxEpochs,…“MiniBatchSize”miniBatchSize,…“SequenceLength”,“最短”,…“洗牌”,“every-epoch”,…“详细”假的,…“阴谋”,“训练进步”);
培训网络。
网= trainNetwork (TrainFeatures、YTrain层,选择);
predLabels =分类(净,TestFeatures);testAccuracy = (predLabels = = adsTest.Labels) /元素个数之和(predLabels) * 100
testAccuracy = 96.3333
贝叶斯优化
确定合适的hyperparameter设置通常是最困难的部分之一,培训网络。减轻这个,您可以使用贝叶斯优化。在本例中,您优化隐藏层的数量,利用贝叶斯技术最初的学习速率。创建一个新目录来存储hyperparameter mat文件包含信息设置和网络以及相应的错误率。
YTrain = adsTrain.Labels;欧美= adsTest.Labels;如果~ (”结果/”,“dir”mkdir)结果结束
优化初始化变量及其值范围。因为隐藏层的数量必须是一个整数,集“类型”来“整数”。
optVars = [optimizableVariable (“InitialLearnRate”(1 e-5, 1 e 1),“转换”,“日志”)optimizableVariable (“NumHiddenUnits”(1000),“类型”,“整数”));
贝叶斯优化计算量,可以需要几个小时才能完成。对于本示例,集optimizeCondition来假下载和使用预先确定的优化hyperparameter设置。如果你设置optimizeCondition来真正的的目标函数helperBayesOptLSTM使用贝叶斯最小优化。附录中列出的,目标函数是网络的误码率给出具体hyperparameter设置。加载设置目标函数最小的0.02(出错率2%)。
ObjFcn = helperBayesOptLSTM (TrainFeatures YTrain TestFeatures,欧美);optimizeCondition = false;如果optimizeCondition BayesObject = bayesopt (ObjFcn optVars,…“MaxObjectiveEvaluations”15岁的…“IsObjectiveDeterministic”假的,…“UseParallel”,真正的);其他的url =“http://ssd.mathworks.com/万博1manbetxsupportfiles/audio/SpokenDigitRecognition.zip”;downloadNetFolder = tempdir;netFolder = fullfile (downloadNetFolder,“SpokenDigitRecognition”);如果~存在(netFolder“dir”)disp (文件下载pretrained网络(1 - 12 MB)……”解压缩(url, downloadNetFolder)结束负载(fullfile (netFolder“0.02.mat”));结束
文件下载pretrained网络(1 - 12 MB)……
如果你执行贝叶斯优化,数据生成类似于下面的跟踪目标函数值与相应hyperparameter值和迭代的数量。你可以增加贝叶斯优化迭代的数量,以确保全球最小的目标函数。
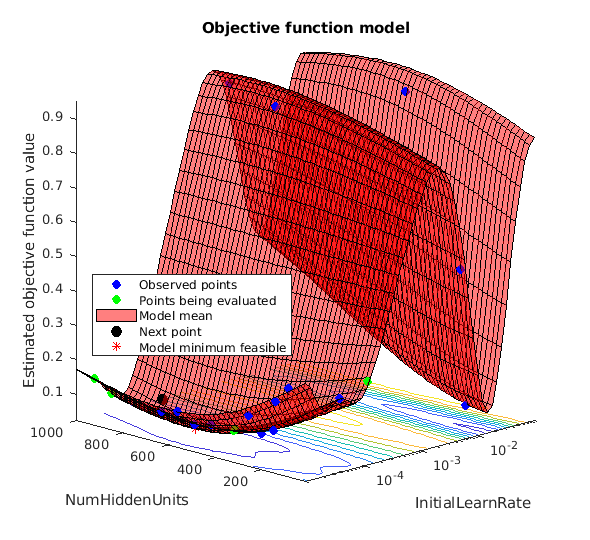
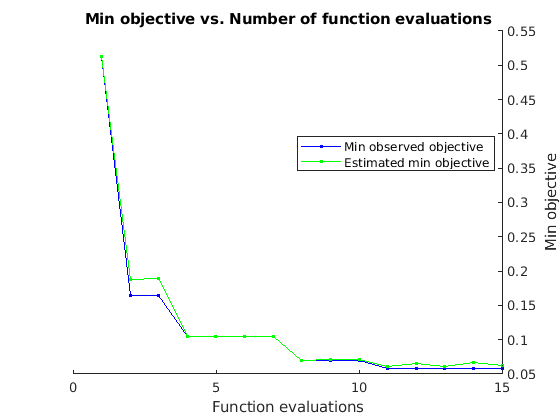
使用优化值的隐藏的单位和最初的学习速率和培训网络。
numHiddenUnits = 768;numClasses =元素个数(独特(YTrain));层= […sequenceInputLayer inputSize lstmLayer (numHiddenUnits,“OutputMode”,“最后一次”)fullyConnectedLayer (numClasses) softmaxLayer classificationLayer];maxEpochs = 300;miniBatchSize = 50;选择= trainingOptions (“亚当”,…“InitialLearnRate”2.198827960269379 e-04…“MaxEpochs”maxEpochs,…“MiniBatchSize”miniBatchSize,…“SequenceLength”,“最短”,…“洗牌”,“every-epoch”,…“详细”假的,…“阴谋”,“训练进步”);网= trainNetwork (TrainFeatures、YTrain层,选择);predLabels =分类(净,TestFeatures);testAccuracy = (predLabels = = adsTest.Labels) /元素个数之和(predLabels) * 100
testAccuracy = 97.5000
图所示,使用贝叶斯优化产生一个LSTM精度高。
使用Mel-Frequency色深卷积网络
作为另一个语音数字识别的任务方法,使用一个深卷积神经网络(DCNN)根据FSDD mel-frequency色分类数据集。使用相同的信号截断/填充过程的散射变换。同样,规范化记录除以每个信号样本的最大绝对值。为了一致性,使用相同的训练集和测试集的散射变换。
设置参数mel-frequency声谱图。使用相同的窗口或框架,在散射变换,持续时间0.22秒。设置窗口之间跳10 ms。使用40频段。
segmentDuration = 8192 * (1/8000);frameDuration = 0.22;hopDuration = 0.01;numBands = 40;
重置的训练和测试数据存储。
重置(adsTrain);重置(adsTest);
辅助函数helperspeechSpectrograms在这个例子中,定义的使用melSpectrogram标准化后得到mel-frequency声谱图记录长度和振幅正常化。使用的对数mel-frequency DCNN谱图作为输入。为了避免零的对数,每个元素添加一个小ε。
epsil = 1 e-6;XTrain = helperspeechSpectrograms (adsTrain segmentDuration、frameDuration hopDuration, numBands);
计算语音谱图……处理500个文件的2400年2400年加工1000个文件处理1500个文件的2400 2400…做加工2000个文件
XTrain = log10 (XTrain + epsil);XTest = helperspeechSpectrograms (adsTest segmentDuration、frameDuration hopDuration, numBands);
计算语音谱图……处理500个文件600…
XTest = log10 (XTest + epsil);YTrain = adsTrain.Labels;欧美= adsTest.Labels;
定义DCNN架构
构建一个小型DCNN层的一个数组。使用卷积和批量标准化层,downsample使用max池层特征图。减少的可能性,网络记忆训练数据的特定功能,添加少量的辍学输入到最后完全连接层。
深圳=大小(XTrain);specSize =深圳(1:2);图象尺寸= [specSize 1];numClasses =元素个数(类别(YTrain));dropoutProb = 0.2;numF = 12;层= [imageInputLayer(图象尺寸)convolution2dLayer (5 numF“填充”,“相同”)batchNormalizationLayer reluLayer maxPooling2dLayer (3“步”2,“填充”,“相同”)convolution2dLayer (3 2 * numF“填充”,“相同”)batchNormalizationLayer reluLayer maxPooling2dLayer (3“步”2,“填充”,“相同”)convolution2dLayer (3、4 * numF,“填充”,“相同”)batchNormalizationLayer reluLayer maxPooling2dLayer (3“步”2,“填充”,“相同”)convolution2dLayer (3、4 * numF,“填充”,“相同”)batchNormalizationLayer reluLayer convolution2dLayer (3、4 * numF,“填充”,“相同”)batchNormalizationLayer reluLayer maxPooling2dLayer (2) dropoutLayer (dropoutProb) fullyConnectedLayer (numClasses) softmaxLayer classificationLayer (“类”类别(YTrain));];
设置hyperparameters用于训练网络。使用mini-batch 50和学习速率大小1的军医。指定亚当优化。因为在这个例子的数据量相对较小,设置执行环境“cpu”再现性。你也可以训练的网络可用的GPU通过设置执行环境“图形”或“汽车”。有关更多信息,请参见trainingOptions(深度学习工具箱)。
miniBatchSize = 50;选择= trainingOptions (“亚当”,…“InitialLearnRate”1的军医,…“MaxEpochs”30岁的…“MiniBatchSize”miniBatchSize,…“洗牌”,“every-epoch”,…“阴谋”,“训练进步”,…“详细”假的,…“ExecutionEnvironment”,“cpu”);
培训网络。
trainedNet = trainNetwork (XTrain、YTrain层,选择);
使用训练网络预测的数字标签测试集。
[Ypredicted,聚合氯化铝]=分类(trainedNet XTest,“ExecutionEnvironment”,“CPU”);cnnAccuracy = (Ypredicted = =次)/元素个数之和(欧美)* 100
cnnAccuracy = 98.1667
总结训练网络的性能测试集的混乱。显示每个类的精度和召回通过使用列和行摘要。表底部的混乱图表显示精度值。桌子右边的图表显示混乱召回值。
图(“单位”,“归一化”,“位置”(0.2 - 0.2 0.5 - 0.5));ccDCNN = confusionchart(欧美,Ypredicted);ccDCNN。Title =“DCNN混乱图”;ccDCNN。ColumnSummary =“column-normalized”;ccDCNN。RowSummary =“row-normalized”;
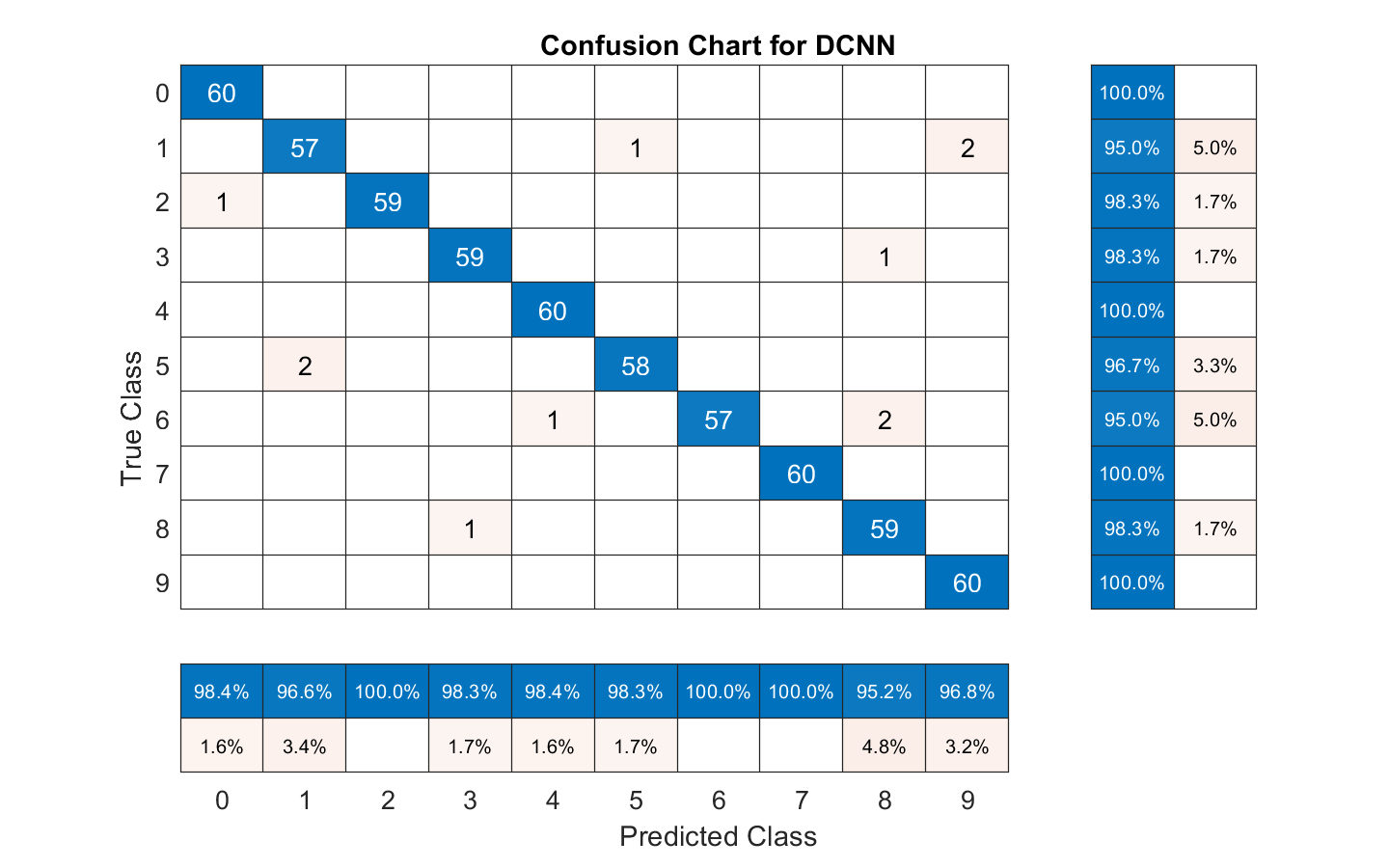
使用mel-frequency DCNN谱图作为输入分类中的数字口语测试集大约98%的准确率。
总结
这个例子展示了如何使用不同的机器和深度学习方法分类FSDD说数字。这个例子说明小波散射与SVM和LSTM。贝叶斯技术被用来优化LSTM hyperparameters。最后,这个例子展示了如何使用一个CNN mel-frequency色。
这个例子的目的是演示如何使用MathWorks®工具方法的问题完全不同但互补的方式。所有工作流使用audioDatastore从磁盘管理的数据流,并确保适当的随机化。
在本例中使用的所有方法进行同样的测试集。这个例子并不打算各种方法之间的直接比较。例如,您还可以使用贝叶斯优化hyperparameter CNN的选择。额外的有用的策略在深度学习小训练集FSDD是使用的这个版本数据增大。操作如何影响类并不总是知道,所以数据增加并不总是可行的。然而,对于演讲,建立数据可通过增强策略audioDataAugmenter。
小波的散射,也有一些修改,您可以试一试。例如,你可以改变的规模不变的变换,不同的小波滤波器/滤波器组,并尝试采用不同的分类器。
附录:辅助函数
函数标签= helpergenLabels(广告)%这个函数只用于小波工具箱的例子。它可能是%在将来发布的版本中修改或删除。tmp =细胞(元素个数(ads.Files), 1);表达=“[0 - 9]+ _”;为nf = 1:元素个数(ads.Files) idx = regexp (ads.Files {nf},表达式);tmp {nf} = ads.Files {nf} (idx);结束标签=分类(tmp);结束
函数x = helperReadSPData (x)%这个函数只用于小波工具箱的例子。它可能改变或%在将来的版本中被删除。N =元素个数(x);如果N > 8192 x = x (1:8192);elseifN < 8192垫= 8192 - N;前置液=地板(垫/ 2);postpad =装天花板(垫/ 2);x =[0(前置液,1);x;0 (postpad 1)];结束x = x / max (abs (x));结束
函数x = helperBayesOptLSTM (X_train Y_train、X_val Y_val)%这个函数只用于%”语音数字识别与小波散射和深度学习”%的例子。它可能改变或在将来的版本中被删除。x = @valErrorFun;函数[valError,缺点,文件名]= valErrorFun (optVars)% % LSTM架构[inputSize ~] =大小(X_train {1});numClasses =元素个数(独特(Y_train));层= […sequenceInputLayer inputSize bilstmLayer (optVars.NumHiddenUnits,“OutputMode”,“最后一次”)%使用的隐藏层价值优化变量fullyConnectedLayer (numClasses) softmaxLayer classificationLayer];%的情节不显示在训练选择= trainingOptions (“亚当”,…“InitialLearnRate”optVars.InitialLearnRate,…%利用优化变量的初始学习速率值“MaxEpochs”,300,…“MiniBatchSize”30岁的…“SequenceLength”,“最短”,…“洗牌”,“永远”,…“详细”、假);% %训练网络网= trainNetwork (X_train、Y_train层,选择);% %训练精度X_val_P = net.classify (X_val);accuracy_training = (X_val_P = = Y_val)。/元素个数(Y_val);valError = 1 - accuracy_training;% %保存结果的网络和期权在垫文件在文件夹和错误值的结果文件名= fullfile (“结果”num2str (valError) +“.mat”);保存(文件名,“净”,“valError”,“选项”)缺点= [];结束%对内部函数结束%为外部函数结束
函数X = helperspeechSpectrograms(广告、segmentDuration frameDuration、hopDuration numBands)%这个函数只用于%”语音数字识别与小波散射和深度学习”%的例子。它可能改变或在将来的版本中被删除。%% helperspeechSpectrograms(广告、segmentDuration frameDuration、hopDuration numBands)%计算语音谱图数据存储文件的广告。% segmentDuration是演讲片段的总时间(以秒为单位),% frameDuration每个光谱图帧的持续时间,hopDuration每个光谱图帧之间%时移,numBands的数量%频段。disp (“语音谱图计算……”);numHops =装天花板((segmentDuration - frameDuration) / hopDuration);numFiles =长度(ads.Files);X = 0 ([numBands numHops 1, numFiles],“单一”);为i = 1: numFiles [x,信息]=阅读(广告);x = normalizeAndResize (x);fs = info.SampleRate;frameLength =圆(frameDuration * fs);hopLength =圆(hopDuration * fs);规范= melSpectrogram (x, fs,…“窗口”汉明(frameLength“周期”),…“OverlapLength”frameLength - hopLength…“FFTLength”,2048,…“NumBands”numBands,…“FrequencyRange”[4000]);%如果不如numHops宽光谱图,然后把谱图% X的中间。w =大小(规范,2);地板左= ((numHops-w) / 2) + 1;印第安纳州=左:左+ w1;X(:,印第安纳州,1,i) =规范;如果国防部(我500)= = 0 disp (“加工”+我+“文件”+ numFiles)结束结束disp (“…”);结束% - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -函数x = normalizeAndResize (x)%这个函数只用于%”语音数字识别与小波散射和深度学习”%的例子。它可能改变或在将来的版本中被删除。N =元素个数(x);如果N > 8192 x = x (1:8192);elseifN < 8192垫= 8192 - N;前置液=地板(垫/ 2);postpad =装天花板(垫/ 2);x =[0(前置液,1);x;0 (postpad 1)];结束x = x / max (abs (x));结束
2018年版权MathWorks公司。