使用cnn进行深度学习之所以流行,有三个重要因素:
- CNN消除了人工提取特征的需要——特征直接由CNN学习。
- cnn能产生高度精确的识别结果。
- cnn可以接受重新培训,以完成新的识别任务,使您能够在已有的网络上进行构建。
CNN为发现和学习图像和时间序列数据中的关键特征提供了最佳体系结构。CNN是以下应用中的关键技术:
- 医学成像:CNN可以检查数千份病理报告,以直观地检测图像中是否存在癌细胞。
- 音频处理:任何带有麦克风的设备都可以使用关键字检测,以检测某个单词或短语何时被说出(“嗨,Siri!”)。cnn可以准确地学习和检测关键字,而不管环境如何,忽略所有其他短语。
- 停车标志检测:自动驾驶依靠cnn精确检测标识或其他物体的存在,并根据输出做出决定。
- 合成数据生成:使用生成性对抗网络(GAN)在美国,可以生成新的图像用于人脸识别和自动驾驶等深度学习应用程序。
了解更多

卷积神经网络可以有几十层或数百层,每层都可以学习检测图像的不同特征。滤波器以不同的分辨率应用于每个训练图像,每个卷积图像的输出用作下一层的输入。过滤器可以从非常简单的特征开始,例如亮度和边缘,并增加唯一定义对象的特征的复杂性。万博 尤文图斯
特征学习、层和分类
像其他神经网络一样,CNN由一个输入层、一个输出层和许多隐藏层组成。

这些层执行改变数据的操作,目的是学习特定于数据的特性。最常见的三层是:卷积、激活(ReLU)和池化。
- 卷积将输入图像通过一组卷积滤波器,每个卷积滤波器激活图像中的某些特征。
- 校正线性单元(ReLU)通过将负值映射为零并保持正值,可以实现更快、更有效的训练。这有时被称为激活,因为只有激活的特征才会进入下一层。
- 池通过执行非线性下采样简化输出,减少网络需要学习的参数数量。
这些操作在数十层或数百层中重复,每一层学习识别不同的特征。

具有多个卷积层的网络示例。滤波器以不同的分辨率应用于每个训练图像,每个卷积图像的输出用作下一层的输入。万博 尤文图斯
共同的权重和偏见
像传统的神经网络,CNN的神经元具有权重和偏差。模型在训练过程中学习这些值,并使用每个新的训练示例不断更新这些值。然而,在CNN的情况下,给定层中所有隐藏神经元的权重和偏差值是相同的。
这意味着所有隐藏的神经元都在检测图像不同区域的相同特征,比如边缘或斑点。这使得网络能够容忍图像中物体的平移。例如,一个经过训练的识别汽车的网络将能够识别图像中任何位置的汽车。
分类层
在多层学习特征后,CNN的架构转向分类。
倒数一层是一个完全连接的层,输出K维向量,其中K是网络能够预测的类的数量。这个向量包含任何图像被分类的每一类的概率。
CNN体系结构的最后一层使用诸如softmax之类的分类层来提供分类输出。

深度网络设计师应用程序,交互式构建,可视化,和编辑深度学习网络。
您还可以直接在应用程序中培训网络,并使用准确性、损失和验证指标图监控培训。
使用预先训练的模型进行迁移学习
对预先训练好的网络进行微调转移学习通常比从头开始训练更快更容易。它需要最少的数据量和计算资源。迁移学习用一种问题中的知识来解决类似的问题。你从一个预先训练过的网络开始,用它来学习一项新任务。迁移学习的一个优点是,预先训练的网络已经学习了一组丰富的特征。这些特性可以应用于其他类似的任务。例如,你可以在数百万张图像上训练一个网络,然后再使用数百张图像对它进行新的目标分类。
gpu硬件加速
卷积神经网络是在成百上千甚至上百万的图像上训练的。当处理大量数据和复杂的网络架构时,gpu可以显著加快处理时间来训练模型。

英伟达®GPU,加速计算密集型任务,如深度学习。
了解更多
应用程序使用有线电视新闻网
对象检测
目标检测是对图像和视频中的目标进行定位和分类的过程。计算机视觉工具箱™提供使用YOLO和Faster R-CNN创建基于深度学习的对象检测器的培训框架。

这个例子展示了如何使用深度学习和R-CNN(带卷积神经网络的区域)来训练目标检测器。
关键词检测
语音到文本的一个示例应用是关键字检测,它可以识别某些关键字或短语,并将它们用作指令。常见的例子是唤醒设备和打开灯。
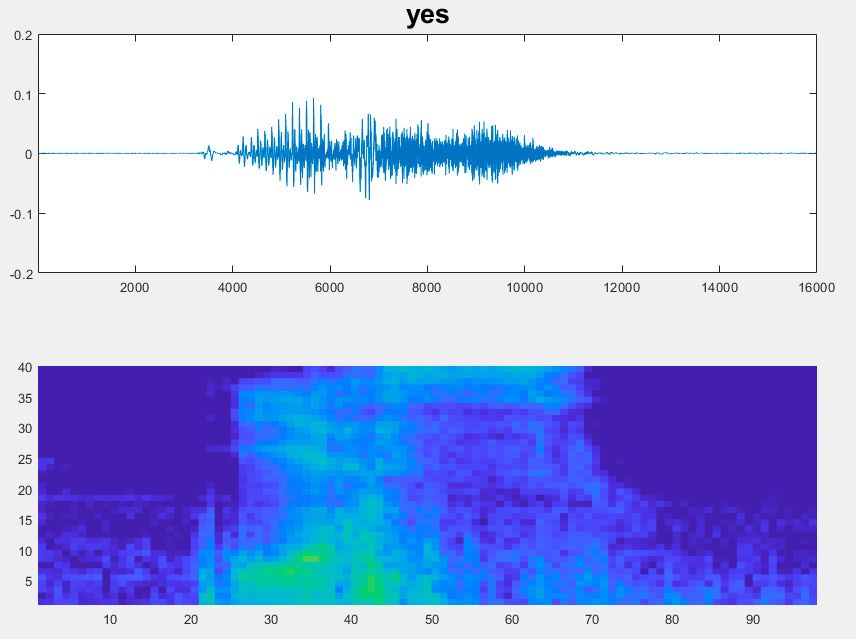
本例展示了如何使用MATLAB识别和检测音频中是否存在语音命令,并可用于语音辅助技术
语义分割
CNN用于语义分割,用相应的类别标签识别图像中的每个像素。语义分割可用于自动驾驶、工业检测、地形分类和医疗成像等应用。卷积神经网络是建立语义分割网络的基础。

本例展示了如何使用MATLAB构建语义分割网络,该网络将使用相应的标签识别图像中的每个像素。
MATLAB为所有深入学习的东西提供了工具和功能。使用CNN增强信号处理、计算机视觉、通信和雷达方面的工作流程。

30天的免费试用

问题?
你也可以从以下列表中选择一个网站: