迁移学习是一种深度学习方法,将为一个任务训练过的模型作为起点,训练一个类似任务的模型。用迁移学习对网络进行微调,通常比从头开始训练网络更快、更容易。该方法通常用于目标检测、图像识别、语音识别等应用。
迁移学习是一种流行的技术,因为:
- 它使您能够利用已经在大型数据集上训练过的流行模型,使用相对较少的标记数据来训练模型。
- 它可以极大地减少训练时间和计算资源。使用迁移学习,模型不需要像新模型那样训练多个纪元(对整个数据集的完整训练周期)。
从零开始训练vs.转移学习
深度学习常用的两种方法是从头开始训练模型和迁移学习。这两种方法都有优点,可以用于不同的深度学习任务。
开发和培训一个从头开始的模型对于那些现有模型不能使用的非常具体的任务更有效。这种方法的缺点是通常需要大量的数据来产生准确的结果—例如,当需要验证文本和大量的数据样本时。如果您无法使用预先训练过的文本分析任务模型,建议从头开始开发模型。
迁移学习对于这样的任务是有用的对象识别,为之流行的各种pretrained模型,如AlexNet和GoogLeNet,可以作为一个起点。例如,如果您有一个植物学项目,需要对花卉进行分类,而可用的数据有限,那么您可以从AlexNet模型转移权重和层,该模型将图像分类为1000个不同的类别,并替换最终的分类层。
从零开始训练模型与迁移学习的比较.
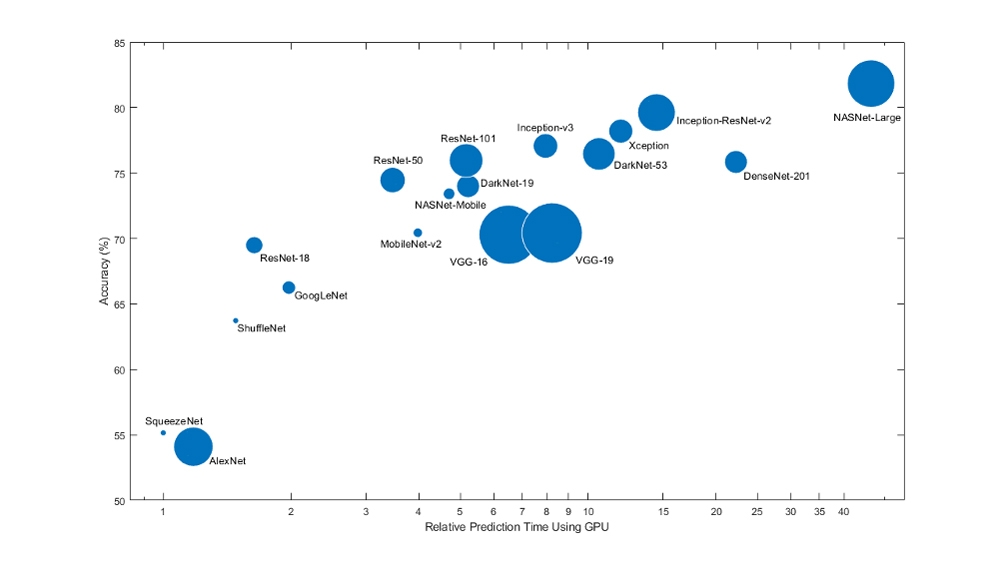
下图显示了迁移学习模型和从零开始训练模型的网络性能。通过迁移学习,可以在更短的时间内实现更高的模型精度。

网络表现训练从无到有和迁移学习.
迁移学习是如何实施的?
该方法通常遵循以下过程步骤:
- 加载一个预先训练的网络。选择一个相关的网络,该网络已经为一个类似于新任务的任务进行了训练。
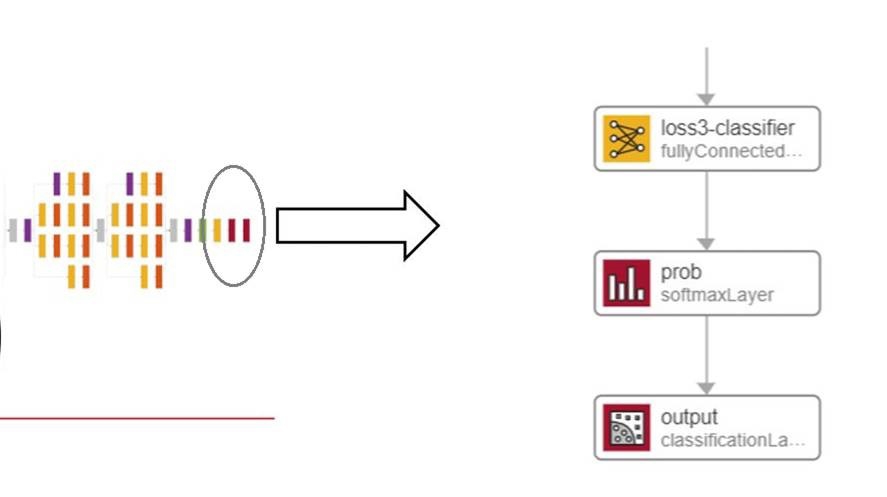
- 替换新任务的分类层。您还可以根据新任务和可用数据选择微调权重。一般来说,拥有的数据越多,可以选择的微调层就越多。在数据较少的情况下,微调可能会导致模型过度拟合。
- 对网络进行新任务的数据培训。
- 测试新网络的准确性。
转移学习工作流程.

