Il强化学习è una tecnica di machine learning in cui un computer (agent) impara a svolgere un 'attività tramite ripetute interazioni di tipo“trial-and-error”(eseguite per tentativi ed errori) con un ambiente dinamico。请所有的学徒同意所有的关于在世界经济发展中所作的决定的决定'attività,在世界经济发展中所作的计划和干预中所作的决定。
我的人工智能程序和强化学习程序在我的电池里,在我的电脑里,在我的电脑里。Mentre il强化学习非è affatto un conetto nuovo, i最近的进展fatti nel campo del深度学习e del potere computazionale hanno contelto di ottenere novoli risultati nel settore dell ' intelligentenza人工智能。
区分强化学习、机器学习和深度学习
Il reinforcement learning è una branca del machine learning (Figura 1).一个不同的机器学习是有监督的,Il reinforcement learning non si affida A unset di dati statici, ma opera in un ambiente dinamico e学徒dalle esperienze raccolte。I punti di dati, o esperienze, vengono raccolti durante l 'addestramento tramite interazioni di tipo“试错”(eseguite per tentativi ed error) tra l 'ambiente e un software (agent)。Questo aspetto del强化学习è importante in quanto riduce le esigenze in termini di raccolta, before - ed etichettatura dei dati prima dell ' dedestramento, operazioni invece must arie nell '学徒to con e senza监管。在实践中,ciò显着的che, con l ' incentive vo giusto, un模型di强化学习è在grado di iniziare ad prenprenere un comportamento autonomamente, senza supervised (dell 'uomo)。
深度学习abbraccia tutti e tre i tipi di机器学习;强化学习和深度学习是相互作用的。I problem mi complessi di reinforcement learning spesso si basano su reti neurali profonde, dando luogo a ciò che viene chiamato深度强化学习。

Figura 1。机器学习的主要类别:徒弟对知觉监督,徒弟对知觉监督和强化学习。

Esempi di applicazioni di强化学习
勒深神经视网膜说明强化学习在编制程序中的应用。Ciò同意我的权利,我的权利,我的权利più困难我的权利,我的权利più传统。自动导航,神经网può我们的决定,来girare il volante utizzando più当代感觉,来i frame delle fotocamere e le misurazioni激光雷达。Senza reti neurali,正常il verrebbe suddidio问题在parti più piccole come l 'estrazione delle特征dai帧delle fotocamere, il filtraggio delle misurazioni激光雷达,la融合degli输出dei感官E la presa di decisioni di“guida”在基础agli输入感官。
Sebbene l 'approccio tramite强化学习sia ancora在生产系统的价值评估中,应用工业的alcune sembrano rivelarsi particolarmente adatte all 'implementazione di questesta技术。
控制avanzati:非线性系统的控制è在不同的操作系统的对应关系中,与线性系统相关的问题。Il强化学习può非线性系统的应用。
Guida自治: prendere decision oni di guida in base all 'input di una fotocamera è un 'attività in cui il reinforcement learning si dimostra idoneo, concondodo il successo delle reti neurali profonde nelle applicazioni con immagini。
Robotica: il强化学习può essere utitile in applicazioni come la presa (grasp) da parte dei robot, AD esempio per inseggnare a UN braccio robotico a manpolare diverse tipologie di oggetti per applicazioni di tipo pick-and-place。Altre applicazioni nel campo della robotica inclono la collaborazione uomo-robot e robot-robot。
Pianificazione:我的问题是在不同的情况下,我无法控制事态的发展,我无法协调事态的发展,我无法决定事态的发展。Il强化学习è每risolverproblem di timizazione combinatoria。
Calibrazione: le applicazioni che prevedono una calibrazione manual dei parameter, come la calibrazione delle unità di controllo电子(ECU),所有强化学习的实现。
这是一个强化学习的方法。considiamo, per esempio, l 'addestramento degli animal domestic tramite rinforzo positive。

Figura 2。强化学习是不可避免的。
Usano la术语学del强化学习(Figura 2), l 'obiettivo dell '学徒在questo caso è quello di addestrare un cane(代理)affinché completi un 'attività所有'interno di un ambiente, che包括l 'ambiente che circonda il cane e la persona che si occupa dell 'addestramento。主使者,主使者dà主使者,主使者。Il cane, poi, risponde, con un 'azione我想要的东西,可能的事情offrirà你的钱,你的鳄鱼,你的鳄鱼;Altrimenti,非verrà offerta alcuuna ricompensa。所有的'inizio dell 'addestramento, il cane概率risponderà con azioni più casuali, ad esempio rotolandosi al comando " seduto ",在quanto sta cercando di associare delle osservazioni specifiche delle azioni e delle ricompense。我的政治,我的政治,我的政治。我的命运命运,我的命运命运,così我的命运命运。Quindi,强化学习的终极目标包含了“regolare”la politica del cane在“modo che学徒行为需要能力”和“massimizzare la ricompensa”中。我的行为结束了,我的行为是正确的,我的行为是正确的,我的行为是正确的,我的政治是正确的。 A questo punto, i premi sono ben accetti ma, in teoria, non dovrebbero più essere necessari.
Tenendo a mente l 'esempio dell 'addestramento del cane, conthiiamo l 'attività di dover parcheggiare un veicolo usando un sistema di guida autonoma (Figura 3). l 'obiettivo è quello di insegnare al computer del veicolo (agent) a parcheggiare nello spazio corretto con il reinforcement learning。Come nel caso del cane, l 'ambiente è tutto ciò che si trova all 'esterno dell 'agente e potrebbe包括la dinamica del veicolo, altri veicoli nelle vicinanze, le condizioni atmosphere e così via。Durante l ' destramento, l '代理商美国视觉质量测量系统,GPS和激光雷达(osservazioni)根据一般视距测量(azioni),加速系带。“试错”的翻译是:“每一个试试看的错误”。每一个价值'idoneità我的尝试,我的过程,我的学徒到può我必须得到,我的利益。
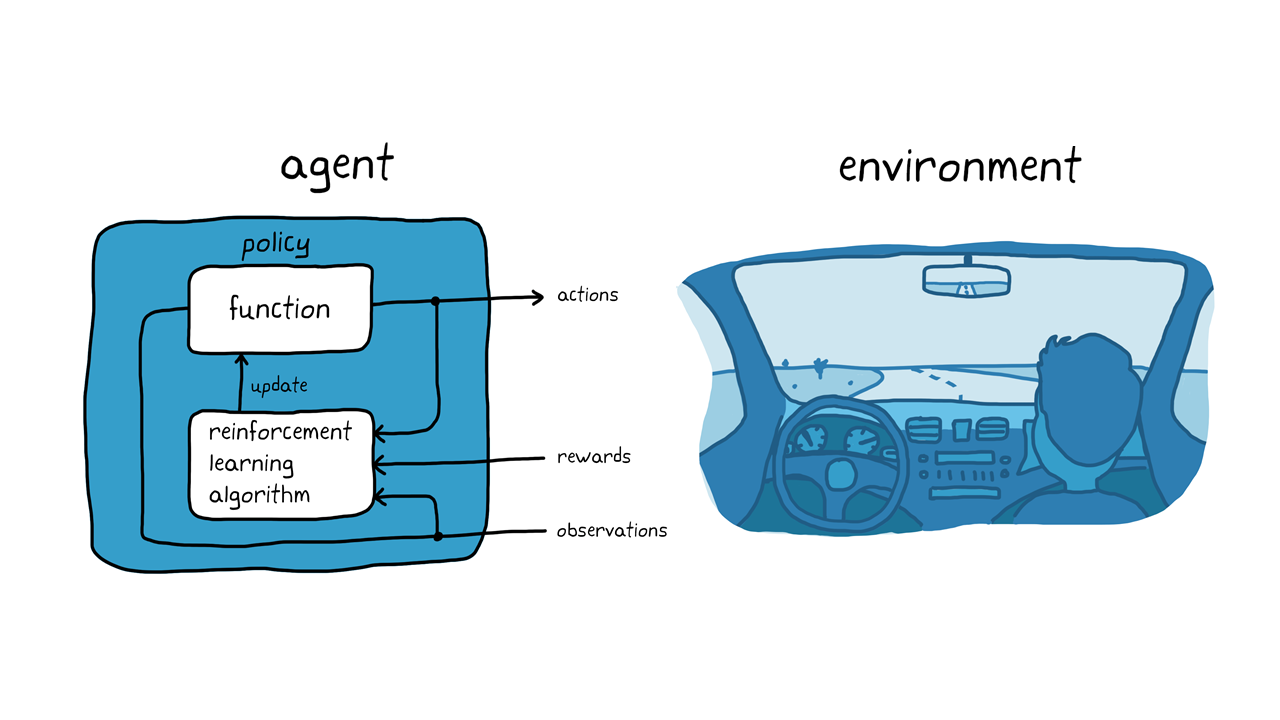
Figura 3。强化学习脑自主神经。
甘蔗之神,甘蔗之神。自治之路,路之路è路之路之路之路。我的算法,我的思想,我的思想responsabilità我的思想,我的政治,我的思想,我的权利,我的权利。终点站,我的电脑,我的生命之路,我的思想之路,我的政治之路,我的感官之课。
Un aspetto da tenere a mente è che il强化学习非è sottoposto al principio di样本效率。Ciò意会ha bisogno di unalto数字di interazioni tra l 'agente l 'ambiente per raccogliere i dati per l 'addestramento。AlphaGo, AlphaGo,每台计算机的首要程序,è在计算机上运行,在计算机上运行,è在计算机上运行,在计算机上运行,è在计算机上运行,在计算机上运行。对事物的应用,对事物的时间,对事物的所有权,以及对事物的分分秒秒,对事物的所有权。在più中,在quanto bisogna prendere tutta a serie di decision oni di progettazione e, prima raggiungere il risultato desiderato, potrebbero servire多样化iterazioni的问题。Tra queste, per esempio, vi sono la selezione dell ' architecture, a appropriata per le视网膜,la regolazione, degli iperparametri, la conformazione, del segnale di ricompensa。
强化学习工作流
强化学习的一般工作流程包括le seguenti fasi(图4):

Figura 4。工作流del强化学习。
1.Creazione戴尔'ambiente
Prima di tutto è必要的定义环境所有的内部质量andrà ad operare l ' agent di强化学习,压缩l 'interfaccia tra - agente ambiente。我们的环境può我们的环境是模拟的,我们的环境是模拟的,我们的环境是模拟的perché我们的环境是模拟的,我们的环境是实验的。
2.定义,della ricompensa
在seguto, è需要具体的,我的国家,我的国家,我的国家,我的国家,我的国家,我的国家'attività e la modalità我的国家,我的国家,我的国家。敢为我们提供各种各样的服务。
3.Creazione戴尔'agente
一个问题的punto è必要的creare l ' agent,宪法的政治和dall '算法di dedestramento del强化学习。如果产品开发:
a)“政治上的记忆”(“我们对神经的记忆和查阅”)。
b)恰当地使用算法。不同的表达方式,不同的表达方式,不同的分类,不同的算法,不同的方式。总的来说,però, gli algorithm di reinforcement learning moderni basano In gran parte su reti neurali, che si prestano bene a problem mi complessi e spazi di stato/azione di grandi dimension。
4.我们的康复之道
“来我的标准”和“来我的政策”。这是政治的终结,没有共同发展的空间。Se必要,è可能的河流,le scelte di progettazione来,il sergnale di ricompensa el ' architecture della politics e程序,nuovamente all 'addestramento。Il强化学习è un processo generalmente noto per non sottostare al principio di sample efficiency;L 'addestramento può在我的脑海里有一分钟的记忆,在我的脑海里有一种特殊的感觉。Per le applicazioni complesse, la parallelizzazione dell 'addestramento su più CPU, GPU e cluster di computer renderà il processo più veloce(图5)。
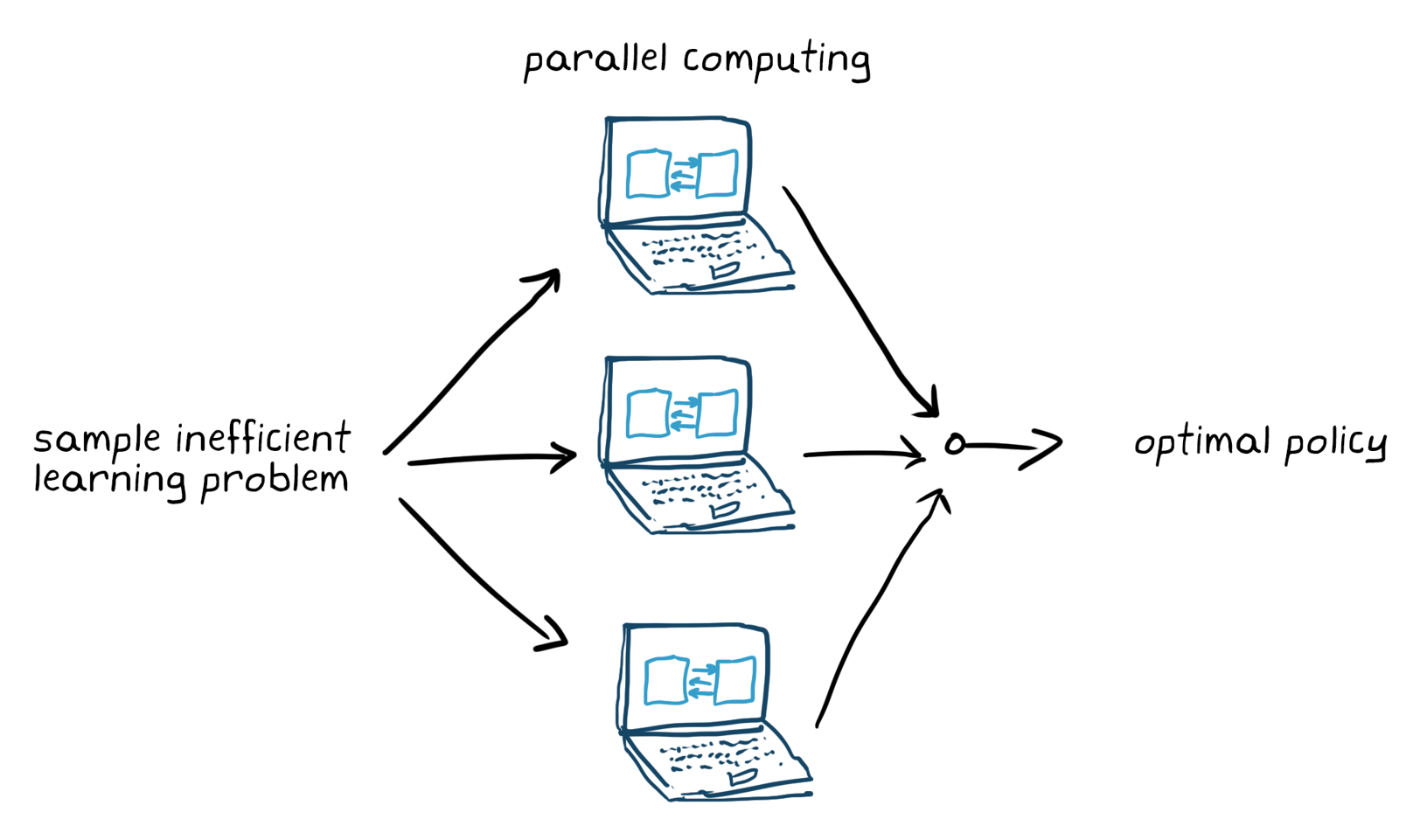
Figura 5。在平行计算的情况下,对样本效率的非响应性原理进行了解释。
5.分配政治
在C/ c++生成过程中,CUDA / c++生成程序。政治问题è独立决策系统。
L 'addestramento di un agent tramite强化学习è un processo iterativo。一个决定,一个分析,一个方法,一个连续的,丰富的,一个方法,一个工作流程,一个学徒。在这个过程中,在这个过程中,在这个过程中,政治是不可收敛的在这个过程中,在这个过程中,政治是可以接受的在这个过程中,在这个过程中,政治是可以接受的
- Impostazioni di addestramento
- configuration azione dell 'algoritmo di强化学习
- 政治的和谐
- 定义
- Segnali di osservazione e azione
- Dinamica戴尔'ambiente
MATLAB®e强化学习工具箱™Semplificano le attività di强化学习。È可能实现的控制器和算法,根据预先决策系统,根据预先决策系统,机器人和自动系统,根据定期流程和工作流程,基于强化学习。尼洛特罗,è可能:
1.创建真菌环境MATLAB Simulink万博1manbetx®
2.我们使用深神经视网膜,polinomi表查找根据定义的强化学习
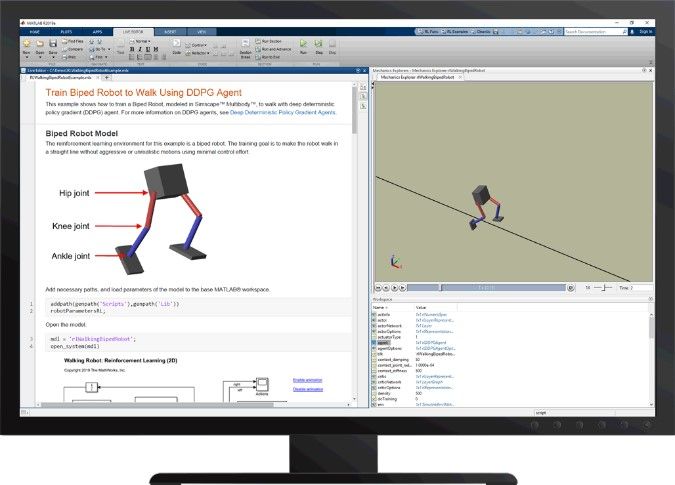
图6 Insegnare一个非机器人两足动物camminare con强化学习工具箱™
3.Cambiare, valutare e对抗gli algoritmi di强化学习più conosciuti come DQN, DDPG, PPO e SAC apportando solo modifiche di piccola entità al codice, oppure creare il本体algoritmo personalizzato
4.Usare并行计算工具箱eMATLAB并行服务器per addestrare le politiche di reinforcement learning più velocemente servendosi di più GPU, più CPU, cluster di computer e risorse Cloud
5.通用编码分配策略强化学习su配置嵌入式con MATLAB Coder™e GPU Coder™
6.强化学习是一种非常实用的方法“爱你”.
Per saperne di più sul强化学习



Argomenti complementari




30分的小费之夜

海una domanda?
您也可以从以下列表中选择一个网站: