文本分析工具箱
analisi e modellazione di di di testo
Text Analytics Toolbox™fornisce algitmi e visualizazioni per pre- laborazione, l 'analisi ela modelazzione di dati di testo.文本分析工具箱™可视化算法。在情感分析、预测和主题建模的应用中,我建立了一个具有重要意义的工具箱。
文本分析工具箱包括每个L'Elaborazione Di Testi Non Elaborati Estratti Da Registri Delle Apperecchiature,Sondaggi,举报Di Operatori E社交媒体。èCositibileStrarreTesto Dai Formatii Di FilePińFormusi,Elaborare Testo Non Elaborato,Estrarre Singole Parole,Rendire Testo在Rappresentioni Numeriche E Sviluppare Modelli Statistici。
Urilitizzando le tecniche di机器学习Quali LSA,LDA E Word Embedding,è可能Trovare Cluster E CRALE特征DI DI DI DI Testo di Grandi Diminsioni。LE功能创建孔文本分析工具箱Possono Essere Compinated Con Le Featuring Di Altre Fonti Di Dati Per SvilupPare Modelli Di Machine Learning Che Sfruttano Dati Di Testo,Numerici E di Altro Tipo。
Inizia Ora:

在我的身体里注射雌二醇
在MATLAB中很重要®文件,包括PDF, HTML, Microsoft®单词®e Excel®.
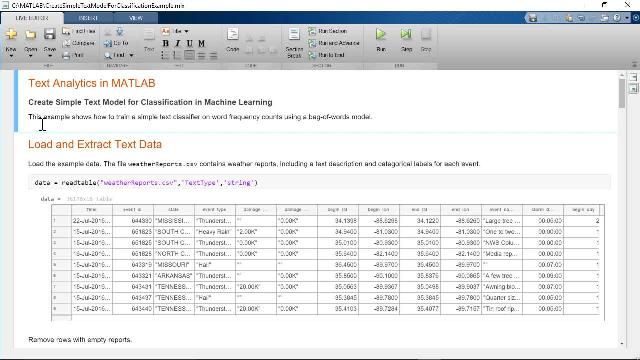
Estrazione di Testo da Una Serie di Documenti Microsoft Word。
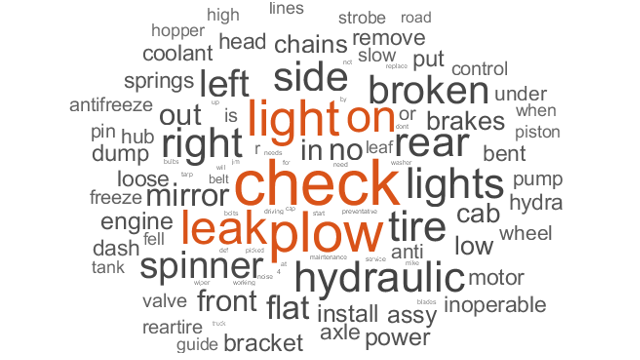
Word Cloud Che Illustra La Chareza Relativa Delle假释假释Sulla Base Selle Dimensioni e del Colore del字体。
万博1manbetxSupporto linguistico
文本分析工具箱fornisce funzionalità di pre- laborazione具体每一种语言,giapponese, tedesca e coreana。这句话的意思是funzionalità è兼容的。

这是一种非常重要的食品。
普利西亚,我的朋友,我的朋友
应用程序过滤的其他内容包括URL, HTML标签,以及其他内容。

每一种语言都有意义più有意义的(删除)。
停止词e常态化假释词真主安拉形式的根
戴先生AI DIAI DI Testo意义上的尼拉·雅拉analisi filtrando le Parole Comuni,Quelle Che Compaiono Troppo Muthentemente o Raramente,Quelle Molto Lunghe o Molto Brevi。LIMITA IL Leaseico E Spectioni Sul SensoPiùianaleO Sul Sentement di UN Documento,eseguendo lo Stemming delle Parole Alla Loro Forma Radice O Trantendole在Lemmi。
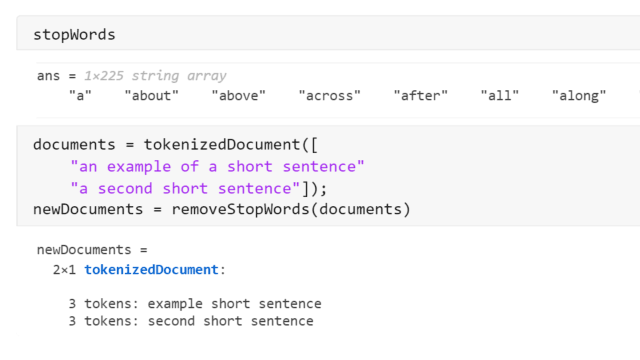
Rimozione di stop word come articoli e preposizioni(“un”e“di”,per esempio) dai documenti。
每个人都有自己的标志,并且都有自己的标识
Dividi自身名IL Testo非Elaborato在Una Serie di Parole Utilizzando联合国alloritmo di tokenizzazione。Aggiungi I Limiti Delle Frasi,Le Varie Parti Del Discorso E Altre Inforazioni Rilevanti Per IL竞赛。
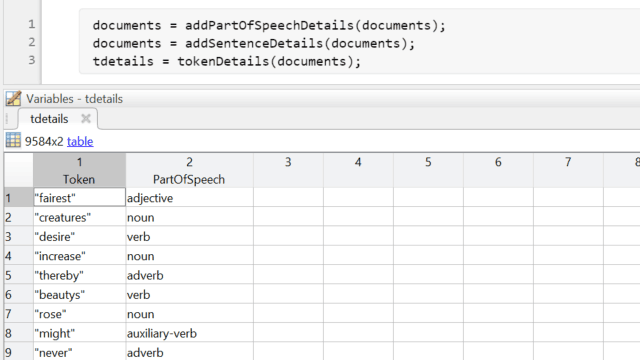
这是一种相对的、与文献相关联的、具有象征意义的观点。
我的假释
Calcola Le Statistiche di Frantenza Parle Parole按Rappresentare Numericamente I Dati Di Testo。
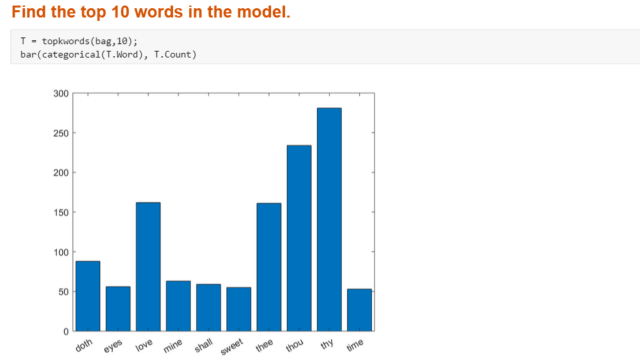
Indinduazione eScieSizzione将Parole Che RicorronoPIù频繁在UN Modello中。
嵌入e codifica的词
单词嵌入的模型是word2vec, CBOW(连续词袋)和skip gram。输入模型之前的添加层是快速的文本手套。
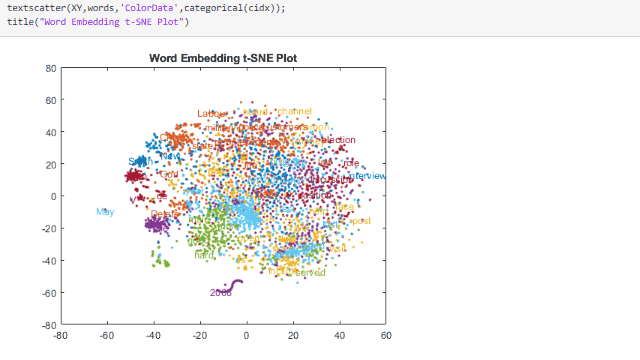
Un Grafico的Visualizzaione dei群集A Dispersione di Testo诱导词嵌入。
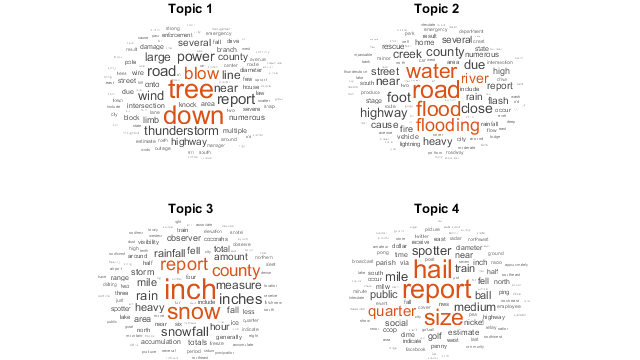
个人的主题是最近的一次报告。
Sintesi记录了雌激素的释放
Estrai自动名称Una Sintesi e Le Parole Chiave Rilevanti da Uno oPiùofficei e valuta i documenti在termini di importanza e somiglianza。
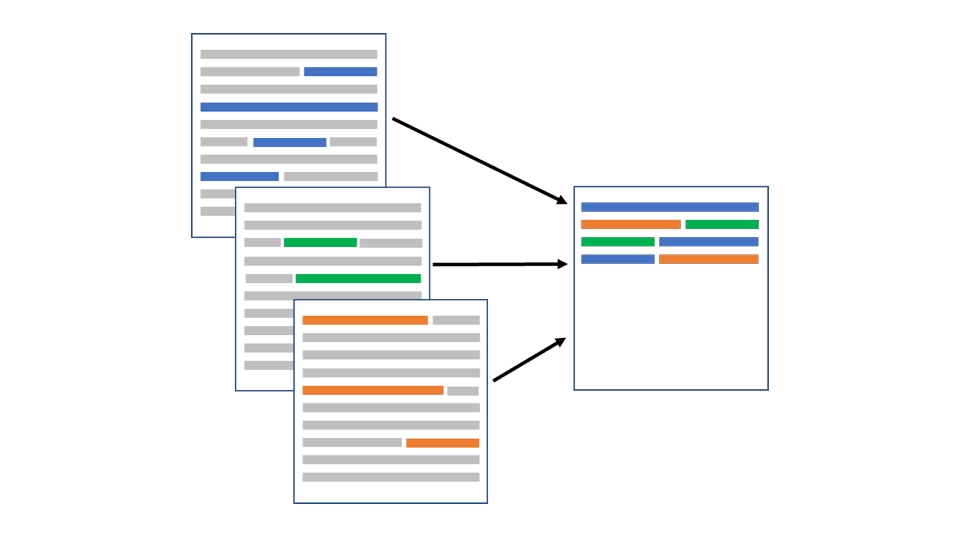
这是一个非常好的例子。
情绪分析
它是意大利浓咖啡中最常见的一种,分为阳性,中性和阴性。在现实节奏中,我们的情感是先于情感的。

判断情绪是积极的还是消极的。
Modelli di Traasformatori.
转换模型采用BERT GPT-2的方法在迁移学习的基础上采用attività的情感分析,分类方法。

对迁移学习的变换模型的建立。
Classificazione del服务
在深度学习的分级识别和类别识别中,利用单词嵌入进行分类描述。
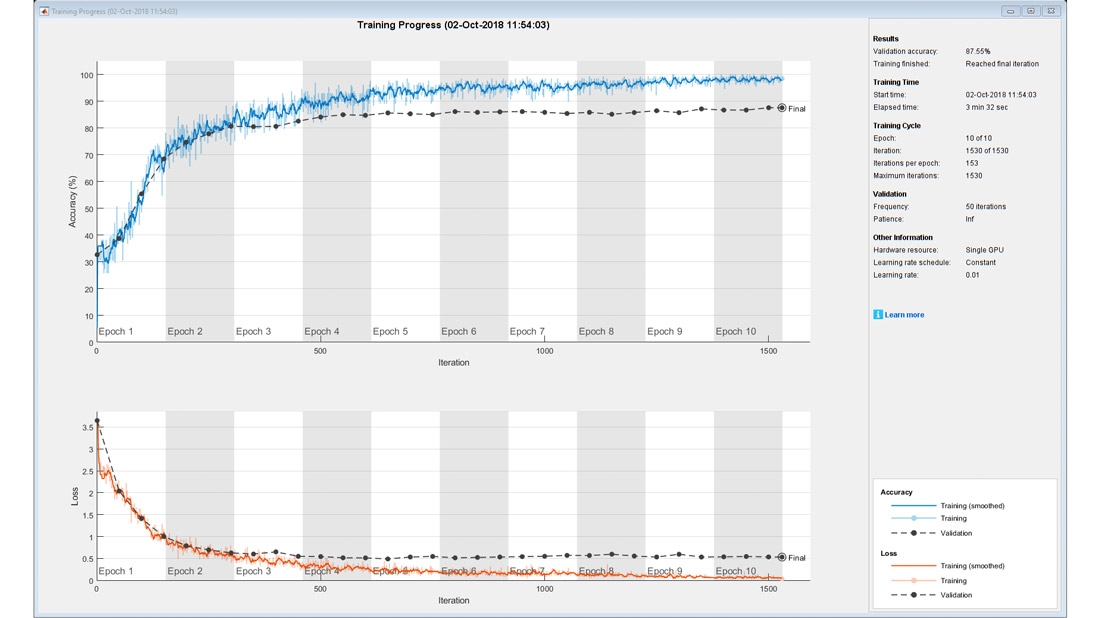
每一种类型的前神经网均有不同程度的损伤。
Generazione di服务
uncerizza il每一个遗嘱诺维迪Testi Basati Sui Testi Ossirati。
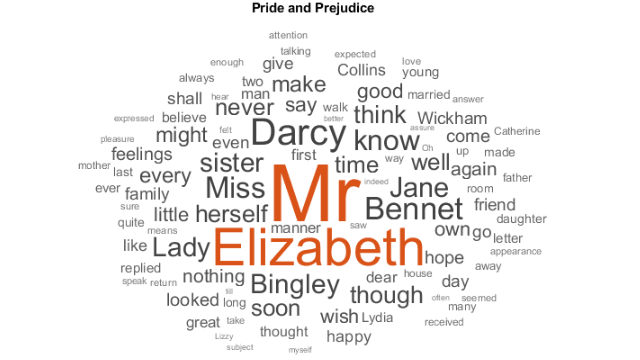
我想用它来解决问题Orgoglio e pregiudizioDi Jane Austen E UNA RETE LSTM DI深入学习。