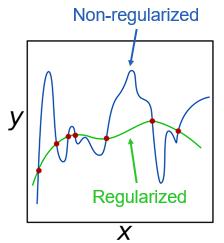
正則化は,モデルを用いた予測を行う際に生じうる過適合の防止に使用できます。正則化はペナルティを使いますが、このペナルティとして、例えば、最小化問題における目的関数にモデル係数を追加する、あるいは、関数としての滑らかさの対としての乱雑度を追加するなどします。情報を追加することで、モデル (目的関数) は簡素 (parsimonious) にそして正確になるため、多重共線性や冗長な予測子を処理することができます。
一般的な正則化手法としては,リッジ回帰(Tikhonov正則化とも呼ばれる),套索および弹性净アルゴリズム,収縮重心法のほか,トレースプロット,交差検証済み平均二乗誤差などがあります。また,赤池情報量基準(AIC)を適合度の指標として適用することも可能です。
正則化の各手法の特徴は以下になります。
- 套索はL1ノルムを使用し,各々の係数の値を,強制的にゼロにしようとします。そのため,套索は特徴選択アルゴリズムとして非常にうまく機能します。なぜなら,係数の値がゼロにならない変数は重要であり,かつ,少数だからです。
- リッジ回帰は係数に対してL2ノルムを使用します(平均二乗誤差の合計を最小化します)。リッジ回帰は多数の係数に対し、各々の変数に対する重み (係数の値) を全体的に低減させる傾向があります。モデルに多数の係数を含めることが必要と考えられる場合は、おそらくリッジ回帰の手法が適しています。
- 弹性网は,重要な変数が多数あることがわかっている場合,このうちの一部しか選択できない套索の問題点を補うことができます。
正則化はモデルが使用する予測子を強制的に減らすという点で特徴選択に関連しています。正則化法にはいくつかの顕著な利点があります。
- 正則化手法は(一変量特徴選択を除き)大半の特徴選択法よりもはるかに大きなデータセットに対応することができます。套索とリッジ回帰は数千,ひいては数万の変数を含むデータセットに適用することができます。
- 正則化アルゴリズムは多くの場合,特徴選択よりも正確な予測モデルを生成します。また,特徴選択は離散空間で行われますが,正則化は連続空間で行われます。そのため,正則化は多くの場合モデルを微調整してさらに正確な推定を行うことができます。
とはいえ特徴選択法にも利点があります。
- 特徴選択の方がやや直感的で第三者への説明もし易いのです。これは結果を共有する際に,使用した手法を説明する必要がある場合に非常に有用です。
- MATLAB®と统计和机器学习工具箱™は一般的な正則化手法のすべてをサポートしており,線形回帰,ロジスティック回帰,サポートベクターマシン,および線形判別分析に利用できます。ブースティングされた決定木など他のモデルタイプを使用している場合は,特徴選択を適用する必要があります。
重要なポイント
- 正則化は(特徴選択と並び)予測モデルでの統計的過適合を防止するために使用されます。
- 線形モデリングを取り扱うことの多い機械学習の問題に対して,連続空間で行われる正則化は,離散的な特徴選択よりも優れた性能を発揮します。
シナリオの例
現在あなたはがん研究を行っていると仮定します。あなたは500人のがん患者の遺伝子配列を持っており,15000種類の遺伝子のうちどの遺伝子ががんの進行に有意な影響をもたらすかを判断しようとしています。最小冗余最大关联や近傍成分分析などの特徴量ランク付け法のいずれか,または実行時間について懸念がある場合は一変量特徴選択を適用することができます。ただ,これほど多くの変数があるため逐次特徴選択だけは全く実用性がありません。あるいは,正則化を使用してモデルを検討することもできます。リッジ回帰は、強制的に係数をゼロにするため計算コストが大きく、不向きです。また、500 種類超の遺伝子の特定が必要な可能性があるため、LASSO も使用できません。Elastic Net が考えられるソリューションの一つです。