このページの翻訳は最新ではありません。ここをクリックして,英語の最新版を参照してください。
次元削減と特徴抽出
“特徴変換”手法では,データを新しい特徴量に変換することによりデータの次元を減らします。“特徴選択”手法は,カテゴリカル変数がデータに含まれている場合など,変数を変換できない場合に適しています。特に最小二乗近似に適している特徴選択手法については,ステップワイズ回帰を参照してください。
関数
オブジェクト
トピック
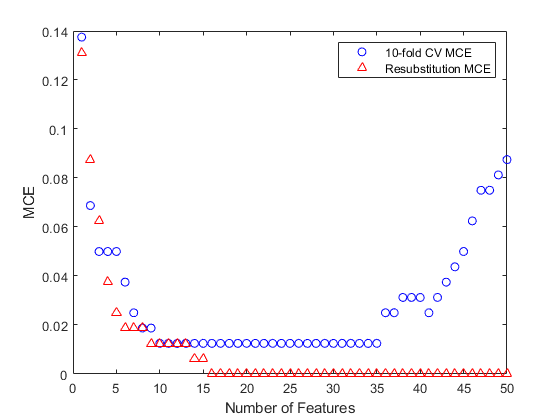
特徴選択
特徴選択アルゴリズムについて学び,特徴選択に使用できる関数を確認します。
このトピックでは,逐次特徴選択の基本を説明し,カスタム基準と関数sequentialfsを使用して逐次的に特徴量を選択する例を示します。
近傍成分分析(NCA)は,特徴量を選択するためのノンパラメトリックな手法であり,回帰および分類アルゴリズムの予測精度を最大化することを目的とします。
モデルの予測力を損なわずに予測子を削除して,よりロバストで簡潔なモデルを作成します。
交互作用検定アルゴリズムを使用してランダムフォレストの分割予測子を選択します。
特徴抽出
特徴抽出は,高レベルの特徴をデータから抽出する一連の方法です。
この例では,イメージデータからの特徴抽出を行う完全なワークフローを示します。
この例では,黎加を使用して混合オーディオ信号を分離する方法を示します。
t-SNE多次元可視化
t-SNEは,元のデータの一部の特徴量を保持したまま2または3次元への非線形削減を行うことにより高次元データを可視化する方法です。
この例では,高次元データの有用な低次元埋め込みをt-SNEで作成する方法を示します。
この例では,さまざまなtsneの設定の影響を示します。
出力関数の説明とt-SNEの例です。
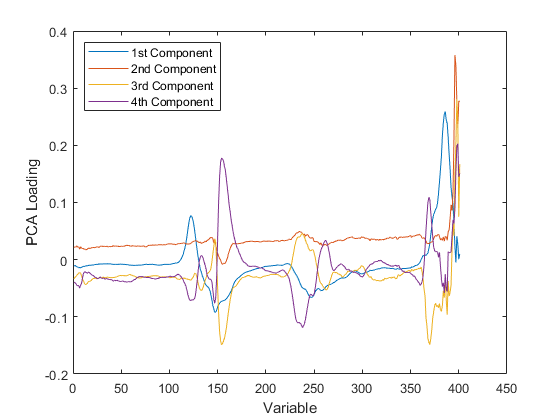
PCAと正準相関
主成分分析では,相関関係がある複数の変数を元の変数の線形結合である新しい一連の変数に置き換えることにより,データの次元を削減します。
重み付き主成分分析を実行し,結果を解釈します。
因子分析
因子分析は,多変量データにモデルをあてはめることにより,少数の観測されない(潜在的な)因子に対する測定された変数の相互依存を推定する方法です。
因子分析を使用して,同じ部門の会社では株価が週単位で同じように変化しているかどうかを調べます。
この例では、统计和机器学习工具箱™を使用してクラスター分析を実行する方法を示します。
非負値行列因子分解
"非負値行列因子分解"(“NMF”)は特徴空間の低ランク近似に基づく次元削減手法です。
乗法アルゴリズムおよび交互最小二乗アルゴリズムを使用して非負値行列因子分解を実行します。
多次元尺度構成法
多次元尺度構成法では,多くの種類の距離または非類似度の尺度について点と点の近さを可視化し,データを低次元で表現することができます。
cmdscaleを使用して従来型の(計量)多次元尺度構成法(別名“主座標分析”)を実施します。
この例では、统计和机器学习工具箱™の関数cmdscaleを使用して古典的な多次元尺度構成法(MDS)を実行する方法を示します。
この例では,古典的でない多次元尺度構成法(MDS)を使用してデータの相違性を可視化する方法を示します。
mdscaleを使用して非従来型の多次元尺度構成法を実行します。
プロクラステス解析
プロクラステス解析では,最良の形状維持ユークリッド変換を使用して,比較したランドマークデータ間の位置の違いを最小化します。
プロクラステス解析を使用して2つの手書きの数字を比較します。
注目の例

你也可以从以下列表中选择一个网站:
