このページの翻訳は最新ではありません。ここをクリックして,英語の最新版を参照してください。gydF4y2Ba
fsulaplaciangydF4y2Ba
ラプラシアンスコアを使用して教師なし学習の特徴量をランク付けgydF4y2Ba
構文gydF4y2Ba
説明gydF4y2Ba
idxgydF4y2Ba= fsulaplacian (gydF4y2BaXgydF4y2Ba)gydF4y2BaXgydF4y2Baの特徴量(変数)をランク付けします。関数はgydF4y2BaidxgydF4y2Baを返します。これには特徴量の重要度順に並べ替えられた特徴量のインデックスが含まれます。gydF4y2BaidxgydF4y2Baを使用して,教師なし学習用の重要な特徴量を選択できます。gydF4y2Ba
idxgydF4y2Ba= fsulaplacian (gydF4y2BaXgydF4y2Ba,gydF4y2Ba名称,值gydF4y2Ba)gydF4y2Ba“NumNeighbors”,10gydF4y2Baを指定すると10個の最近傍を使用してgydF4y2Ba類似度グラフgydF4y2Baを作成できます。gydF4y2Ba
[gydF4y2Baは,前の構文におけるいずれかの入力引数の組み合わせを使用して,特徴量スコアgydF4y2BaidxgydF4y2Ba,gydF4y2Ba分数gydF4y2Ba) = fsulaplacian (gydF4y2Ba___gydF4y2Ba)gydF4y2Ba分数gydF4y2Baも返します。大きなスコア値は,対応する特徴量が重要であることを示します。gydF4y2Ba
例gydF4y2Ba
重要度を基準とした特徴量のランク付けgydF4y2Ba
標本データを読み込みます。gydF4y2Ba
负载gydF4y2Ba电离层gydF4y2Ba
重要度に基づいて特徴量をランク付けします。gydF4y2Ba
[idx,分数]= fsulaplacian (X);gydF4y2Ba
特徴量の重要度スコアの棒グラフを作成します。gydF4y2Ba
栏(分数(idx))包含(gydF4y2Ba“功能等级”gydF4y2Ba) ylabel (gydF4y2Ba“功能重要性分数”gydF4y2Ba)gydF4y2Ba
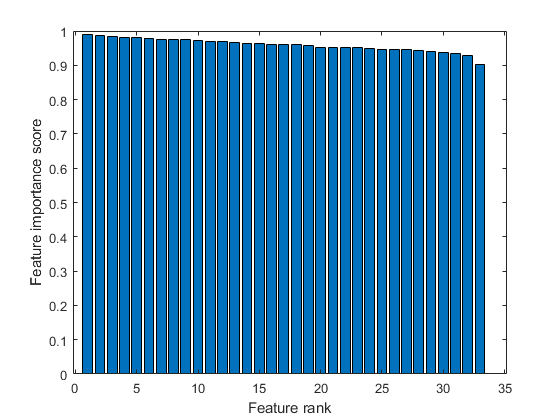
上第五位つの最も重要な特徴量を選択します。gydF4y2BaXgydF4y2Baにおけるこれらの特徴量の列を求めます。gydF4y2Ba
idx (1:5)gydF4y2Ba
ans =gydF4y2Ba1×5gydF4y2Ba15 13 17 21 19gydF4y2Ba
XgydF4y2Baの15列目が,最も重要な特徴量です。gydF4y2Ba
指定された類似度行列を使用した特徴量のランク付けgydF4y2Ba
フィッシャーのアヤメのデータセットから類似度行列を計算し,類似度行列を使用して特徴量をランク付けします。gydF4y2Ba
フィッシャーのアヤメのデータセットを読み込みます。gydF4y2Ba
负载gydF4y2BafisheririsgydF4y2Ba
既定のユークリッド距離計量で関数gydF4y2BapdistgydF4y2BaとgydF4y2BasquareformgydF4y2Baを使用して,gydF4y2Ba量gydF4y2Baに含まれている観測値の各ペア間の距離を求めます。gydF4y2Ba
D = pdist(量);Z = squareform (D);gydF4y2Ba
類似度行列を作成し,これが対称であることを確認します。gydF4y2Ba
S = exp (- z ^ 2);issymmetric (S)gydF4y2Ba
ans =gydF4y2Ba逻辑gydF4y2Ba1gydF4y2Ba
特徴量をランク付けします。gydF4y2Ba
idx = fsulaplacian(量,gydF4y2Ba“相似”gydF4y2Ba,年代)gydF4y2Ba
idx =gydF4y2Ba1×4gydF4y2Ba3 4 1 2gydF4y2Ba
類似度行列gydF4y2Ba年代gydF4y2Baを使用したランク付けは,gydF4y2Ba“NumNeighbors”gydF4y2BaをgydF4y2Ba尺寸(量,1)gydF4y2Baとして指定することによるランク付けと同じです。gydF4y2Ba
idx2 = fsulaplacian(量,gydF4y2Ba“NumNeighbors”gydF4y2Ba、尺寸(量,1))gydF4y2Ba
idx2 =gydF4y2Ba1×4gydF4y2Ba3 4 1 2gydF4y2Ba
入力引数gydF4y2Ba
出力引数gydF4y2Ba
詳細gydF4y2Ba
アルゴリズムgydF4y2Ba
参照gydF4y2Ba
他,X., D. Cai, P. Niyogi。"特征选择的拉普拉斯分值"少量的诉讼。2005。gydF4y2Ba
选择网站gydF4y2Ba
选择一个网站,在那里获得翻译的内容,并看到当地的活动和优惠。根据您的位置,我们建议您选择:gydF4y2Ba.gydF4y2Ba
选择gydF4y2Ba网站gydF4y2Ba你也可以从以下列表中选择一个网站:gydF4y2Ba
美洲gydF4y2Ba
- 美国拉丁gydF4y2Ba(西班牙语)gydF4y2Ba
- 加拿大gydF4y2Ba(英语)gydF4y2Ba
- 美国gydF4y2Ba(英语)gydF4y2Ba
欧洲gydF4y2Ba
- 比利时gydF4y2Ba(英语)gydF4y2Ba
- 丹麦gydF4y2Ba(英语)gydF4y2Ba
- 德国gydF4y2Ba(德语)gydF4y2Ba
- 西班牙gydF4y2Ba(西班牙语)gydF4y2Ba
- 芬兰gydF4y2Ba(英语)gydF4y2Ba
- 法国gydF4y2Ba(法语)gydF4y2Ba
- 爱尔兰gydF4y2Ba(英语)gydF4y2Ba
- 意大利gydF4y2Ba(意大利语)gydF4y2Ba
- 卢森堡gydF4y2Ba(英语)gydF4y2Ba
- 荷兰gydF4y2Ba(英语)gydF4y2Ba
- 挪威gydF4y2Ba(英语)gydF4y2Ba
- 奥地利gydF4y2Ba(德语)gydF4y2Ba
- 葡萄牙gydF4y2Ba(英语)gydF4y2Ba
- 瑞典gydF4y2Ba(英语)gydF4y2Ba
- 瑞士gydF4y2Ba
- 联合王国gydF4y2Ba(英语)gydF4y2Ba
亚太地区gydF4y2Ba
- 澳大利亚gydF4y2Ba(英语)gydF4y2Ba
- 印度gydF4y2Ba(英语)gydF4y2Ba
- 新西兰gydF4y2Ba(英语)gydF4y2Ba
- 中国gydF4y2Ba
- 日本gydF4y2Ba(日本語)gydF4y2Ba
- 한국gydF4y2Ba(한국어)gydF4y2Ba
