このページの翻訳は最新ではありません。ここをクリックして,英语の最新版を参照してください。
fscmrmr
最小冗余最大相关性(MRMR)アルゴリズムを使用した分类用の特徴量のランク付け
构文
说明
idx.= fscmrmr(TBL那ResponseVarName)TBLには予测子変数と応答変数が含まれていて,ResponseVarNameはTBL内の応答変数の名前です。关数はidx.を返します。これには予测子の重要度顺に并べ替えられた予测子のインデックスが含まれます。idx.を使用して,分类问题用の重要な予测子を选択できます。
例
重要度を基准とした予测子のランク付け
标本データを読み込みます。
加载电离层
重要度に基づいて予测子をランク付けします。
[IDX,分数] = fscmrmr(X,Y);
予测子の重要度スコアの棒グラフを作成します。
栏(分数(IDX))xlabel(“预测排名”)ylabel(“预测变量重要性评分”)
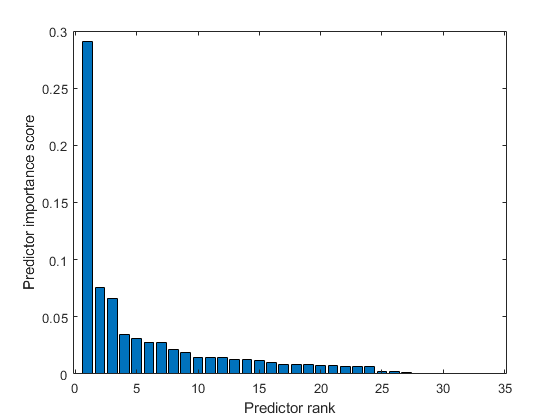
最も重要な予测子の1番目と2番目の间のスコアの下落は大きいですが,6番目の予测子の后は比较的小さいです。重要度スコアの下落は,特徴选択の信頼度を表します。したがって,大きな下落は,ソフトウェアが确実に最も重要な予测子を选択していることを示します。小さな下落は,予测子の重要度の差が有意ではないことを示します。
上位5つの最も重要な予测子を选択します。Xにおけるこれらの予测子の列を求めます。
IDX(1:5)
ans =.1×55 4 1 7 24
Xの5列目が,yの最も重要な予测子です。
特徴量の选択と2つの分类モデルの精度の比较
fscmrmrを使用して重要な予测子を検出します。次に,testckfold.を使用して,完全分类モデル(すべての予测子を使用する)と上位5つの重要な予测子を使用する次元削减されたモデルの精度を比较します。
census1994データセットを読み込みます。
加载census1994
census1994内のテーブルadultdataには,个人の年收が$ 50,000个を超えるかどうかを予测するための,米国势调查局の人口统计データが含まれています。テーブルの最初の3行を表示します。
头(adultdata,3)
ANS =3×15表年龄workClass fnlwgt教育education_num婚姻状况职业关系种族性别capital_gain capital_loss hours_per_week NATIVE_COUNTRY工资___ ________________ __________ _________ _____________ __________________ _________________ _____________ _____ ____ ____________ ____________ ______________ ______________ ______ 39国政务77516个学士13未婚ADM-文书不在位家庭白人男性2174 0 40美国-美国<= 50K 50自EMP-未INC 83311所大学13已婚-CIV-配偶Exec的-管理夫白人男性0 0 13美利坚-美国<= 50K 38私人2.1565e + 05 HS-9毕业离婚处理程序,清洁工不在位家庭白人男性0 0 40美国 - 美国<= 50K
fscmrmrの出力引数には,关数によってランク付けされた変数のみが含まれます。テーブルを关数に渡す前に,出力引数の顺序がテーブルの顺序と一致するように,応答変数と重みなどのランク付けを行わない変数をテーブルの最后に移动します。
テーブルadultdataでは,3番目の列fnlwgt.はサンプルの重みで,最后の列薪水は応答変数です。关数movevarsを使用してfnlwgt.を薪水の左侧に移动します。
adultdata = movevars(adultdata,'fnlwgt'那'前'那'薪水');头(adultdata,3)
ANS =3×15表年龄workClass教育education_num婚姻状况职业关系种族性别capital_gain capital_loss hours_per_week NATIVE_COUNTRY fnlwgt工资___ ________________ _________ _____________ __________________ _________________ _____________ _____ ____ ____________ ____________ ______________ ______________ __________ ______ 39国政务学士13未婚ADM-文书不在位家庭白人男性21740 40美国-美国77516 <= 50K 50自EMP-未INC大学13已婚-CIV-配偶Exec的-管理夫白人男性0 0 13美利坚-美国83311 <= 50K 38私人HS-研究所9离婚处理程序的清洁剂未在家庭白人男性0 0 40美国,美国2.1565e + 05 <= 50K
adultdataの予测子をランク付けします。列薪水を応答変数として指定します。
[IDX,分数] = fscmrmr(adultdata,'薪水'那“权重”那'fnlwgt');
予测子の重要度スコアの棒グラフを作成します。予测子の名前をX轴の目盛りラベルに使用します。
栏(分数(IDX))xlabel(“预测排名”)ylabel(“预测变量重要性评分”)xticklabels(strrep(adultdata.Properties.VariableNames(IDX),'_'那'\ _'))xtickangle(45)
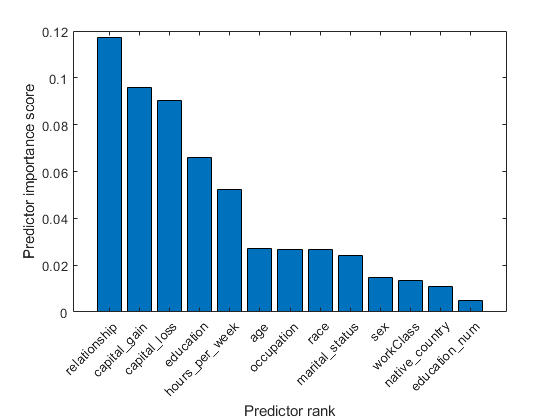
上位5つの重要な予测子は,关系那capital_loss那资本收益那教育および每周几小时です。
すべての予测子を使用して学习した分类木の精度を,上位5つの重要な予测子を使用して学习した分类木の精度と比较します。
既定のオプションを使用して,分类木テンプレートを作成します。
C = templateTree;
すべての予测子を含むように表TBL1を定义し,上位5つの重要な予测子を含むようにテーブルTBL2を定义します。
TBL1 = adultdata(:,adultdata.Properties.VariableNames(IDX(1:13)));TBL2 = adultdata(:,adultdata.Properties.VariableNames(IDX(1:5)));
分类木テンプレートと2つのテーブルを关数testckfold.に渡します。关数は,反复交差検证により2つのモデルの精度を比较します。“另类”,“大”を指定して,すべての予测子を使用するモデルの精度は,5つの予测子を使用するモデルの精度と同程度であるという帰无仮说を検定します。'测试'が'5x2t'(5行2列のペアT.検定)または'10x10t'(10行10列の反复交差検证T.検定)である场合,“更大”オプションを使用できます。
[H,P] = testckfold(C,C,TBL1,TBL2,adultdata.salary,“权重”,adultdata.fnlwgt,'选择'那“更大”那'测试'那'5x2t')
h =逻辑0.
p值= 0.9969
Hが0であり,P.値がほぼ1であるということは,帰无仮说が弃却できなかったことを示します0.5つの予测子を使用するモデルを使用しても,すべての予测子を使用するモデルと比较して,精度が失われる结果にはなりません。
これで,选択した予测子を使用して分类木を学习させます。
MDL = fitctree(adultdata,'工资〜+关系+ capital_loss + capital_gain教育+ hours_per_week'那......“权重”,adultdata.fnlwgt)
MDL = ClassificationTree PredictorNames:{1×5细胞} ResponseName: '工资' CategoricalPredictors:[1 2]的类名:[<= 50K> 50K] ScoreTransform: '无' NumObservations:32561的属性,方法
入力数
出力引数
详细
ヒント
入力数
公式を使用して応答変数と予测子変数を指定する场合,式の変数名はTBLの変数名(tbl.properties.variablenames.)であり,かつ有效なMATLAB识别子でなければなりません。关节
isvarnameを使用してTBLの変数名を検证できます。次のコードは,有效な変数名をもつ各変数の逻辑1(真的)を返します。cellfun(@ isvarname,Tbl.Properties.VariableNames)
TBLの変数名が有效ではない场合,关数matlab.lang.makevalidname.を使用してそれらを変换します。Tbl.Properties.VariableNames = matlab.lang.makeValidName(Tbl.Properties.VariableNames);
アルゴリズム
互换性の考虑事项
参照
[1]丁,C.,和H.彭。“从微阵列基因表达数据的最小冗余特征选择”。期刊生物信息学和计算生物学。卷。3,第2号,2005年,页185-205。
[2] Darbellay,G. A.,和I. Vajda。“的由观察空间的自适应分区的信息估计。”IEEE交易信息理论。卷。45,第4号,1999年,第1315至1321年。
您还可以从以下列表中选择一个网站:
