このページの翻訳は最新ではありません。ここをクリックして,英語の最新版を参照してください。
tsne
t分布型確率的近傍埋め込み
説明
例
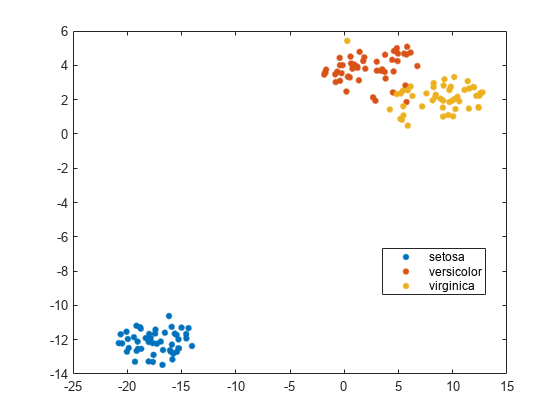
フィッシャーのアヤメのデータの可視化
フィッシャーのアヤメのデータセットには,アヤメの4次元測定値および対応する種への分類が格納されています。tsneを使用して次元を削減することにより,このデータを可視化します。
负载fisheririsrng默认的%的再现性Y = tsne(量);gscatter (Y (: 1), Y(:, 2),物种)
距離計量の比較
各種の距離計量を使用して,フィッシャーのアヤメのデータにおける種の分離をより良好にします。
负载fisheririsrng (“默认”)%的再现性Y = tsne(量,“算法”,“准确”,“距离”,“mahalanobis”);次要情节(2,2,1)gscatter (Y (: 1), Y(:, 2),物种)标题(“Mahalanobis”)提高(“默认”)为了公平比较Y = tsne(量,“算法”,“准确”,“距离”,的余弦);次要情节(2 2 2)gscatter (Y (: 1), Y(:, 2),物种)标题(的余弦)提高(“默认”)为了公平比较Y = tsne(量,“算法”,“准确”,“距离”,“chebychev”);次要情节(2,2,3)gscatter (Y (: 1), Y(:, 2),物种)标题(“Chebychev”)提高(“默认”)为了公平比较Y = tsne(量,“算法”,“准确”,“距离”,“欧几里得”);次要情节(2,2,4)gscatter (Y (: 1), Y(:, 2),物种)标题(“欧几里得”)
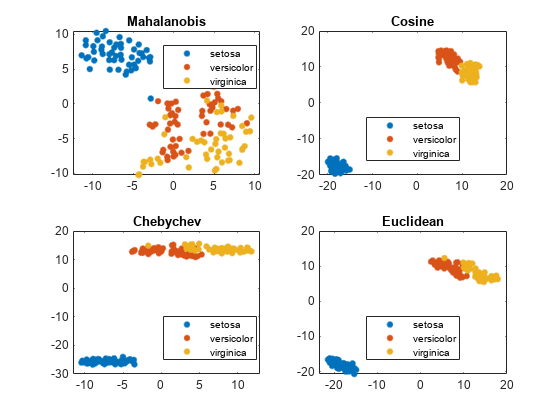
この場合,コサイン,チェビシェフおよびユークリッド距離計量でクラスターが適切に分離されています。しかし,マハラノビス距離計量では適切に分離されません。
南入力データと結果のプロット
tsneは,南エントリが含まれている入力データ行を削除します。したがって,プロットを行う前に,このような行を分類データから削除しなければなりません。
たとえば,フィッシャーのアヤメのデータでいくつかのランダムなエントリを南に変更します。
负载fisheririsrng默认的%的再现性meas(rand(size(meas)) < 0.05) = NaN;
tsneを使用して4次元データを2次元に埋め込みます。
Y = tsne(量,“算法”,“准确”);
警告:在X或'InitialY'值中NaN缺失值的行将被删除。
埋め込みから除去された行数を調べます。
长度(物种)长度(Y)
ans = 22
南値が含まれていない量の行を特定することにより,結果のプロットを準備します。
goodrows =没有(任何(isnan(量),2));
南値が含まれていない量の行に対応する物种の行のみを使用して,結果をプロットします。
gscatter (Y (: 1), Y(:, 2),物种(goodrows))

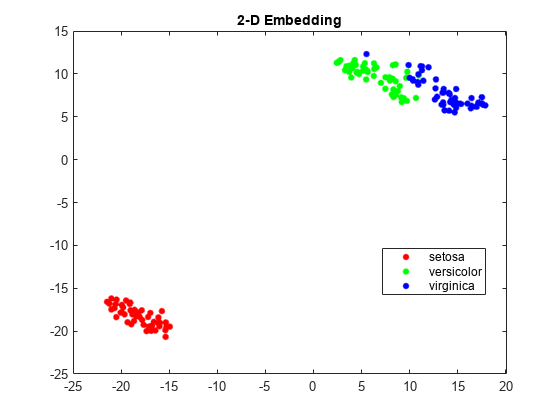
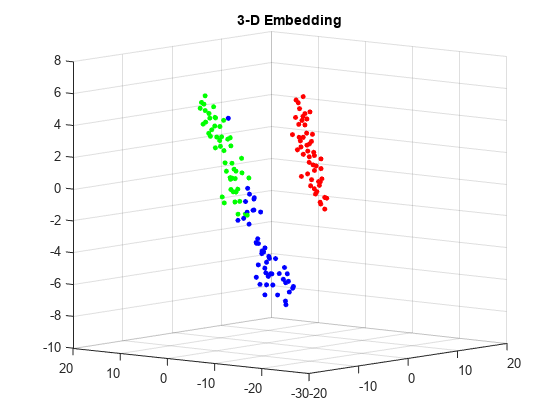
t-SNEの損失の比較
フィッシャーのアヤメのデータについて2次元と3次元の両方の埋め込みを求め,各埋め込みの損失を比較します。3次元の埋め込みの方が,元のデータに一致する自由度が大きいので,損失が小さくなると考えられます。
负载fisheririsrng默认的%的再现性(Y,亏损)= tsne(量,“算法”,“准确”);rng默认的为了公平比较(Y2, loss2) = tsne(量,“算法”,“准确”,“NumDimensions”3);流('2-D嵌入损失%g, 3-D嵌入损失%g.\n'、损失、loss2)
二维嵌入损失0.124191,三维嵌入损失0.0990884。
予想どおり3次元の埋め込みの方が損失が小さくなっています。
埋め込みを表示します。RGBカラー(1 0 0)、(0 1 0)および(0 0 1)を使用します。
3次元プロットに分类コマンドを使用して種を数値に変換してから,次のように関数稀疏的を使用して数値をRGBカラーに変換します。vが正の整数1、2または3から成るベクトルで種のデータに対応する場合,以下のコマンド
稀疏(1:元素个数(v), v, 1(大小(v)))
は,行が種のRGBカラーであるスパース行列になります。
gscatter (Y (: 1), Y(:, 2),物种,眼(3))标题(“二维嵌入”)
图v =双(属(种));c =全(稀疏(1:元素个数(v), v,(大小(v))的元素个数(v), 3));scatter3 (Y2 (:, 1), Y2 (:, 2), Y2(:, 3), 15日,c,“填充”)标题(“3 d嵌入”)视图(-50 8)
入力引数
出力引数
詳細
アルゴリズム
tsneは,相対的な類似度が元の高次元点の類似度に似ている一連の埋め込み点を低次元空間内に構築します。埋め込み点は,元のデータのクラスタリングを示します。
大まかに説明すると,このアルゴリズムは,元の点がガウス分布に由来し,埋め込み点がスチューデントのt分布に由来するとしてそれぞれをモデル化します。そして,埋め込み点を移動することにより,これらの2つの分布の間におけるカルバック・ライブラーダイバージェンスを最小化しようとします。
詳細は,t-SNEを参照してください。
参考
你也可以从以下列表中选择一个网站:
