このページの翻訳は最新ではありません。ここをクリックして,英語の最新版を参照してください。
适合
曲線または曲面によるデータへの近似
構文
説明
例
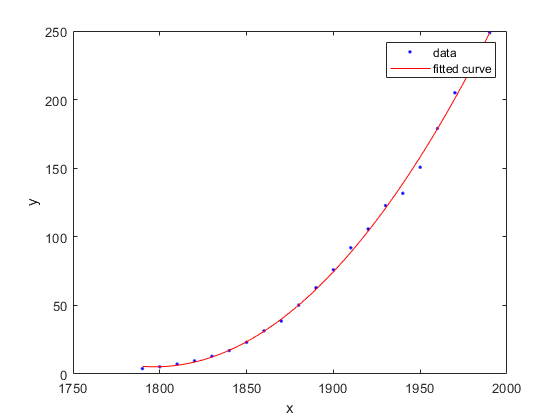
2次曲線による近似
データを読み込み2次曲線を使って変数cdateおよび流行に当てはめ,当てはめとデータをプロットします。
负载统计; f=配合(cdate、pop、,“poly2”)
系数(有95%置信限):p1 = 0.006541 (0.006124, 0.006958) p2 = -23.51 (-25.09, -21.93) p3 = 2.113e+04 (1.964e+04, 2.262 2e+04)
情节(f cdate流行)
ライブラリ モデル名の一覧については、fitTypeを参照してください。
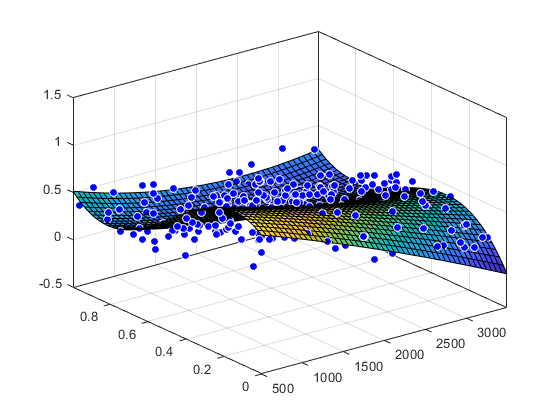
多項式曲面による近似
データを読み込み,xについて2次,Yについて3次の多項式曲面で近似します。近似とデータをプロットします。
负载因特网科幻小说=适合(x, y, z,“poly23”)
线性模型Poly23: sf(x,y) = p00 + p10*x + p01*y + p20*x^2 + p11*x*y + p02*y^2 + p21*x^2*y + p12*x*y^2 + p03*y^3P00 = 1.118 (0.9149, 1.321) p10 = -0.0002941 (-0.000502, -8.623e-05) p01 = 1.533 (0.7032, 2.364) p20 = -1.966e-08 (-0.0001009, - 0.0007863) p11 = 0.0003427 (-0.0001009, - 0.0007863) p02 = -6.951 (-8.421, -5.481) p21 = 9.563e-08 (-0.0007082, -0.0001721) p12 = -0.0004401 (-0.0007082, -0.0001721) p03 = 4.999 (4.082, 5.917)
绘图(sf,[x,y],z)
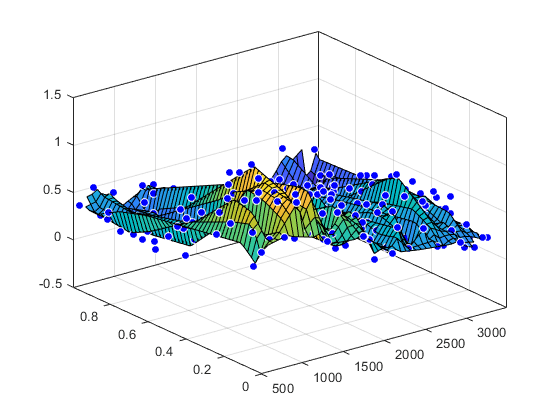
MATLABテーブル内の変数を使用した曲面近似
因特网データを読み込み,MATLAB®テーブルに変換します。
负载因特网T=表(x,y,z);
テーブル内の変数を関数适合への入力として指定し、近似をプロットします。
f = ((T。x,T.y],T.z,“线性ERP”);情节(f, [T。x,T.y], T.z )
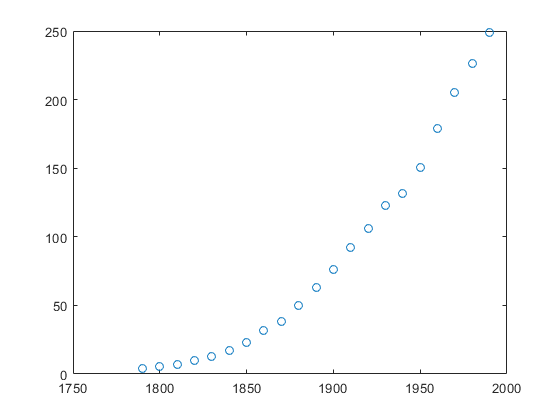
近似前の近似オプションと近似タイプの作成
データを読み込んでプロットし,関数fittypeおよびfitoptionsを使用して近似オプションと近似タイプを作成してから,近似を作成してプロットします。
census.matのデータを読み込んでプロットします。
负载统计情节(cdate、流行,“o”)
カスタム非線形モデル について近似オプションオブジェクトと近似タイプを作成します。ここで,A.とBは係数,Nは問題依存のパラメーターです。
fo=fit选项(“方法”,“非线性最小二乘法”,...“低”(0, 0),...“上”(正无穷,max (cdate)),...曾经繁荣的[1]);英国《金融时报》= fittype (“*(取向)^ n”,“问题”,“n”,“选项”fo);
近似オプションとN= 2 の値を使用して、データに当てはめます。
[curve2, gof2] =适合(cdate、流行、英国《金融时报》,“问题”, 2)
系数(95%置信限):a = 0.006092 (0.005743, 0.006441) b = 1789(1784,1793)问题参数:n = 2
gof2=结构体字段:Sse: 246.1543 rsquare: 0.9980 dfe: 19 adjrsquare: 0.9979 rmse: 3.5994
近似オプションとN= 3 の値を使用して、データに当てはめます。
[curve3,gof3]=拟合(cdate,pop,ft,“问题”3)
曲线3=一般模型:曲线3(x)=a*(x-b)^n系数(具有95%置信限):a=1.359e-05(1.245e-05,1.474e-05)b=1725(17181731)问题参数:n=3
gof3=结构体字段:adrsquare: 0.9980 rmse: 3.4944
近似結果をデータと共にプロットします。
持有在情节(curve2“米”)绘图(曲线3,“c”)传说(“数据”,“n = 2”,“n = 3”)举行从
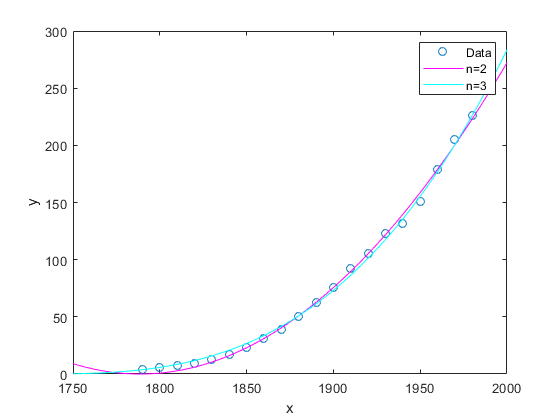
正規化とロバストオプションを指定した3次多項式による近似
データを読み込み、データのセンタリングとスケーリング (正常化)およびロバスト近似オプションを指定して3次多項式で近似し,プロットします。
负载统计; f=配合(cdate、pop、,“poly3”,“正常化”,“开”,“稳健”,“Bisquare”)
系数(95%置信限):p1 = -0.4619 (-1.895, 0.9707) p2 = 25.01 (23.79, 26.22) p3 = 77.03 (74.37, 79.7) p4 = 62.81 (61.26, 64.37)
情节(f cdate流行)
ファイルで定義された曲線による近似
ファイルに関数を定義し,それを使用して近似タイプを作成し曲線で近似します。
関数を MATLAB®ファイルに定義します。
函数y = piecewiseLine (x, a, b, c, d, k)%分段直线由两段组成的直线那不是连续的。y = 0(大小(x));这个例子包括一个for循环和if语句%纯粹为了举例的目的。对于i = 1:长度(x)如果X (i) < k, y(i) = a + b.* X (i);其他的Y (i) = c + d. x(i);终止终止终止
ファイルを保存します。
データを定義し,関数piecewiseLineを指定して近似タイプを作成します。その近似タイプ英尺を使用して近似を作成し,結果をプロットします。
x = [0.81; 0.91; 0.13; 0.91; 0.63; 0.098; 0.28; 0.55;...0.96; 0.96; 0.16; 0.97; 0.96);y = [0.17; 0.12; 0.16; 0.0035; 0.37; 0.082; 0.34; 0.56;...0.15; -0.046; 0.17; -0.091; -0.071);英国《金融时报》= fittype ('piecewiseLine(x, a, b, c, d, k)') f = fit(x, y, ft,)曾经繁荣的, [1, 0, 1, 0, 0.5])
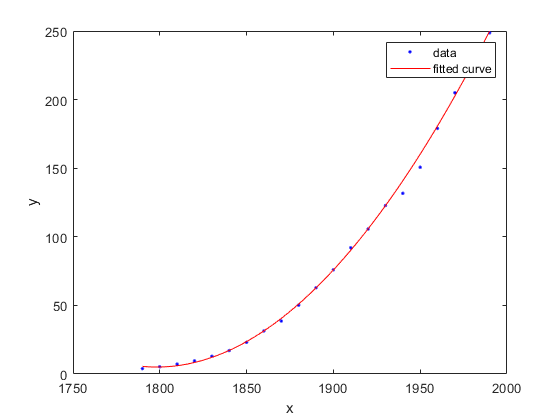
近似からの点の排除
データを読み込み、排除する点を指定してカスタム式で近似します。結果をプロットします。
データを読み込み,カスタム式と開始点を定義します。
[x, y] =钛;gaussEqn =‘a*exp(-(x-b)/c)^2)+d’
gaussEqn = ' * exp(((取向)/ c) ^ 2) + d '
startPoints = [1.5 900 10 0.6]
曾经繁荣=1×41.5000 900.0000 10.0000 0.6000
カスタム式と開始点を使用して2つの近似を作成します。インデックスベクトルと式を使用して2 組の異なる排除点を定義します。排除を使用して近似から外れ値を削除します。
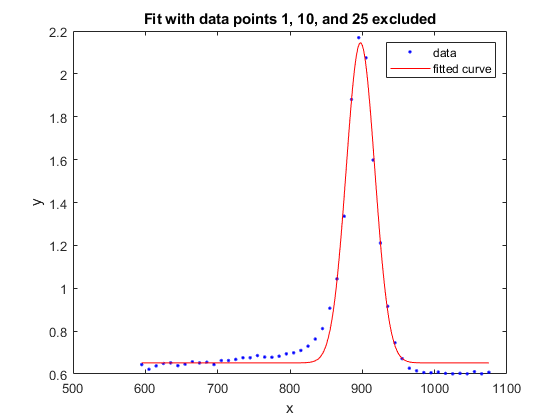
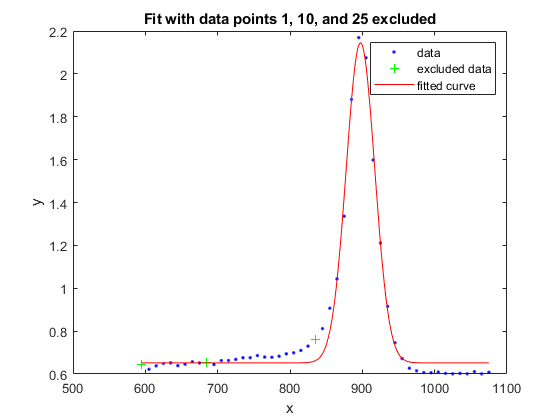
f1 =适合(x, y, gaussEqn,“开始”曾经繁荣,“排除”, [1 10 25])
系数(95%置信限):a = 1.493 (1.432, 1.554) b = 897.4 (896.5, 898.3) c = 27.9 (26.55, 29.25) d = 0.6519 (0.6367, 0.6672)
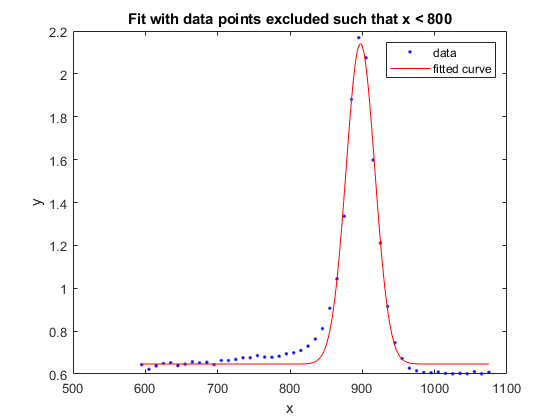
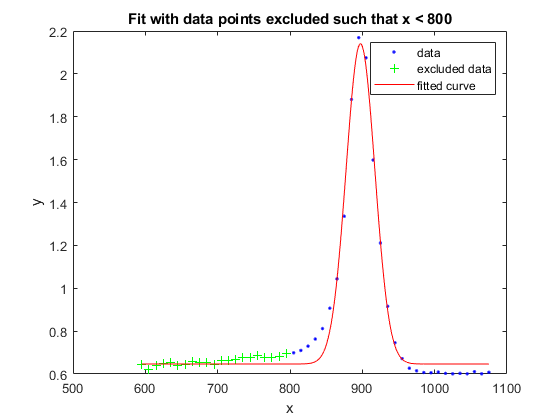
f2 =适合(x, y, gaussEqn,“开始”曾经繁荣,“排除”, x < 800)
f2=一般模型:f2(x)=a*exp(-(x-b)/c^2)+d系数(具有95%置信限):a=1.494(1.41,1.578)b=897.4(896.2898.7)c=28.15(26.22,30.09)d=0.6466(0.6169,0.6764)
両方の近似をプロットします。
情节(f1, x, y)标题('拟合数据点1,10和25排除')
图表(f2,x,y)标题('与排除的数据点进行拟合,使x<800')
点の排除と排除したデータを示す近似のプロット
排除する点を関数符合への入力として指定する前に,それらの点を変数として定義できます。以下の手順では,前述の例の近似を再作成し,排除した点をデータと近似と共にプロットします。
データを読み込み,カスタム式と開始点を定義します。
[x, y] =钛;gaussEqn =‘a*exp(-(x-b)/c)^2)+d’
gaussEqn = ' * exp(((取向)/ c) ^ 2) + d '
startPoints = [1.5 900 10 0.6]
曾经繁荣=1×41.5000 900.0000 10.0000 0.6000
インデックス ベクトルと式を使用して、排除する 2.組の点を定義します。
排除1=[11025];排除2=x<800;
カスタム式,開始点および2組の異なる排除点を使用して2つの近似を作成します。
f1 =适合(x, y, gaussEqn,“开始”曾经繁荣,“排除”,不包括1);f2=配合(x',y',n,“开始”曾经繁荣,“排除”, exclude2);
両方の近似をプロットし,排除したデータを強調表示します。
情节(f1, x, y, exclude1)标题('拟合数据点1,10和25排除')
图;绘图(f2,x,y,不包括2)标题('与排除的数据点进行拟合,使x<800')
排除点を使用する曲面近似の例として、曲面データを読み込み、排除するデータを指定して近似を作成しプロットします。
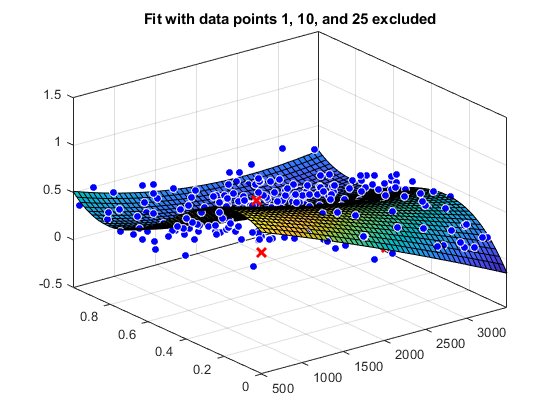
负载因特网= [x y],z,“poly23”,“排除”, [1 10 25]);f = [x y],z,“poly23”,“排除”,z>1);图形图(f1,[x y],z,“排除”, [1 10 25]);标题('拟合数据点1,10和25排除')
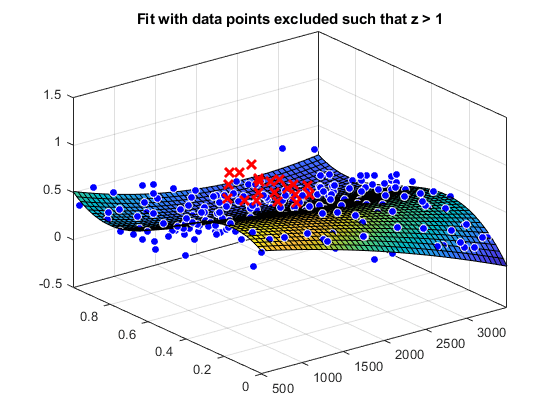
图(f2, [x y], z,“排除”, z > 1);标题('拟合排除的数据点z > 1')
平滑化スプライン曲線による近似と適合度情報の取得
データを読み込み,変数月および压力を使用して平滑化スプライン曲線で近似し,適合度情報と出力構造体を返します。データに対する近似と残差をプロットします。
负载恩索;[曲线,良度,产量]=适合(月,压力,“smoothingspline”);绘图(曲线、月份、压力);xlabel(“月”);ylabel (“压力”);
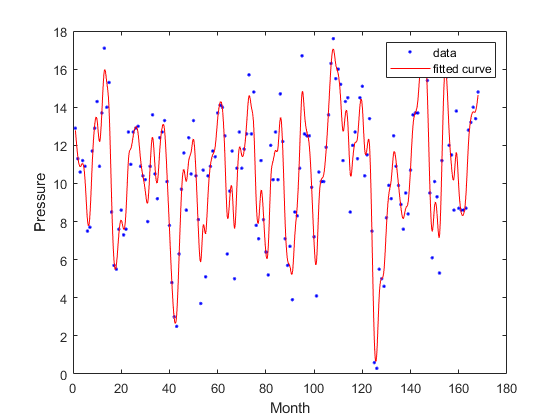
xデータ(月)に対する残差をプロットします。
绘图(曲线、月份、压力、,“残差”)包含(“月”) ylabel (“残差”)
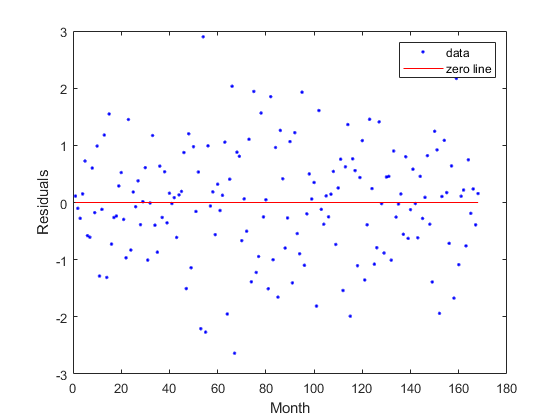
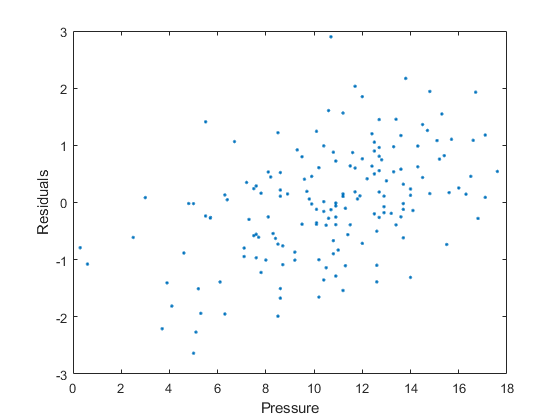
输出構造体のデータを使用して,yデータ(压力)に対する残差をプロットします。
情节(压力、output.residuals、'.')包含(“压力”) ylabel (“残差”)
単項指数関数による近似
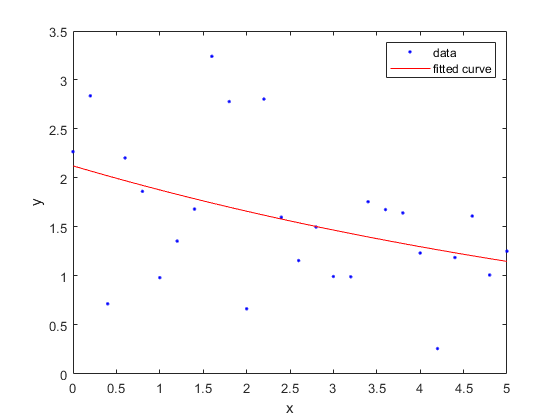
指数関数的トレンドのデータを生成し、指数モデルの曲線近似ライブラリにある最初の方程式 (単項指数関数) を使用してそのデータに当てはめます。結果をプロットします。
x =(0:0.2:5)”;Y = 2*exp(-0.2*x) + 0.5*randn(size(x))); / /f =适合(x, y,“exp1”);绘图(f、x、y)
無名関数を使用したカスタムモデルによる近似
無名関数を使用すると、他のデータを関数适合に簡単に渡せます。
データを読み込み,無名関数を定義する前にEmaxを1.に設定します。
数据= importdata (“OpioidHypnoticSynergy.txt”);异丙酚= data.data (: 1);Remifentanil = data.data (:, 2);痛觉计= data.data (: 3);Emax = 1;
モデル方程式を無名関数として定義します。
效果= @(IC50A, IC50B, alpha, n, x, y)...Emax*(x/IC50A+y/IC50B+alpha*(x/IC50A)....*(y/IC50B))。^n./(x/IC50A+y/IC50B+...α*(x/IC50A)。*(y/IC50B))。^n+1);
無名関数效果を関数适合への入力として使用し,結果をプロットします。
AlgometryEffect=fit([异丙酚,瑞芬太尼]),算法测定,效果,...曾经繁荣的, [2, 10, 1,0.8],...“低”, [-Inf, -Inf, -Inf],...“稳健”,“拉尔”)图(算法效应,[异丙酚,瑞芬太尼],算法测定)
無名関数の使用例と他の近似用カスタム モデルの詳細については、関数fittypeを参照してください。
開始点と範囲を設定するための係数順序の確認
プロパティ上面的、较低的、曾经繁荣については,係数のエントリ順序を確認する必要があります。
近似タイプを作成します。
英国《金融时报》= fittype (" b * x ^ 2 + c * x +一个“);
関数coeffnamesを使用して係数名と順序を取得します。
系数名称(英尺)
ans=3 x1细胞{a} {b} {' c '}
これは,fittypeを使用して英尺を作成するときに使用する式の係数の順序とは異なることに注意してください。
データを読み込み,近似を作成し,開始点を設定します。
负载恩索配合(月份、压力、英尺、,曾经繁荣的, 1、3、5)
系数(95%置信限):a = 10.94 (9.362, 12.52) b = 0.0001677 (-7.985e-05, 0.0004153) c = -0.0224 (-0.06559, 0.02079)
これにより、一个= 1、b=3、c = 5のように,係数に初期値が代入されます。
または,近似オプションを取得し,開始点と下限を設定してから,新しいオプションを使用して再近似することもできます。
选择= fitoptions(英尺)
选项=规格化:“关闭”排除:[]权重:[]方法:“非线性最小二乘”稳健:“关闭”起始点:[1x0双精度]下:[1x0双精度]上:[1x0双精度]算法:“信赖域”DiffMinChange:1.0000e-08 DiffMaxChange:0.1000显示:“通知”MaxFunEvals:600 MaxIter:400 TolFun:1.0000e-06 TolX:1.0000e-06
选项。StartPoint = [10 1 3];选项。较低的=[0 -Inf 0]; fit(month,pressure,ft,options)
a = 10.23 (9.448, 11.01) b = 4.335e-05 (-1.82e-05, 0.0001049) c = 5.523e-12(固定在边界)
入力引数
出力引数
参考
アプリ
関数
你也可以从以下列表中选择一个网站:
