强化学习工具箱
強化学習を用いた方策の設計および学習
强化学习工具箱™には,DQNやPPO,囊,DDPGなどの強化学習アルゴリズムを使用して方策を学習させるためのアプリや関数,仿真软件万博1manbetx®ブロックが用意されています。これらの方策を使用して,リソース割り当てやロボティクス,自律システムなどの複雑な用途向けにコントローラーと意思決定アルゴリズムを実装できます。
このツールボックスでは,ディープニューラルネットワークやルックアップテーブルを使用して,方策や価値関数を表現し,MATLAB®や仿万博1manbetx真软件でモデル化された環境との交互作用を通じてそれらを学習させることができます。ツールボックスに含まれるシングルエージェントまたはマルチエージェントの強化学習アルゴリズムを評価したり,独自に開発を行ったりできます。また,ハイパーパラメーター設定の実験や,学習の進行状況の監視が可能であるほか,学習済みエージェントをアプリから対話的にまたはプログラム上でシミュレーションできます。学習の性能を向上させるには,シミュレーションを複数のCPU、GPU,コンピュータークラスター,およびクラウドで並列実行します(并行计算工具箱™およびMATLAB并行服务器™を使用)。
既存の方策は,ONNX™モデル形式を使用して,TensorFlow™KerasやPyTorchなどのディープラーニングフレームワークからインポートできます(深度学习工具箱™を使用)。最適化されたC, c++,およびCUDA®コードを生成し,学習済みの方策をマイクロコントローラーやGPUに展開できます。このツールボックスには,初めての方にも使いやすい参照例が付属しています。
詳細を見る:


強化学習アルゴリズム
深Q-Network (DQN),深層決定論的方策勾配法(DDPG),近傍方策最適化(PPO)などの組み込みアルゴリズムを使用して,エージェントを作成します。テンプレートを使用して,方策の学習のためのカスタムエージェントを開発します。

强化学习工具箱で使用できる学習アルゴリズム。
強化学習デザイナーアプリ
強化学習エージェントの設計,学習,シミュレーションを対話的に行います。後で使用したり展開できるように,学習済みのエージェントをMATLABにエクスポートします。
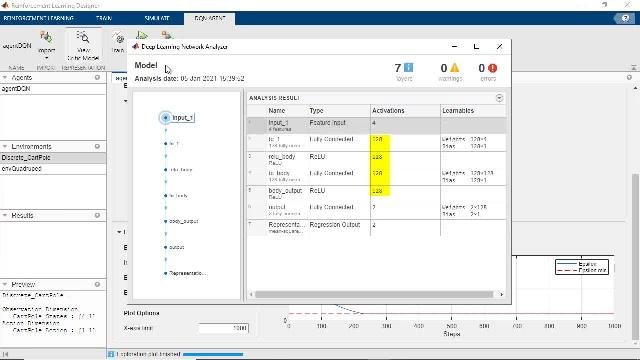
ディープニューラルネットワークによる方策と価値関数の表現
大きな状態行動空間を持つ複雑なシステムでは,ディープニューラルネットワークの方策をプログラムで定義します。この場合,深度学习工具箱の層を使用するか,ディープネットワークデザイナーを使用して対話的に定義します。または,このツールボックスで提案される既定のネットワークアーキテクチャを使用します。模倣学習を使用して方策を初期化し,学習を高速化します。他のディープラーニングフレームワークとの相互運用のためにONNXモデルのインポートおよびエクスポートを行います。

万博1manbetx仿真软件によるシングルエージェントおよびマルチエージェントの強化学習
万博1manbetx仿真软件でRL代理ブロックを使用して,強化学習エージェントの作成と学習を行います。万博1manbetx仿真软件でRL代理ブロックの複数のインスタンスを使用して,複数のエージェントの学習を同時に行います(マルチエージェントの強化学習)。

万博1manbetx模型用の強化学習エージェントブロック。
万博1manbetx仿真软件およびSimscape環境
万博1manbetx仿真软件およびSimscape™を使用して,環境のモデルを作成します。モデル内で観測信号,行動信号,報酬信号を指定します。

二足歩行ロボットのための仿万博1manbetx真软件環境モデル。
MATLAB環境
MATLABの関数やクラスを使用して,環境をモデル化します。MATLABファイル内で、観測変数、行動変数、報酬変数を指定します。

3自由度のロケット向けMATLAB環境。
分散コンピューティングおよびマルチコアによる高速化
学習を高速化するために,并行计算工具箱やMATLAB并行服务器を使用して,マルチコアコンピューター,クラウドリソース,または計算クラスター上で並列シミュレーションを実行します。

並列計算を使用して,学習を高速化。

GPUを使用した学習の高速化。
コード生成
学習済みの方策を表現するMATLABコードから最適化されたCUDAコードを生成するにはGPU编码器™を使用します。方策を展開するためのC / c++コードの生成にはMATLAB编码器™を使用します。

GPU编码器を使用したCUDAコードの生成。
MATLAB编译器のサポート
MATLAB编译器™やMATLAB编译器SDK™を使用して,学習済みの方策をスタンドアロンのアプリケーション,C / c++共有ライブラリ,微软®netアセンブリ,Java®クラス,Python®パッケージとして展開します。

方策をスタンドアロンのプログラムとしてパッケージ化して共有。
入門
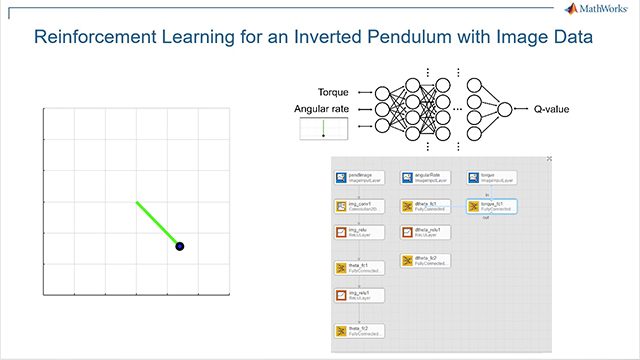
単純な振子の倒立,グリッドワールドのナビゲート,カートポールシステムのバランス制御,一般的なマルコフ決定過程の求解などの問題に対する強化学習方策の開発方法をご覧ください。
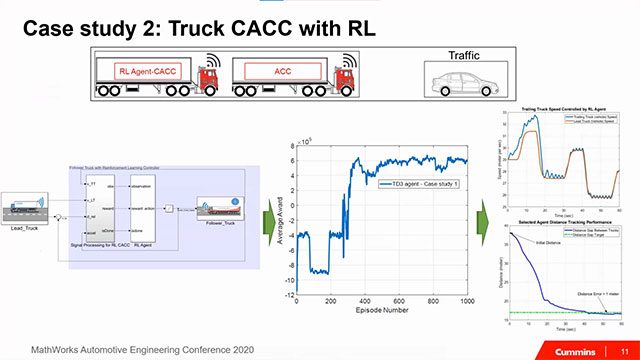
自動運転
車間距離制御装置,車線逸脱防止支援,自動駐車などの自動運転用途のための強化学習方策を設計します。
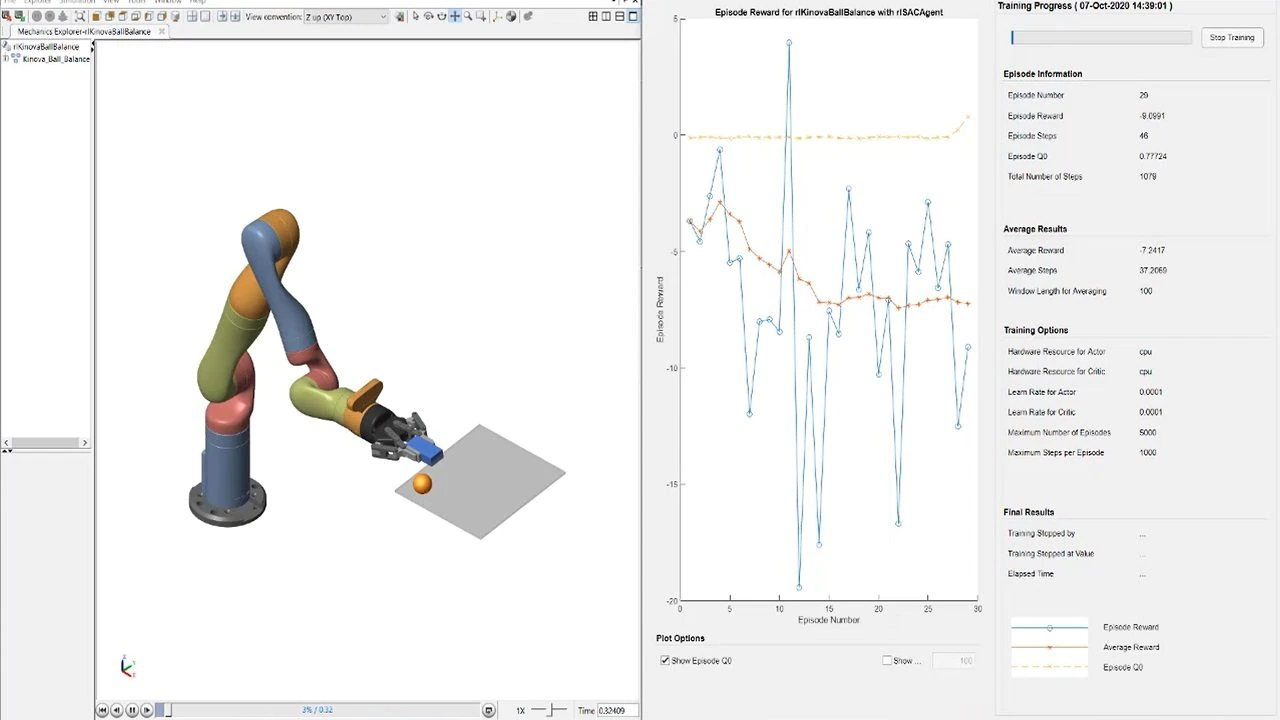
調整,キャリブレーション,およびスケジューリング
調整,キャリブレーション,およびスケジューリングの用途向けに強化学習方策を設計します。

配水のリソース割り当ての問題。
製品リソース:

強化学習ビデオシリーズ
このビデオシリーズを見て,強化学習について学習しましょう。