模拟
模拟回归系数和贝叶斯线性回归模型的扰动方差
句法
描述
[还从潜势分布中抽取若BetaSim,sigma2Sim,RegimeSim)=模拟(___)MDL是贝叶斯线性回归模型随机搜索变量选择(SS VS移至),即,如果MDL是一个mixconjugateblm要么mixsemiconjugateblm模型对象。
例子
模拟先验分布和后验分布的参数值
考虑多元线性回归模型,预测美国的实际国内生产总值(GNPR)通过使用工业生产指数的线性组合(IPI),总就业(Ë)和实际工资(WR)。
对所有 , 是具有0和方差的平均一系列独立的高斯干扰的 。
假设这些先验分布:
。 是的手段一个4×1向量,以及 是一个4×4正定协方差矩阵。
。 和 是一个逆伽马分布的形状和规模,分别。
这些假设和数据似然性暗示的正逆伽马共轭模型。
加载纳尔逊 - 普洛瑟数据集。创建响应和预测序列变量。
加载Data_NelsonPlosservarNames = {'IPI''E''WR'};X = {数据表:,varNames};Y = {数据表:,“GNPR”};
创建用于线性回归参数的正逆伽马共轭先验模型。指定预测器的数量p和变量名。
P = 3;PriorMdl = bayeslm(P,'ModelType',“共轭”,'VarNames',varNames);
PriorMdl是一个conjugateblm表示回归系数和干扰方差的先验分布贝叶斯线性回归模型对象。
模拟的一组回归系数和来自先验分布的扰动方差的值。
RNG(1);%用于重现[betaSimPrior,sigma2SimPrior] =模拟(PriorMdl)
betaSimPrior =4×1-33.5917 -49.1445 -37.4492 -25.3632
sigma2SimPrior = 0.1962
betaSimPrior在随机抽取的对应于名称4×1向量回归系数的PriorMdl.VarNames。该sigma2SimPrior输出是随机抽取的标量方差的干扰。
估计后验分布。
PosteriorMdl =估计(PriorMdl,X,Y);
方法:分析后验分布若干意见:62数量预测的:4登录边缘似然:-259.348 |均值标准CI95正分布-----------------------------------------------------------------------------------拦截|-24.2494 8.7821 [-41.514,-6.985]0.003吨(-24.25,8.65 ^ 2,68)IPI |4.3913 0.1414 [4.113,4.669]1.000吨(4.39,0.14 ^ 2,68)E |0.0011 0.0003 [0.000,0.002]1.000吨(0.00,0.00 ^ 2,68)WR |2.4683 0.3490 [1.782,3.154]1.000吨(2.47,0.34 ^ 2,68)西格玛-2 |44.1347 7.8020 [31.427,61.855] 1.000 IG(34.00,0.00069)
PosteriorMdl是一个conjugateblm表示回归系数和干扰方差的后验分布的贝叶斯线性回归模型对象。
模拟的一组回归系数和从后验分布的扰动方差的值。
[betaSimPost, sigma2SimPost] =模拟(PosteriorMdl)
betaSimPost =4×1-25.9351 4.4379 0.0012 2.4072
sigma2SimPost = 41.9575
betaSimPost和sigma2SimPost具有相同的尺寸betaSimPrior和sigma2SimPrior分别但从后绘制。
实施吉布斯采样器验后估计
考虑回归模型模拟先验分布和后验分布的参数值。
加载的数据,并创建用于回归系数和干扰方差的缀合物先验模型。然后,估计后验分布,并返回估计汇总表。
加载Data_NelsonPlosservarNames = {'IPI''E''WR'};X = {数据表:,varNames};Y = {数据表:,“GNPR”};P = 3;PriorMdl = bayeslm(P,'ModelType',“共轭”,'VarNames',varNames);[PosteriorMdl,总结]=估计(PriorMdl, X, y);
方法:分析后验分布若干意见:62数量预测的:4登录边缘似然:-259.348 |均值标准CI95正分布-----------------------------------------------------------------------------------拦截|-24.2494 8.7821 [-41.514,-6.985]0.003吨(-24.25,8.65 ^ 2,68)IPI |4.3913 0.1414 [4.113,4.669]1.000吨(4.39,0.14 ^ 2,68)E |0.0011 0.0003 [0.000,0.002]1.000吨(0.00,0.00 ^ 2,68)WR |2.4683 0.3490 [1.782,3.154]1.000吨(2.47,0.34 ^ 2,68)西格玛-2 |44.1347 7.8020 [31.427,61.855] 1.000 IG(34.00,0.00069)
摘要是一个包含统计数据的表吗估计显示在命令行。
虽然边缘和条件后验分布 和 都是易分析处理的,这个例子着重于如何实现吉布斯采样器,以再现已知的结果。
再次估计模型,但要使用吉布斯采样器。交替从参数的条件后验分布中采样。采样10,000次并为预分配创建变量。从有条件的后验开始采样 特定 。
米= 1E4;BetaDraws =零(P + 1,M);sigma2Draws =零(1,M + 1);sigma2Draws(1)= 2;RNG(1);%用于重现对于j = 1:m BetaDraws(:,j) =模拟(PriorMdl,X,y,“Sigma2”sigma2Draws (j));[~, sigma2draw (j + 1)] =模拟(PriorMdl,X,y,“β”BetaDraws (:, j));结束sigma2Draws = sigma2Draws(2:结束);%取下MCMC样品初始值
该参数的图形痕迹地块。
图;对于j = 1:(p + 1);次要情节(2,2,j);情节(BetaDraws (j,:)) ylabel (“MCMC绘制”)xlabel(“模拟指数”)标题(sprintf ('Trace Plot - %s',PriorMdl.VarNames {Ĵ}));结束
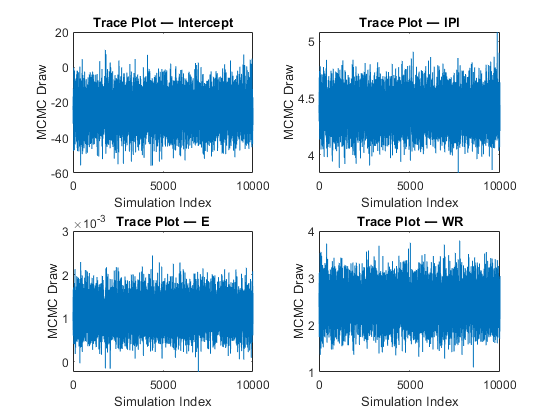
图;情节(sigma2Draws) ylabel (“MCMC绘制”)xlabel(“模拟指数”)标题(“Trace plot - Sigma2”)
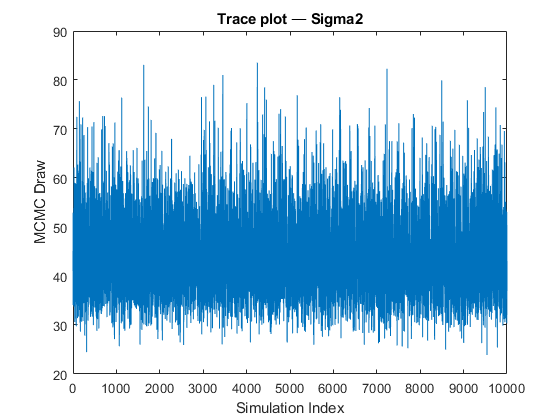
马尔可夫链蒙特卡罗(MCMC)样本具有较好的收敛性和混合性能。
应用1000个绘制的老化周期,然后计算MCMC样本的平均值和标准差。将它们与估算值进行比较估计。
BP = 1000;postBetaMean =平均(BetaDraws(:,(BP + 1):结束),2);postSigma2Mean =平均(sigma2Draws(:,(BP + 1):结束));postBetaStd = STD(BetaDraws(:,(BP + 1):结束),[],2);postSigma2Std = STD(sigma2Draws((BP + 1):结束));[摘要(:,1:2),表([postBetaMean; postSigma2Mean]...[postBetaStd;postSigma2Std),'VariableNames'{“GibbsMean”,“GibbsStd”})]
ANS =5×4表标准的标准的三进路是标准的三进路是标准的三进路是标准的三进路是标准的三进路是标准的三进路是标准的三进路是标准的三进路是标准的三进路是标准的三进路是标准的三进路是标准的三进路是标准的三进路是标准的三进路是标准的三进路是标准的三进路是标准的三进路是标准的三进路是标准的三进路是标准的三进路是标准的三进路是标准的三进路是标准的三进路是标准的三进路是标准的三进路
这些估计都非常接近。MCMC变化占的差异。
从的SSVs预测值选择模拟政权
考虑回归模型模拟先验分布和后验分布的参数值。
假定这些先验分布 = 0,…,3:
,其中 和 是独立的标准正态随机变量。因此,系数呈高斯混合分布。假设所有系数都是先验的条件独立的,但它们依赖于扰动方差。
。 和 是一个逆伽马分布的形状和规模,分别。
它表示具有离散均匀分布随机变量模型 - 包裹体状态变量。
创建执行的SSVs采用现有的模型。假使,假设
和
是相关的(共轭混合模型)。指定预测器的数量p以及回归系数的名称。
P = 3;PriorMdl = mixconjugateblm(P,'VarNames'[“他们”“E”“WR”]);
加载纳尔逊 - 普洛瑟数据集。创建响应和预测序列变量。
加载Data_NelsonPlosserX = {数据表:,PriorMdl.VarNames(2:结束)};Y = {数据表:,“GNPR”};
计算可能的状态数,即模型中包含和排除变量所产生的组合数。
cardRegime = 2 ^(PriorMdl.Intercept + PriorMdl.NumPredictors)
cardRegime = 16
从后验分布模拟万个政权。
RNG(1);[〜,〜,RegimeSim] =模拟(PriorMdl,X,Y,'NumDraws',10000);
RegimeSim是一个4×1000个逻辑矩阵。行对应的变量Mdl.VarNames和列对应于从后验分布绘制。
绘制走访制度的柱状图。重新编码制度,使它们可读。具体而言,对于每个制度,创建一个字符串,它识别在模型中的变量,并用点分开的变量。
cRegime = num2cell(RegimeSim,1);cRegime =分类(cellfun(@(c)中加入(PriorMdl.VarNames(c)中,“”),cRegime));cRegime(ISMISSING(cRegime))=“NoCoefficients”;直方图(cRegime);标题(“变量包括在模型”)ylabel(“频率”);
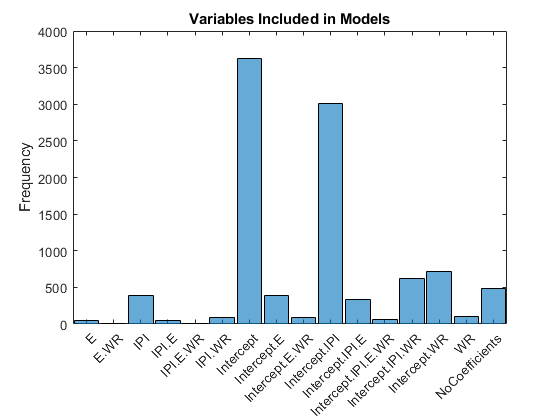
计算变量夹杂物的边缘后验概率。
表(平均值(RegimeSim,2),“RowNames”PriorMdl.VarNames,...'VariableNames',“政权”)
ANS =4×1表制度______拦截0.8829 IPI 0.4547Ë0.098 WR 0.1692
使用吉布斯采样器的稳健回归
考虑包含一个预测贝叶斯线性回归模型,和一个Ť分布扰动方差具有一个轮廓的自由度参数 。
。
这些假设意味着:
是潜在标度参数的一个向量,它将较低的精度归因于远离回归线的观测值。 超参数控制的影响 在观察。
对于这个问题,Gibbs sampler非常适合估计系数,因为您可以模拟贝叶斯线性回归模型的参数 ,然后模拟 从它的条件分布。
生成 的回应 哪里 和 。
RNG('默认');N = 100;X = linspace(0,2,N)';B0 = 1;B1 = 2;西格玛= 0.5;E = randn(N,1);Y = B0 + B1 * X +西格玛* E;
通过膨胀下面的所有响应来引入外围响应 通过3倍。
Y(X <0.25)= Y(X <0.25)* 3;
适合于该数据的线性模型。图中的数据和拟合回归直线。
MDL = fitlm(X,Y)
MDL =线性回归模型为:y〜1个+ X1估计系数:估计SE TSTAT p值________ _______ ______ __________(截距)2.6814 0.28433 9.4304 2.0859e-15 X1观察0.78974 0.24562 3.2153 0.0017653号:100,错误自由度:98根均方误差:1.43 R平方:0.0954,调整R平方:0.0862 F统计与常数模型:10.3,p值= 0.00177
图;情节(Mdl);hl =传奇;持有上;
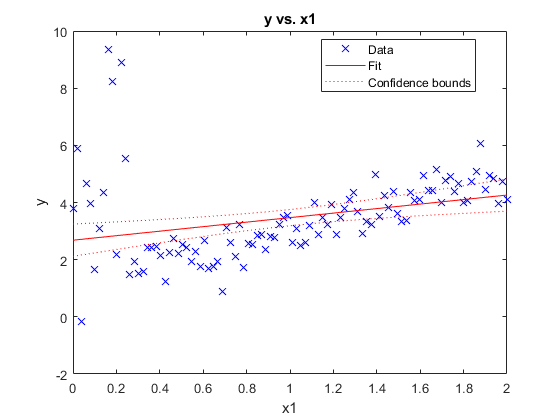
模拟的异常值出现影响拟合回归直线。
实现此吉布斯采样:
从后验分布的参数绘制 。通过放气的意见 ,创建一个具有两个回归系数的扩散先验模型,并从后验中绘制一组参数。第一个回归系数对应于截距,因此指定
bayeslm不包括截距。计算残差。
从条件后得出的值 。
运行Gibbs sampler进行20,000次迭代,并应用5000次老化周期。指定 ,预分配的后得出,并初始化 变成一个向量。
m = 20000;ν= 1;燃烧= 5000;= 1 (n,m + 1);estBeta = 0 (2,m + 1);estSigma2 = 0 (1,m + 1);对于j = 1:m yDef = y /√(lambda(:,j));xDef = [ones(n,1) x]./√(lambda(:,j));PriorMdl = bayeslm (2'模型',“扩散”,“拦截”,假);[estBeta(:,J + 1),estSigma2(1,J + 1)] =模拟(PriorMdl,xDef,yDef);EP = Y - [一(N,1)X] * estBeta(:,J + 1);SP =(NU + 1)/ 2;。SC = 2./(nu + EP ^ 2 / estSigma2(1,J + 1));拉姆达(:,J + 1)= 1./gamrnd(sp,sc);结束
一个好的实践是通过检查跟踪图来诊断MCMC采样器。为了简单起见,这个示例跳过了这个任务。
计算平均值的从回归系数后得出。删除老化时间绘制。
后测=平均值(estBeta(:,(burnin + 1):end),2)
postEstBeta =2×11.3971 1.7051
截距的估计值较低,而斜率则高于返回的估计值fitlm。
绘制与装配通过最小二乘回归直线的稳健回归线。
甘氨胆酸h =;xlim = h.XLim ';plotY = [ones(2,1) xlim]*postEstBeta;情节(xlim plotY,“线宽”2);霍奇金淋巴瘤。{4}=字符串“稳健贝叶斯;

使用强大的贝叶斯回归出现的回归拟合线是一个更好的选择。
估计最大后验概率使用蒙特卡罗
的最大后验概率(MAP)估计是后侧模式,即,参数值产生最大后验概率密度。如果是后分析棘手的,那么你可以使用蒙特卡罗抽样估计MAP。
考虑线性回归模型模拟先验分布和后验分布的参数值。
加载纳尔逊 - 普洛瑟数据集。创建响应和预测序列变量。
加载Data_NelsonPlosservarNames = {'IPI''E''WR'};X = {数据表:,varNames};Y = {数据表:,“GNPR”};
创建用于线性回归参数的正逆伽马共轭先验模型。指定预测器的数量p和变量名。
P = 3;PriorMdl = bayeslm(P,'ModelType',“共轭”,'VarNames',varNames)
PriorMdl = conjugateblm与属性:NumPredictors:3截取:1个VarNames:{4X1细胞}穆:[4X1双】V:[4×4双] A:3 B:1 |均值标准CI95正分布-----------------------------------------------------------------------------------拦截|0 70.7107 [-141.273,141.273]0.500吨(0.00,57.74 ^ 2,6)IPI |0 70.7107 [-141.273,141.273]0.500吨(0.00,57.74 ^ 2,6)E |0 70.7107 [-141.273,141.273]0.500吨(0.00,57.74 ^ 2,6)WR |0 70.7107 [-141.273,141.273]0.500吨(0.00,57.74 ^ 2,6)西格玛-2 |0.5000 0.5000 [0.138,1.616] 1.000 IG(3.00,1)
估计的边际后验分布 和 。
RNG(1);%用于重现PosteriorMdl =估计(PriorMdl,X,Y);
方法:分析后验分布若干意见:62数量预测的:4登录边缘似然:-259.348 |均值标准CI95正分布-----------------------------------------------------------------------------------拦截|-24.2494 8.7821 [-41.514,-6.985]0.003吨(-24.25,8.65 ^ 2,68)IPI |4.3913 0.1414 [4.113,4.669]1.000吨(4.39,0.14 ^ 2,68)E |0.0011 0.0003 [0.000,0.002]1.000吨(0.00,0.00 ^ 2,68)WR |2.4683 0.3490 [1.782,3.154]1.000吨(2.47,0.34 ^ 2,68)西格玛-2 |44.1347 7.8020 [31.427,61.855] 1.000 IG(34.00,0.00069)
显示包括边缘后验分布统计。
提取的后验均值
从后部模型,并提取的后协方差
从估算汇总返回由总结。
estBetaMean = PosteriorMdl.Mu;摘要=总结(PosteriorMdl);EstBetaCov =总结。协方差{1:(end - 1),1:(end - 1)};
estBetaMean是表示平均值的边缘后验的4×1矢量
。EstBetaCov4×4矩阵是否表示的是后验的协方差矩阵
。
从后验分布绘制万的参数值。
RNG(1);%用于重现[BetaSim, sigma2Sim] =模拟(PosteriorMdl,'NumDraws',1E5);
BetaSim是随机抽取的回归系数的4乘万矩阵。sigma2Sim是随机抽取的干扰方差的1逐万矢量。
对回归系数矩阵进行转置和标准化。计算回归系数的相关矩阵。
estBetaStd = SQRT(DIAG(EstBetaCov)');BetaSim = BetaSim';BetaSimStd =(BetaSim - estBetaMean')./ estBetaStd;BetaCorr = corrcov(EstBetaCov);BetaCorr =(BetaCorr + BetaCorr')/ 2;%强制对称
由于边缘后验分布是已知的,评估在所有模拟值的后验概率密度。
betaPDF = mvtpdf(BetaSimStd,BetaCorr,68);A = 34;B = 0.00069;igPDF = @(X,AP,BP)1 ./(γ-(AP)* bp的^ AP。)* X ^。( - AP-1)。* EXP(-1 ./(X * bp)的);...%反伽玛PDFsigma2PDF = igPDF (sigma2Sim, a, b);
查找模拟值,最大限度地提高各自的PDF文件,也就是后的模式。
[~,idxMAPBeta] = max (betaPDF);[~,idxMAPSigma2] = max (sigma2PDF);betaMAP = BetaSim (idxMAPBeta:);sigma2MAP = sigma2Sim (idxMAPSigma2);
betaMAP和sigma2MAP是MAP估计。
由于后 是对称的,单峰,后均值和MAP应该是相同的。比较的图估计 其平均后路。
表(betaMAP”,PosteriorMdl.Mu,'VariableNames'{“地图”,'意思'},...“RowNames”PriorMdl.VarNames)
ANS =4×2表MAP平均_________ _________拦截-24.559 -24.249 IPI 4.3964 4.3913Ë0.0011389 0.0011202 WR 2.4473 2.4683
这两个估计值相当接近。
的后验分析模式 。比较它的估计MAP 。
igMode = 1 /(B *(A + 1))
igMode = 41.4079
sigma2MAP
sigma2MAP = 41.4075
这些估计也相当接近。
输入参数
输出参数
限制
模拟不能从借鉴价值分配不当,即密度不等于1的分布。如果
MDL是一个empiricalblm模型对象,那么你可以不指定β要么σ-2。你不能用经验分布来模拟条件后验分布。
更多关于
算法
每当
模拟当必须估计的后验分布(例如,MDL代表先验分布和您提供X和ÿ)和后部是易处理的分析,模拟直接从后模拟。否则,模拟诉诸蒙特卡罗模拟来估计的后验。有关详细信息,请参阅验后估计与推理。如果
MDL那么关节后验模型呢模拟以不同的方式从其中模拟数据MDL你们提供的是联合先验模型吗X和ÿ。因此,如果你设置了相同的随机种子和生成的随机值两种方式,那么你可能无法获得相同的值。然而,基于足够数量的绘制对应经验分布实际上等同。此图显示了
模拟通过使用的值降低了样品NumDraws,瘦和模拟运行。
矩形表示连续从分配绘制。
模拟去除来自样品的白色矩形。剩余的NumDraws黑色矩形构成的样品。如果
MDL是一个semiconjugateblm模型对象,然后模拟应用吉布斯采样器从后验分布中取样。模拟使用默认值Sigma2Start对于σ2并提请值β从π(β|σ2,X,ÿ)。模拟绘制的值σ2从π(σ2|β,X,ÿ)通过使用先前生成的值β。函数重复步骤1和2直到收敛。为了评估收敛,抽取样本的轨迹曲线。
如果您指定
BetaStart, 然后模拟绘制的值σ2从π(σ2|β,X,ÿ)开始吉布斯采样。模拟不返回的这个生成值σ2。如果
MDL是一个empiricalblm模型对象,而你没有供应X和ÿ, 然后模拟从平Mdl.BetaDraws和Mdl.Sigma2Draws。如果NumDraws小于或等于numel(Mdl.Sigma2Draws), 然后模拟返回第一个NumDraws要点Mdl.BetaDraws和Mdl.Sigma2Draws作为随机抽取的对应参数。否则,模拟随机重新取样NumDraws从要素Mdl.BetaDraws和Mdl.Sigma2Draws。如果
MDL是一个customblm模型对象,然后模拟使用一个MCMC采样器从后验分布绘制。在每次迭代中,该软件串接回归系数的当前值和干扰方差成(Mdl.Intercept+Mdl.NumPredictors+ 1)- 1向量,并将它传递给Mdl.LogPDF。干扰方差的值是该矢量的最后一个元素。该HMC取样器既需要数密度及其梯度。梯度应该是一个
(NumPredictors +截距+ 1)×1向量。如果某些参数的衍生物是难以计算,然后,在梯度的对应位置,供给为NaN值来代替。模拟内容替换为NaN与数值衍生物值。如果
MDL是一个lassoblm,mixconjugateblm,或mixsemiconjugateblm模型对象和您提供X和ÿ, 然后模拟应用吉布斯采样器从后验分布中取样。如果你不提供数据,然后模拟从分析的,无条件的先验分布样本。模拟不返回默认的初始值,它生成。如果
MDL是一个mixconjugateblm要么mixsemiconjugateblm, 然后模拟从政权分布绘制第一,给定链的当前状态(的值RegimeStart,BetaStart和Sigma2Start)。如果你画一个样本,并没有为指定值RegimeStart,BetaStart和Sigma2Start, 然后模拟使用默认值,并发出警告。

也可以看看
对象
conjugateblm|customblm|diffuseblm|empiricalblm|lassoblm|mixconjugateblm|mixsemiconjugateblm|semiconjugateblm
功能
介绍了在R2017a
你也可以从以下列表中选择一个网站:
