使用分类学习者应用程序的功能选择和功能转换
Investigate Features in the Scatter Plot
在分类学习者,试图确定预测ors that separate classes well by plotting different pairs of predictors on the scatter plot. The plot can help you investigate features to include or exclude. You can visualize training data and misclassified points on the scatter plot.
Before you train a classifier, the scatter plot shows the data. If you have trained a classifier, the scatter plot shows model prediction results. Switch to plotting only the data by selectingDatain thePlot控件。
选择features to plot using theXandy列表下Predictors。
Look for predictors that separate classes well. For example, plotting the
fisheriris数据,您可以看到萼片长度和萼片宽度很好地单独setosa)。you need to plot other predictors to see if you can separate the other two classes.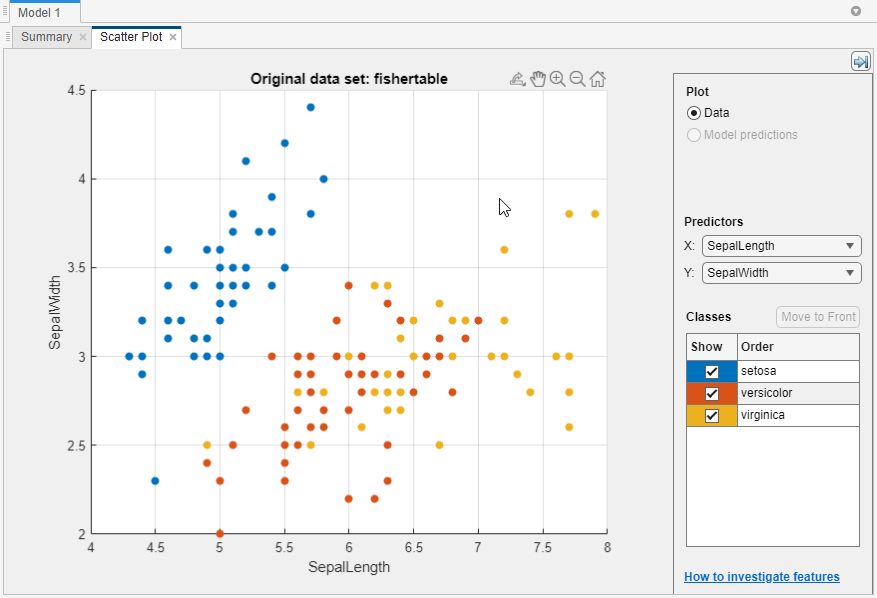
使用复选框显示或隐藏特定的类Show。
通过在下面选择一个类,更改绘制类的堆叠顺序课程and then clickingMove to Front。
通过缩小和向外放大并在整个地块上进行平移来调查更细节的细节。要启用缩放或平移,请将鼠标悬停在散点图上,然后单击显示图块右上方的工具栏上的相应按钮。
If you identify predictors that are not useful for separating out classes, then try usingFeature Selection删除它们和训练分类器,仅包括最有用的预测因素。看Select Features to Include。

After you train a classifier, the scatter plot shows model prediction results. You can show or hide correct or incorrect results and visualize the results by class. SeePlot Classifier Results。
you can export the scatter plots you create in the app to figures. See分类学习者应用中的导出图。
Select Features to Include
在分类学习者中,您可以指定在模型中包含的不同功能(或预测指标)。查看是否可以通过删除具有低预测能力的功能来改善模型。如果数据收集价格昂贵或困难,您可能会更喜欢没有某些预测因素的模型令人满意的模型。
您可以通过使用不同的功能排名算法来确定要包括哪些重要预测变量。选择一个功能排名算法后,该应用将显示分类功能重要性得分的图,其中较大的分数(包括Infs) indicate greater feature importance. The app also displays the ranked features and their scores in a table.
要在分类学习者中使用功能排名算法,请单击Feature Selectionin the选项部分Classification Learnertab. The app opens a默认功能选择标签,您可以在这些算法之间进行选择:
| Feature Ranking Algorithm | Supported Data Type | Description |
|---|---|---|
| MRMR | Categorical and continuous features | Rank features sequentially using the最小冗余最大相关性(MRMR)算法。 For more information, see |
| chi2 | Categorical and continuous features | Examine whether each predictor variable is independent of the response variable by using individual chi-square tests, and then rank features using thep卡方检验统计数据的值。分数correspond to–log(p)。 For more information, see |
| RERIEFF | 所有分类或所有连续功能 | Rank features using theRERIEFF算法。该算法最适合估算基于距离的监督模型的特征重要性,这些模型使用观测值之间的成对距离来预测响应。 For more information, see |
| 方差分析 | Categorical and continuous features | Perform one-way analysis of variance for each predictor variable, grouped by class, and then rank features using thep-values. For each predictor variable, the app tests the hypothesis that the predictor values grouped by the response classes are drawn from populations with the same mean against the alternative hypothesis that the population means are not all the same. Scores correspond to–log(p)。 For more information, see |
| Kruskal Wallis | Categorical and continuous features | Rank features using thep- 由Kruskal-Wallis Test。For each predictor variable, the app tests the hypothesis that the predictor values grouped by the response classes are drawn from populations with the same median against the alternative hypothesis that the population medians are not all the same. Scores correspond to–log(p)。 For more information, see |
选择between selecting the highest ranked features and selecting individual features.
选择选择最高的功能to avoid bias in validation metrics. For example, if you use a cross-validation scheme, then for each training fold, the app performs feature selection before training a model. Different folds can choose different predictors as the highest ranked features.
选择Select individual featuresto include specific features in model training. If you use a cross-validation scheme, then the app uses the same features across all training folds.
完成功能选择后,请单击Save and Apply。您的选择会影响所有草案模型Modelspane and will be applied to new draft models that you create using the gallery in theModels部分Classification Learnertab.
要选择单个草稿模型的功能,请打开和编辑模型摘要。单击模型Modelspane, and then click the modelSummary选项卡(如有必要)。这Summarytab includes an editableFeature Selectionsection.
训练模型后,Feature Selection部分modelSummarytab lists the features that were used to train the full model (that is, the model trained using training and validation data). To learn more about how Classification Learner applies feature selection to your data, generate code for your trained classifier.
For an example using feature selection, seeTrain Decision Trees Using Classification Learner App。
Transform Features with PCA in Classification Learner
使用主组件分析(PCA)来降低预测器空间的维度。降低维度可以在分类学习者中创建分类模型,以防止过度拟合。PCA线性转换预测变量以删除冗余尺寸,并生成一组称为主组件的新变量。
在Classification Learnertab, in the选项部分,选择PCA。
In the Default PCA Options dialog box, select theEnable PCA复选框,然后单击Save and Apply。
这app applies the changes to all existing draft models in theModels窗格和您使用画廊中创建的新草稿模型Models部分Classification Learnertab.
下一次使用模型训练训练全部按钮,
PCA函数在训练分类器之前会转换您所选功能。默认情况下,PCA仅保留解释95%差异的组件。在默认的PCA选项对话框中,您可以通过选择“解释的差异value. A higher value risks overfitting, while a lower value risks removing useful dimensions.
If you want to limit the number of PCA components manually, select
Specify number of componentsin the组件还原标准list. Select theNumber of numeric componentsvalue. The number of components cannot be larger than the number of numeric predictors. PCA is not applied to categorical predictors.
you can check PCA options for trained models in thePCA部分Summarytab. Click on a trained model in theModelspane, and then click the modelSummary选项卡(如有必要)。例如:
PCA保留足够的组件来解释95%的差异。训练后,保留了2个组件。说明每个组件的差异(顺序):92.5%,5.3%,1.7%,0.5%
To learn more about how Classification Learner applies PCA to your data, generate code for your trained classifier. For more information on PCA, see thePCA功能。
Investigate Features in the Parallel Coordinates Plot
To investigate features to include or exclude, use the parallel coordinates plot. You can visualize high-dimensional data on a single plot to see 2-D patterns. The plot can help you understand relationships between features and identify useful predictors for separating classes. You can visualize training data and misclassified points on the parallel coordinates plot. When you plot classifier results, misclassified points have dashed lines.
在Classification Learnertab, in thePlots部分,单击箭头打开画廊,然后单击Parallel Coordinatesin theValidation Resultsgroup.
在plot, drag theXtick labels to reorder the predictors. Changing the order can help you identify predictors that separate classes well.
To specify which predictors to plot, use thePredictors复选框。一个好的做法是一次绘制一些预测指标。如果您的数据有许多预测指标,则该图默认情况下显示了前10个预测指标。
如果预测因子具有显着不同的尺度,请扩展数据以更容易可视化。尝试不同的选项缩放list:
None沿着具有相同最小和最大限制的坐标标尺显示原始数据。Rangedisplays raw data along coordinate rulers that have independent minimum and maximum limits.Z-Score显示Z分数(平均为0,标准偏差为1)沿每个坐标标尺。Zero Mean显示以沿每个坐标尺为中心的数据为0。Unit Variancedisplays values scaled by standard deviation along each coordinate ruler.L2 Normdisplays 2-norm values along each coordinate ruler.
If you identify predictors that are not useful for separating out classes, useFeature Selection删除它们和训练分类器,仅包括最有用的预测因素。看Select Features to Include。
这plot of thefisheririsdata shows the petal length and petal width features separate the classes best.
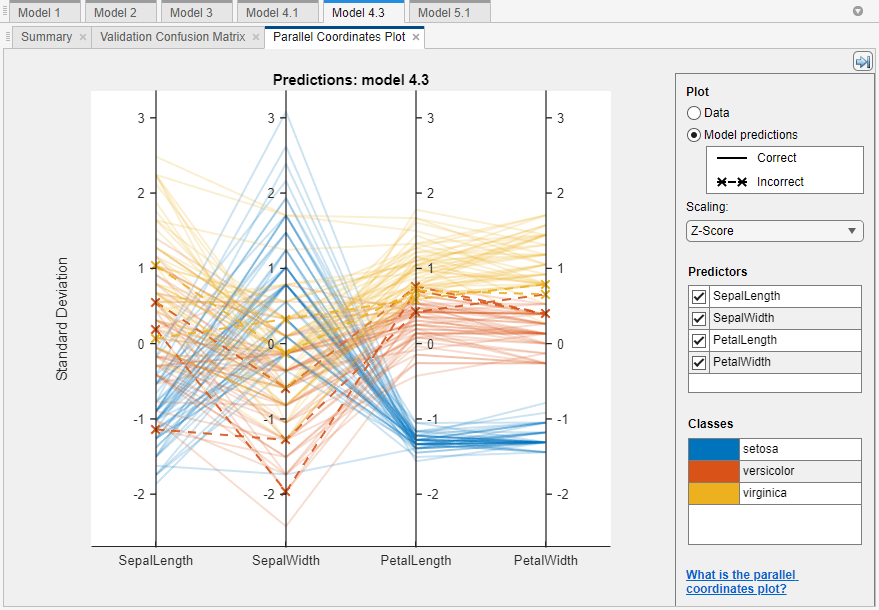
For more information, see平行页。
you can export the parallel coordinates plots you create in the app to figures. See分类学习者应用中的导出图。
Related Topics
you can also select a web site from the following list:
Americas
- América Latina(Español)
- Canada(English)
- United States(English)