计算机视觉深度学习
Johanna Pingel, MathWorks
盖伯瑞尔哈,MathWorks
概述
虽然深度学习可以在对象识别和对象检测方面达到最先进的精度,但是很难对深度学习模型进行培训、评估和比较。深度学习还需要大量的数据和计算资源。
在本次网络研讨会中,我们将探讨MATLAB如何实现®解决最常见的深度学习挑战,深入了解训练准确的深度学习模型的过程。我们将介绍用于深度学习的新功能和用于对象识别和对象检测的计算机视觉。
强调
我们将使用真实世界的例子来演示:
- 访问和管理大型映像集
- 使用可视化,以深入了解培训过程
- 利用预先训练好的网络,利用转移学习来执行新的识别任务
- 加快利用GPU的并行计算工具箱训练过程™
关于演示
Johanna Pingel于2013年加入MathWorks团队,她的专业是用MATLAB进行图像处理和计算机视觉应用。她拥有伦斯勒理工学院(Rensselaer Polytechnic Institute)的硕士学位和卡内基梅隆大学(Carnegie Mellon University)的学士学位。她在计算机视觉应用领域工作了5年多,专注于目标检测和跟踪。
大家好,我是加布里埃尔的约翰娜,今天我们要讨论的是关于计算机视觉的深度学习。我们将向您展示一些很棒的新演示和功能。我们开始吧。
我们先来设置一些context。我们的网站上还有其他的深度学习视频,比这次的网络研讨会要短得多,你们也应该看看。但最重要的是,与其他视频相比,我们将在本次网络研讨会上进行更深入的探讨。我们说的是计算机视觉的深度学习。什么是深度学习?这是一种机器学习,它直接从数据中学习特征和任务,这些数据可能是图像、文本或声音。
既然我们在讨论计算机视觉,我们自然要看图像数据。但请记住,深度学习适用于许多其他不涉及图像的任务。
正确的。让我们来看看一个快速的工作流,看看深度学习是如何工作的。假设我们有一组图像,其中每个图像包含一种或四种不同的对象。我们想要的是能自动识别每个图像中物体的东西。我们从带标签的图像开始,这意味着我们告诉深度学习算法图像包含什么。有了这些信息,它开始理解对象的特定特性并将它们与相应的类别相关联。
您会注意到任务是直接从数据中学习的,这也意味着我们对正在学习的特性没有任何影响。您可能听说过这被称为端到端学习,但是在任何情况下,只要记住深度学习直接从数据中学习特性。
这就是深度学习的基本工作。虽然深度学习的概念已经存在了一段时间,它已经成为近来更受欢迎,因为已经极大的改进这些分类的准确性,在那里他们胜过人在图像分类点技术。因此,也有一些因素,使深度学习,包括大型成套标签数据,强大的GPU来加速训练,以及使用其他人的工作为出发点,以培养自己的深层神经网络,我们将谈论的能力后来。
是的,我们会。所以,正确的在我们深入的东西,我们希望给您为什么我们做这个研讨会的一些背景和框架。深度学习是困难的。它的尖端技术,它可能很复杂,无论你在处理网络体系结构,了解如何培养一个精确的模型,并结合数千训练图像。
是啊,更何况大家的喜爱的任务,试图弄清楚为什么有些东西不能正常工作。
我们希望MATLAB能让每个人都能轻松地进行深度学习。在这个网络研讨会上,以及我们网站上的其他资源,我们将解释如何使用MATLAB快速开始深度学习。我们的网络研讨会中的示例还将演示如何处理大量图像,如何轻松地集成gpu来更快地培训深度学习模型,如何在培训时理解模型内部发生的事情,以及如何构建该领域专家的模型,这样您就不必从头开始了。有了这些,我们开始吧。
是的。让我们做它。因此,我们将涵盖三个例子,深度学习图像分类使用一个预先训练的网络,转移学习分类新对象,并在图像和视频对象检测。首先是使用预先训练好的网络进行图像分类。这里我有一张辣椒的图片,我想把它们分类。信不信由你,我可以用MATLAB写四行代码。
第一,导入一个预先训练好的模型。第二,引入图像。第三,调整图像的大小。第四,对图像进行分类。
尼斯。
就是这样了。
很酷。
好吧,就移动到第二人口统计学
他是在开玩笑。
是的,我在开玩笑。我们会讲到这里发生了什么。
那么第一行代码中的AlexNet是什么呢?亚历克斯是谁,我们为什么要用他的网?
为了直接回答你的问题,AlexNet是一个由很多人设计的卷积神经网络,包括Alex Krizhevsky。但我应该提供一些背景。有一个与MATLAB无关的独立项目叫做ImageNet项目。它的目标是拥有一个庞大的视觉内容库,比如图像,供人们用于研究和设计视觉对象识别。
因此,它在2010年开始他们跑的年度比赛堪称ImageNet大规模视觉识别挑战。
哦,是的。老ILSVRC。
是的,那竞争。所以竞争者提交软件程序来竞争正确地分类和检测对象在【听不清】。现在,直到2012年,实现计算机视觉的标准方法是通过一个称为特征工程的过程,而不是AlexNet,它使用并改进了基于深度学习的方法。所以你大概可以猜到,AlexNet是在2012年ILSVRC的团队名称监督下提交的,一个词。它把竞争对手打得落花流水,我想这既可以指竞争对手,也可以指竞争本身。
而且有很多炒作的周围,因为人们意识到深度学习不只是理论上的。这真是实用和它做事情的方式更好,比我们一直在做之前。所以,历史课之外,AlexNet被训练识别准确地1000个不同的对象,我猜有一些东西需要与ILSVRC 2012年的胜利条件这几个预训练的网络之一,你可以从MATLAB,其中还包括VGG-访问16和19。
我们是否有一个历史的教训?
我不会为那些人上历史课。让我们回到我们的四行代码。首先看看MATLAB是如何让导入一个预训练的模型变得非常简单的。没有比这更简单的了。如果你的电脑上没有AlexNet,你只需要下载一次,不管是通过add-on manager还是使用错误中的链接(如果你没有下载代码)。现在你可以用它来做这个演示和任何你想要的东西。
所以在第二行,你引入了图像。这看起来很简单。但是为什么要调整图像的大小呢?所以我第一次这么做的时候,我试着聪明地用三行代码来做。
没有调整吗?
是的。而我得到这个错误,其中提到一些关于大小,这意味着,耶,我得弄清楚为什么它不工作。
大家最喜欢做的事。
如果我做net。layers,它会告诉我网络的架构。一开始看起来有点吓人,但是第一层,输入层,大小是227 * 227像素。最后的x3是RGB值,因为这是一张彩色照片。看到这个,我想,好吧。只需使用MATLAB来调整图像的大小,这样它在传递到网络时就不会出错。最后一行代码可以对图像进行分类。
你之前提到过,AlexNet是一个卷积神经网络。这是什么意思,我可以简称它为CNN吗?
我的意思是,只要观众不把这个网络研讨会和有线电视新闻网络混淆——有线电视新闻——哦。这就是CNN所代表的,不是吗?嗯,除了CNN是一个自我参考的有线新闻网络,它还是一个流行的深度学习图像和计算机视觉问题的架构。与AlexNet无关,关于CNNs需要理解的三件主要事情是卷积、激活和池。
卷积是一种数学运算你们可能还记得大学课程里介绍过的傅里叶变换和拉普拉斯变换,不管是好是坏。这个想法是我们把我们的输入图像通过多次变换,每一个都从图像中提取特定的特征。激活对卷积的输出进行变换。一种流行的激活函数是ReLU,或ReLU,即tomato tomato,它简单地获取输出并将其映射到最高正值。最后,拉取是一个简化输出的过程,我们只取一个值带到下一层,这有助于减少模型需要了解的参数的数量。
所以这三个步骤被重复来形成整个CNN架构,它可以有数十或数百层,每一层都学会检测不同的特征。MATLAB的一个优点是它能让你看到特征图。所以如果你比较接近初始层的特性和接近最终层的特性,它们会变得越来越复杂,从颜色和边缘到看起来更详细的东西。
让我们来看看,又在AlexNet的层。你可以看到盘旋,激活和池。一些其他网络将具有这些层的不同的配置,但在最后,他们都会有其执行的分类的最终层。随着代码的几行,我们可以重复显示什么AlexNet认为这是一起的图像。有时它得到它,有时没有。但是,这是相当不错的,只要对象是在原来设定的1000。
这就引出了一个问题,如果不是这样,你能做什么?
请允许我回答这个问题,这是使用一个预先训练的模型进行的图像分类。让我们进入第二个演示。
好吧。在接下来的演示中,我们有汽车在高速公路上行驶的视频。我们想要把它们分类为汽车,卡车,或者suv。我们将使用AlexNet和微调我们的对象类别的网络,一个称为转移学习的过程,可以用来分类对象不在原来的网络。
这就是我们对前一个问题的答案。快速跟进。如果你有一个分类任务,你的对象碰巧是1000个中的一个,你有什么理由不使用AlexNet。
好问题。在这种情况下,转移学习的主要好处是有一个特定于您的数据的分类器。如果你在更少的类别上训练,你可以潜在地提高准确性。
是有意义的。
所以我把这个视频从我的手机,我能够利用IP网络摄像机就会自动把它变成MATLAB。这个功能让我的汽车在办公室窗外旅行的视频记录小时。现在,使用MATLAB和计算机视觉,我能够从基于使用一种叫做背景减除工艺相对简单的运动视频的每一帧提取汽车。
这只是观察两个连续图像之间的像素差异然后找出足够不同的东西的问题。
现在,当车辆通过传递,我们希望他们划为汽车,卡车,SUV或。这不是什么AlexNet认为,我们正在寻找。所以,如果我们目前的模式不会对我们的数据进行工作,我们需要一个新的模式。所以我们可以说,我们要五个不同类型的车辆,汽车,卡车,大卡车,越野车和面包车进行分类。我们的计划是使用AlexNet为出发点和使用转移学习创建模型具体到这五个类别。
那么,你为什么要使用转移学习,而不是从头开始训练一个网络呢?
所以从零开始训练绝对是你可以尝试的。我们给了你们MATLAB中所有的工具来做这个。但是有一些非常实际的理由让你选择转学。例如,您不必自己设置网络架构,这需要大量的尝试和错误才能找到层的良好组合。此外,与从零开始的训练相比,转移学习不需要那么多的图像来建立一个精确的模型。最后,你可以利用来自深度学习领域顶级研究人员的知识和专业知识,他们花在训练模型上的时间比我们多得多。
听起来不错。
因此,这里有大量的含有我们的五个类别的图像的五个文件夹。我们希望有一个简单的方法在此数据带来的传递给我们的深刻的学习算法。此前,加布里埃尔使用imread作为一种辣椒的形象带来。但我们不希望有对每个图像做到这一点。相反,我将使用一种叫做图像数据存储功能,这带来数据的有效方式。
我们应该注意到,在MATLAB中有许多不同类型的数据存储,用于不同的大数据和数据分析任务。所以这不仅仅是为了图像。如果你有大量的数据,数据存储是你的朋友。
因此,一旦该点的图像数据存储到我的文件夹,它会自动标示基于包含图像的文件夹的名称我所有的数据。所以,没有必要通过一个做一个。一旦我这样做,我有机会获得有用的功能,就像看到我有多少图片为每个类别,并能我的图片迅速分成训练集和测试集。
如果需要,还可以指定自定义读取函数。图像数据存储为imread,默认情况下读取所有图像,这对于标准的图像格式来说非常棒。但如果你碰巧有非标准的图像格式imread不知道如何处理,你只需要编写自己的函数,把它传递到图像数据存储中,然后你就可以开始了。
即使您有标准的图像格式,您也可以使用自定义的read函数来进行图像预处理,如调整大小、锐化或去噪。在我们的例子中,使用AlexNet,我们需要将它们的大小调整为227 * 227。这里我们使用自定义读函数。
所以,我注意到,你不这样做直了调整大小。它看起来像你的填充图像。什么是其中的原因?
所以,这只是从个人的经验。我试图调整图像和网络没有做得很好。当我看了看自己的图像,我不能告诉轿车和SUV之间的差异。所以,我没有的东西,有裁剪图像和保持纵横比的同样的效果。而且,由于这有助于保持结构上的差异,我想,可能有助于网络。所以你越早看到AlexNet确实对自己我们的汽车和卡车分类方面做得很差。因此,我们需要微调网络。
如果我们查看这些层,您可以看到最终的全连接层,它代表了AlexNet所训练的1000个类别。为了执行转移学习,我们用5个类别的对象替换了1000个。然后这一行重置分类,这意味着忘记你学过的1000个对象的名字。你只关心这五个新的。
这是你需要做的唯一核心改变吗?
是的。这就是你需要做的所有的网络操作。如果你跑了这一点,你会得到一个分类器将这些五保对象的输出之一。
我想问题是,它的效果如何?
所以我们事先训练的这个网络,它实际上得到了真正的好成绩,像97%的准确率。
这对于代码的两个小修改来说是相当令人印象深刻的。
但说实话,你可能不会马上想到这一点。记住,AlexNet是针对数百万张图像进行训练的,包括一些车辆。所以我们可以合理地假设它很顺利地传递到了我们的数据上。但是,如果你想在其他的,与原始设置非常不同的图片上学习,你可能需要做更多的改变。
是有意义的。那么,如果人们发现自己的准确率低于平均水平,他们可以尝试哪些方法呢?
你可以尝试很多事情。然后进入快速射击模式。你可以跟着这张幻灯片。首先,在您开始更改参数之前,您可以做一些事情。检查你的数据。这一点我再怎么强调也不过分。最初,我的火车模型错误地分类了很多图像。我意识到我的一些数据在错误的文件夹里。显然,如果你的设置不准确,无论是错误的文件夹还是糟糕的训练数据,你都不会取得很大的进步。
接下来,尝试获得更多的数据。有时分类需要更多的图像,以便更好地理解这个问题。最后,尝试不同的网络。我们正在与AlexNet工作,但正如我们提到的,还有其他的网络,提供给您。它可能是一个不同的CNN可以提供更好的结果。
听起来不错。所以我们可以说我敢肯定,我有我的设置正确。我现在能做什么?
所以现在的问题是改变网络和培训过程。让我们从网络开始。更改网络意味着添加、删除或修改层。您可以向网络添加另一个全连接层,从而增加网络的非线性,并根据数据帮助提高网络的准确性。您还可以修改新层的学习权重,使它们比网络的早期原始层学习得更快。如果您希望保留网络先前了解的关于原始数据的丰富特性,那么这是非常有用的。
至于改变培训过程,那只是改变培训选择的问题。你可以尝试更多的阶段,更少的阶段,以及其他选项,你可以在我们的网站上找到文档。
因此,它是公平的,我说这个。所有的选项似乎是一样,你对待网络就像一个黑盒子。如果你训练它,它不是很好,然后你把这些修改它的一个,告诉它开始训练,等待出十足的等待时间,然后你会发现,如果它确实是好还是坏事情变得简单。那么,有什么我们可以做,说,在这个过程中的中间?
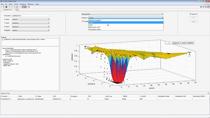
绝对的。我们有一组输出函数可以告诉我们网络在训练时发生了什么。第一幅图描绘了网络训练的准确性。理想情况下,您希望看到准确性随时间的上升趋势。如果这不是你所看到的,你可以停止训练,试着在你把时间浪费在没有进步的事情上之前解决它。你也可以根据某些条件提前停止训练。这里我告诉网络,如果我达到99。5%的准确率就停止。
而且我猜的,所以你不训练过度削减过度拟合网络。
是的。我们还有检查点的概念。你可以在一个特定的点停止网络训练,看看它在测试集中表现如何,然后如果你决定它需要更多的训练,你不必从头开始。你可以在你停止的地方继续培训。正如你所期望的,我们的网站上有关于我们许多不同培训选择的文档。如果你看这里,你可以看到选项我只是大纲图训练精度,在这里,在指定的精度停止。所以一定要尝试这些例子。
是的,请。复制粘贴此代码。还有人在那里谁从来没有像复制,粘贴代码,你在互联网上找到。我得到他们的意思,就好,不要盲目照搬的东西,它想到刚工作。但严重的家伙,让他谁是没有复制粘贴的互联网代码投第一个错误信息。
你一定要复制我们的代码。不需要自己编写所有的代码,并且在训练过程中有一些更好的控制起点,这是很好的。
假设我真的很想让我的网络得到良好的调整,我想要尽可能地消除网络的黑箱方面。所以我想你可能不能直接看到网络看到的东西。但是,我们如何才能开始更深入地了解我们的网络呢?
你可以做的一件事是想象网络在我们的图像中找到了什么特征。我们可以看到过滤器,我们可以看到这些过滤器应用后的图像结果。在第一个卷积中,我们看到我们提取出了边缘,暗模式和亮模式。它们可能很明显,也可能不那么明显。这完全取决于图像中这些特征的强度。
所以你可以在网络的任何一层都这样做?
是的。让我们来看看另外一个。这一形象的第四卷积的输出产生一些更抽象的,但有趣的功能。你可以把这个特殊的通道被发现车轮和汽车为特色的保险杠假设。为了测试我们的理论,让我们尝试另一个图像在后轮上没有图像左侧可见。如果我们的假设是正确的,那么这个通道的输出不应该激活尽可能多的在图像的左侧。这就是我们所看到的。
尼斯。所以,如果你们要调试您的网络,这种技术使您的网络看到的可视化表示,可能会帮助您更好地了解发生了什么事情的。
是的。所有的代码都在文档中。网站上的例子是通过寻找人脸的特征,但概念是一样的。我们来看看另一个你可能会发现有用的工具——deep dream。深梦可以用来制作非常有趣的艺术图像,你可能在网上看到过。但这是我们可以用来了解网络的另一个工具。Deep dream将输出一个图像,表示它在整个训练过程中所学到的特征。
所以理解这个说法是不是给网络的图像,并具有将其连接到一个班级,让我们反向走。我们给网络一个类,我们把它给我们一个图像。那么,为什么这是很有帮助的。
因此,让我们看看文档。神经网络工具箱对深学习有很大的页面。其中的一个概念,这里是深的梦想,并使用AlexNet深梦想的一个例子。我们可以看到在这里我要请母鸡,AlexNet是在训练类别之一。而深的梦想让我在一个什么样的母鸡看起来像它有些抽象的版本。我们可以为我们的任何网络中的类别产生深梦想图像。
所以如果我们看到的东西看起来不像类别,我们可以假设我们的网络可能没有正确地学习类别。
是的,这可能是与训练数据的问题。让我给你举个例子。在AlexNet原来的1000类,它有一个松鼠类别。而我正好有一群松鼠的照片,所以我们可以尝试一下我们的网络上。我们看到所有的预测是正确的,除了这一个。如果我们看看鼠笼深的梦想,我们看到了什么?又有怎样的头发,这是什么误诊为?有迹象表明,对应关系较好,我们尝试了前几个影像一些鲜明的色彩。你可以看到尾相关功能。这些都是强的特点,这一个图像没有。
从这一点上,我想我们可以添加更多的测试图像,包含这些类型的功能或缺乏我们的网络。
所以现在你有足够的时间开始深度学习,更具体地说,转移学习。但我们的例子还没讲完。还记得我们刚才放的那个视频吗?我们试着用AlexNet分类,这就是为什么我们费了这么大的力气来创建我们自己的自定义模型。使用与之前相同的算法来检测图像中的汽车,我现在可以使用我们的模型进行分类。我们可以看到我们的模型认为它们是什么以及预测的能力。
很好。
这就是转移学习的开始,还有很多关于理解你的网络并做出改进的提示和技巧。我们希望您已经看到MATLAB是如何简化处理大量图像、访问该领域专家的模型、可视化和调试网络以及使用gpu加速深度学习的。
等一下,你完全没有覆盖最后一个。
啊,原来你在注意听。
是的,我是。
是的,我们没有明确地提到它。但是如果你仔细看训练片段,输出消息表明我们是在一个单独的GPU上训练,一个NVIDIA®3.0可计算的GPU,这是使用GPU进行深度学习的最低要求。使用MATLAB的GPU计算的美妙之处在于它都是在幕后处理的。你,作为一个用户,不用担心。如果你有GPU, MATLAB默认使用GPU,如果你使用GPU或GPU集群,或云中的GPU,甚至CPU,这些功能都不会改变。
你能用CPU来训练吗?我喜欢你如何从大,更大,最大,然后缩小到基本的计算。
是的,技术上你可以使用CPU。但是让我们来看看这个在CPU和GPU上训练相同深度学习算法的视频。
哇。这是很不起眼。
是的。所有这些都适用于培训过程的任何部分,无论是培训、测试还是可视化网络。所以如果CPU是你唯一的选择,那就去争取吧。但是我们鼓励你使用GPU进行训练,或者至少确保你在训练模型时进行长时间的休息。
好吧。在最后的演示中,我们将讨论一个更有挑战性的问题这个问题经常引起我们的注意。看看这张图。如果我们把它呈现给我们的网络,它会认为它是什么?无论如何,到目前为止,我们只展示了将整个图像分类为一个类别的例子。但在这幅图中,很明显在不同的地点有不同的交通工具。我们训练的网络无法告诉我们这些。
这个经典的问题叫做目标检测,或者在场景中定位目标。在这个例子中,我们看的是几辆车的后部。我们的目标是发现它们。所以我们需要创建一个对象检测器来识别我们关心的对象。我们应该怎么做呢?
这次网络研讨会的主题是深度学习,那么深度学习呢?
太棒了。所以如果我们要训练一个车辆探测器来识别后面的车辆,它需要大量的图像来训练。现在的问题是,我们的图像数据并没有被裁剪到单独的汽车上,这意味着,乍一看,我们将不得不从头开始进行单调乏味的裁剪和标记所有图像的任务。这个网络研讨会应该持续多久?
30分钟或更少。
我不认为我们可以做到这一点。除非我们有MATLAB。好极了。对不起。因此MATLAB有内置的应用程序来帮助您完成此过程。首先,你可以快速地浏览你的所有数据,并绘制场景中的物体周围的边框。现在,尽管这比手工裁剪好,你不希望有这样做100或1000倍。所以,如果你有一个视频或图像序列,MATLAB可以自动场景标记对象的过程。
在视频的第一帧,我指定了物体的位置。MATLAB会在整个视频中跟踪它。就像这样,我有数百个新的贴了标签的汽车,而不需要做100次。现在我们有了所有的图像和我们关心的对象的边界框。同样,对于现实世界和健壮的解决方案,您将需要成千上万的对象示例。万博 尤文图斯想象一下,如果没有应用程序,你可以手动操作。
回到深度学习。我们将使用CNN来训练目标探测器。我们完全可以像以前那样导入一个预先训练好的CNN,这完全可以。但是为了向你们展示一些新的东西,我们将从头开始创建一个CNN架构。因此,我们不会实时地输出所有内容,但是在MATLAB中从头开始创建CNN只是一个卷积、激活和分层的问题—这三件事您之前已经讨论过了。
这就是我们这里的顺序。你必须决定使用多少个过滤器。由于我们将提供所有这些代码,您可以自由使用它,并从头开始创建您自己的CNN。现在是时候训练我们的探测器了。利用MATLAB的计算机视觉工具,我们实际上有两个对象探测器供您选择。很好的一点是你可以对你选择的任何一个使用相同的训练数据。因此,正如您从这段代码中看到的,您可以非常简单地尝试所有这些方法,看看它们是如何工作的。
而我们对这些探测器,这将提供一个建议,以在某些情况下使用这些文件。所以一定要看看,如果你打算使用对象检测。
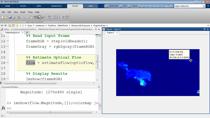
是的。因此,我们已经培训了我们的探测器。我们会尝试一下的样本图像。你可以在这里看到的结果。看起来不错。但是,对于一个更令人印象深刻的演示,让我们尝试一下上的视频。就这样吧,你可以看到,行驶在高速公路上。而且它的分类所有汽车。这是非常漂亮的。而对于高级用户,您可以访问辅助功能,以更好地了解其性能。
以下是MATLAB如何通过使用内置的应用程序快速标记数据,并使用深度学习和其他计算机视觉工具训练算法,从而简化目标检测。总结一下,请记住,虽然我们在示例中使用了大量的工具,但MATLAB和深度学习并不仅限于对工具进行分类。所以无论是人脸,狗的品种,还是一个巨大的松鼠集合,你都可以用MATLAB轻松地完成。
我想快速地呼吁我们对使用深度学习解决回归问题的支持,这意味着您万博1manbetx可以输出一个数值,而不是输出一个类或类别。我们有一些这样的例子,你可以检测到道路上的车道边界。对于那些听腻了汽车的人,我们有一个预测面部关键点的软件,可以用来预测一个人的面部表情。
今天我们看到了一些用MATLAB和深度学习可以做的新东西。我们希望你们能够清楚地看到MATLAB是如何使深度学习这个艰巨的任务变得更容易的。所以一定要检查出所有的代码在我们的网络研讨会中使用,并尝试在自己的数据。
如果你去加上经理,你会得到我们的预训练的网络,你可以在同一个地方找到一些其他资源起床和深学习,包括一个视频展示了如何使用MATLAB提供一个可快速对象分类运行摄像头。
看看我们的其他资源在我们的网站开始使用深度学习,并随时与任何问题,给我们发电子邮件image-processing@mathworks.com。
产品聚焦
记录:2017年8月2日
其他资源
相关视频和网络研讨会











您还可以选择从下面的列表中的网站: