卷积神经网络
你需要知道的三件事



是什么让CNNs如此有用?
使用CNNs进行深度学习越来越受欢迎,原因有三个重要因素:
- CNNs消除了手动提取特征的需要——这些特征是由CNN直接学习的。
- CNNs产生最先进的识别结果。
- CNNs可以为新的识别任务进行再培训,使您能够建立在已有的网络上。

深度学习工作流程。图像被传递给CNN,它会自动学习特征并对对象进行分类。
CNNs使目标检测和目标识别的发展成为可能
CNNs为图像识别和模式检测提供了一种优化的体系结构。与gpu和并行计算的发展相结合,CNNs是自动驾驶和人脸识别新发展的关键技术。
例如,深度学习应用程序使用CNNs检查数以千计的病理报告,以可视化地检测癌细胞。CNNs还能让自动驾驶汽车探测目标,并学会区分路牌和行人。
了解更多

特征学习、层次和分类
与其他神经网络一样,CNN由一个输入层、一个输出层和许多隐藏层组成。

这些层执行更改数据的操作,目的是学习特定于数据的特性。最常见的三层是:卷积、激活或ReLU和池。
- 卷积将输入图像放入一组卷积滤波器中,每个卷积滤波器激活图像中的某些特征。
- 整流线性单元(ReLU)通过将负值映射为0并保持正值,可以实现更快、更有效的培训。这有时被称为激活,因为只有被激活的特征被带到下一层。
- 池通过执行非线性下采样简化了输出,减少了网络需要学习的参数数量。
这些操作在数十或数百层中重复,每一层都要学习识别不同的特征。

一个具有许多卷积层的网络的例子。对每个训练图像应用不同分辨率的滤波器,并将每个卷积图像的输出作为下一层的输入。万博 尤文图斯
分类层
在学习了多层的特征之后,CNN的架构就转变为分类。
倒数第二层是一个完全连接的层,它输出一个K维向量,其中K是网络能够预测的类的数量。这个向量包含了被分类的每一类图像的概率。
CNN架构的最后一层使用一个分类层(如softmax)来提供分类输出。
硬件加速与gpu
卷积神经网络需要对成百上千甚至上百万的图像进行训练。当处理大量数据和复杂的网络体系结构时,gpu可以显著加快处理时间来训练模型。一旦训练了CNN,它就可以用于实时应用,比如先进的驾驶员辅助系统(ADAS)中的行人检测。
从头开始培训
从头开始创建网络意味着您要确定网络配置。这种方法为您提供了对网络的最大控制,并能产生令人印象深刻的结果,但它需要对a的结构的理解神经网络以及许多层类型和配置的选项。
虽然有时结果可能会超过转移学习(见下文),但是这种方法往往需要更多的图像来训练,因为新的网络需要很多对象的例子来理解特征的变化。培训时间通常更长,而且网络层的组合如此之多,从头配置网络可能会让人难以承受。通常,在构建网络和组织层时,参考其他网络配置有助于利用研究人员已经证明成功的技术。
了解更多
使用预先训练的模型进行迁移学习
对一个预先训练好的网络进行微调转移学习通常比从零开始训练要快得多,也容易得多。它需要最少的数据和计算资源。转移学习是利用一类问题的知识来解决类似的问题。你从一个预先训练好的网络开始,然后用它来学习一个新的任务。转移学习的一个优点是,经过预处理的网络已经学习了丰富的特性。这些特性可以广泛应用于其他类似的任务。例如,您可以使用一个训练了数百万张图像的网络,然后仅使用数百张图像对其进行重新训练以进行新的对象分类。
使用Deep Learning Toolbox,您可以使用预先训练好的CNN模型(如GoogLeNet、AlexNet、vgg16、vgg19)和来自Caffe和TensorFlow-Keras的模型进行转移学习。
了解更多
应用程序使用有线电视新闻网
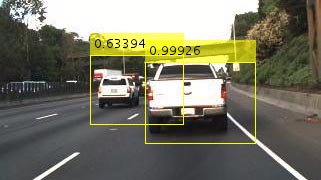
对象检测
目标检测是在图像和视频中对目标进行定位和分类的过程。计算机视觉工具箱™提供使用R-CNN(带有CNN的区域)、Fast R-CNN和Faster R-CNN创建基于深度学习的对象检测器的培训框架。
你可以使用机器学习技术统计和机器学习工具箱™用计算机视觉工具箱创建对象识别系统。
深度学习工具箱提供的功能建设和培训CNNs,以及使用训练有素的CNN模型进行预测。

如何更多地了解CNNs
s manbetx 845支万博1manbetx持使用CNNs进行图像分析的产品包括MATLAB,计算机视觉系统工具箱,统计和机器学习工具箱,深度学习工具箱。
卷积神经网络需要深度学习工具箱。在CUDA上支持训练和预测万博1manbetx®有能力的GPU与计算能力3.0或更高。建议并要求使用GPU并行计算工具箱™。
视频
- 深度学习导论:卷积神经网络是什么?(44)
- 对象识别:计算机视觉的深度学习和机器学习(26:57)
例子及如何
- 利用深度学习进行图像分类——示例
- 训练一个用于数字分类的深度神经网络——示例
- 深度学习教程——文件交换
- 使用深度学习的对象检测——示例
软件参考
- 卷积神经网络——文档
- Autoencoders——文档
- 深度学习——文档

免费试用
30天的探索就在你的指尖。

有问题吗?
和深度学习专家谈谈。