 克利夫角:克利夫·莫尔谈数学和计算机
克利夫角:克利夫·莫尔谈数学和计算机 罗兰关于MATLAB的艺术
罗兰关于MATLAB的艺术 用MATLAB进行图像处理
用MATLAB进行图像处理 人在仿真软件万博1manbetx
人在仿真软件万博1manbetx 深度学习
深度学习 开发区域
开发区域 斯图尔特的MATLAB视频
斯图尔特的MATLAB视频 在标题后面
在标题后面 本周文件交换精选
本周文件交换精选 汉斯在物联网
汉斯在物联网 学生休息室
学生休息室 初创企业、加速器和企业家
初创企业、加速器和企业家 MATLAB社区
MATLAB社区 MATLABユーザーコミュニティー
MATLABユーザーコミュニティー深度学习:迁移学习在10行MATLAB代码
Avi格式的本周最佳深度学习:迁移学习在10行MATLAB代码由MathWorks深度学习工具箱团队.
你是否曾经想通过深度学习来解决问题,但因为没有足够的数据或不喜欢设计深度神经网络而没有成功?迁移学习是通过修改现有的深度网络(通常由专家训练)来使用深度学习的一种非常实用的方法。这篇文章详细解释了迁移学习是如何工作的。在你阅读这篇文章的剩余部分之前,我强烈建议你看一下这个视频乔·希克林(Joe Hicklin,见下图)的文章,我将对此进行更详细的解释。

我试图用迁移学习来解决的问题是区分5类食物——纸杯蛋糕、汉堡、苹果派、热狗和冰淇淋。要开始,你需要两件事:
- 训练我们试图识别的不同类型食物的图像
- 一个预先训练的深度神经网络,我们可以为我们的数据和任务重新训练它
负荷训练图像
我有我所有的图像存储在“训练数据”文件夹与子目录对应的不同类。我选择这个结构是因为它允许imageDataStore使用文件夹名称作为图像类别的标签。
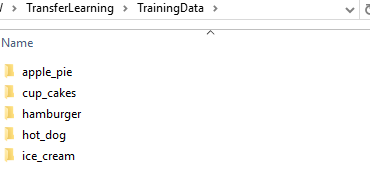
为了将图像导入MATLAB,我使用imageDatastore。imageDataStore用于管理大型映像集合。用一行代码,我可以把我所有的训练数据带入MATLAB,在我的情况下,我有几千张图像,但我将使用相同的代码,即使我有数百万张图像。使用imageDataStore的另一个优势是,它支持从磁盘、网络驱动器、数据库和Hadoop等大数据文件系统读取万博1manbetx图像。
allImages = imageDatastore (“TrainingData”,“IncludeSubfolders”,真的,“LabelSource”,“foldernames”);
然后我将训练数据分成两组,一组用于训练,另一组用于测试,其中80%用于训练,其余用于测试。
[trainingImages, testestimages] = splitEachLabel(alimages, 0.8,“随机”);
负载预训练网络(AlexNet)
我的下一步是加载一个预先训练的模型,我将使用AlexNet,这是一个深度卷积神经网络,它已经被训练识别1000种类别的物体,并在数百万张图像上训练。AlexNet已经学会了如何进行基本的图像预处理,这是在它的早期层中区分不同类别的图像所必需的,我的目标是将这种学习“转移”到我的任务中去分类不同种类的食物。
亚历克斯= alexnet;
现在让我们来看看AlexNet卷积神经网络的结构。
层=亚历克斯。层
图层= 25x1图层数组227 x227x3数据的图像输入图像的zerocenter正常化2 conv1卷积96年11 x11x3旋转步[4 4]和填充[0 0]3‘relu1 ReLU ReLU 4 norm1的横通道正常化横通道正常化与5频道/元素5“pool1”马克斯池3 x3马克斯池步(2 - 2)和填充[0 0]6“conv2”卷积256 5 x5x48旋转步[1]和填充(2 2]7‘relu2 ReLU ReLU 8 norm2的横通道正常化横通道正常化与5频道/元素9“pool2”马克斯池3 x3马克斯池步(2 - 2)和填充[0 0]384 3 x3x256 conv3的卷积运算与步幅[1]和填充[1]11‘relu3 ReLU ReLU 12 conv4卷积384 3 x3x192旋转步[1]和填充[1]13的relu4 ReLU ReLU 14 conv5卷积256 3 x3x192旋转步[1]和填充[1]15 ' relu5 ReLU ReLU 16“pool5”马克斯池3 x3 Max池步(2 - 2)和填充[0 0]17 fc6完全连接4096完全连接18层的relu6 ReLU ReLU 19“drop6”辍学50%辍学20“fc7”完全连接4096完全连接层21 ' relu7 ReLU ReLU 22“drop7”辍学50%辍学23 fc8完全连接1000完全连接层24“概率”Softmax Softmax 25“输出”分类输出crossentropyex“鲤鱼”,“金鱼”,998其他的类
修改Pre-trained网络
AlexNet被训练识别1000个类,我们需要修改它来识别5个类。为此,我要修改几个图层。注意最后几个层的结构现在与AlexNet有什么不同
层(23)= fullyConnectedLayer (5);层(25)= classificationLayer
图层= 25x1图层数组227 x227x3数据的图像输入图像的zerocenter正常化2 conv1卷积96年11 x11x3旋转步[4 4]和填充[0 0]3‘relu1 ReLU ReLU 4 norm1的横通道正常化横通道正常化与5频道/元素5“pool1”马克斯池3 x3马克斯池步(2 - 2)和填充[0 0]6“conv2”卷积256 5 x5x48旋转步[1]和填充(2 2]7‘relu2 ReLU ReLU 8 norm2的横通道正常化横通道正常化与5频道/元素9“pool2”马克斯池3 x3马克斯池步(2 - 2)和填充[0 0]384 3 x3x256 conv3的卷积运算与步幅[1]和填充[1]11‘relu3 ReLU ReLU 12 conv4卷积384 3 x3x192旋转步[1]和填充[1]13的relu4 ReLU ReLU 14 conv5卷积256 3 x3x192旋转步[1]和填充[1]15 ' relu5 ReLU ReLU 16“pool5”马克斯池3 x3 Max池步(2 - 2)和填充[0 0]17 fc6完全连接4096完全连接layer 18 'relu6' ReLU ReLU 19 'drop6' Dropout 50% Dropout 20 'fc7' Fully Connected 4096 full Connected layer 21 'relu7' ReLU ReLU 22 'drop7' Dropout 50% Dropout 23 " Fully Connected 5 Fully Connected layer 24 ' prox ' Softmax Softmax 25 " Classification Output crossentropyex full - Connected 4096 full Connected layer 21 'relu7' ReLU ReLU 22 'drop7' Dropout 50% Dropout 23 " full Connected 5 Fully Connected layer 24 ' prox ' Softmax Softmax 25 " Classification Output crossentropyex全连接
执行转移学习
现在我已经修改了网络结构,现在是时候学习我们修改的最后几层的权重了。对于迁移学习,我们希望稍微改变一下网络。在训练过程中,网络的变化是由学习速率控制的。这里我们不修改原始层的学习速率,即前3层的学习速率。这些层的利率已经相当低,所以不需要进一步降低。你甚至可以将这些早期层的重量设置为零。
选择= trainingOptions (“个”,“InitialLearnRate”, 0.001,“MaxEpochs”, 20岁,“MiniBatchSize”, 64);
关于imageDataStore的一个伟大的事情,它让我指定一个“自定义”读取功能,在这种情况下,我只是简单地调整输入图像的227×227像素,这是AlexNet所期望的。我可以通过指定一个带有代码的函数句柄来读取和预处理图像。
trainingImages。ReadFcn = @readFunctionTrain;
现在让我们开始训练网络,这个过程在桌面GPU上通常需要5-20分钟。现在是喝杯咖啡的好时机。
myNet = trainNetwork(trainingImages, layers, opts);
单GPU训练。初始化图像正常化。|=========================================================================================| | 时代| |迭代时间| Mini-batch | Mini-batch |基地学习| | | | | | |精度损失速率(秒) | |=========================================================================================| | 1 | 1 | 2.32 | 1.9052 | 26.56% | 0.0010 | |1|50|42.65 | 0.7895 | 73.44% | 0.0010 | | 2 | 100 | 83.74 | 0.5341 | 87.50% | 0.0010 | | 3 | 150 | 124.51 | 0.3321 | 87.50% | 0.0010 | | 4 | 200 | 165.79 | 0.3374 | 87.50% | 0.0010 | | 5 | 250 | 208.79 | 0.2333 | 87.50% | 0.0010 | | 5 | 300 | 250.70 | 0.1183 | 96.88% | 0.0010 | | 6 | 350 | 291.97 | 0.1157 | 96.88% | 0.0010 | | 7 | 400 | 333.00 | 0.1074 | 93.75% | 0.0010 | | 8 | 450 | 374.26 | 0.0379 | 98.44% | 0.0010 | | 9 | 500 | 415.51 | 0.0699 | 96.88% | 0.0010 | | 9 | 550 | 456.80 | 0.1083 | 95.31% | 0.0010 | | 10 | 600 | 497.80 | 0.1243 | 93.75% | 0.0010 | | 11 | 650 | 538.83 | 0.0231 | 100.00% | 0.0010 | | 12 | 700 | 580.26 | 0.0353 | 96.88% | 0.0010 | | 13 | 750 | 621.47 | 0.0154 | 100.00% | 0.0010 | | 13 | 800 | 662.39 | 0.0104 | 100.00% | 0.0010 | | 14 | 850 | 703.69 | 0.0360 | 98.44% | 0.0010 | | 15 | 900 | 744.72 | 0.0065 | 100.00% | 0.0010 | | 16 | 950 | 785.74 | 0.0375 | 98.44% | 0.0010 | | 17 | 1000 | 826.64 | 0.0102 | 100.00% | 0.0010 | | 17 | 1050 | 867.78 | 0.0026 | 100.00% | 0.0010 | | 18 | 1100 | 909.37 | 0.0019 | 100.00% | 0.0010 | | 19 | 1150 | 951.01 | 0.0120 | 100.00% | 0.0010 | | 20 | 1200 | 992.63 | 0.0009 | 100.00% | 0.0010 | | 20 | 1240 | 1025.67 | 0.0015 | 100.00% | 0.0010 | |=========================================================================================|
测试网络性能
现在让我们在测试集中测试我们新的“零食识别器”的性能。我们将看到,该算法的准确率超过80%。您可以通过添加更多的训练数据或调整一些训练参数来提高准确性。
testImages。ReadFcn = @readFunctionTrain;predictedLabels =分类(myNet, testestimages);accuracy = mean(predictedLabels == testImages.Labels)
精度= 0.8260
在直播视频中尝试分类器
既然我们已经有了一个基于深度学习的零食识别器,我鼓励你去抓一份零食,自己试一试。
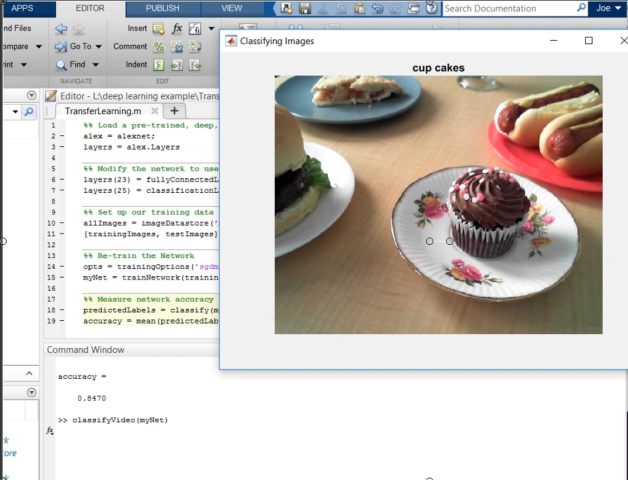
也看看这个视频由Joe,展示了如何通过网络摄像头在直播流中进行图像识别。
- 类别:
- 选择


另请参阅
-

图像分类的深度学习
博客
-
创建一个简单的DAG网络
博客
-
-



评论
要留下评论,请点击在这里登录到您的MathWorks帐户或创建一个新帐户。