在这段视频中,我将讨论构建一个自动交易员,它能够在交易成本存在的情况下,使用强化学习来决定何时对冲欧式看涨期权合约。
把套期保值看作是家庭保险,但在金融领域,我们使用套期保值来减少股票价格波动带来的风险。
股在每个时间步交易量使用增量从Black-Scholes公式计算。因此,如果呼叫选项对100股MLB股票和δ是0.1,交易者需要短10股MLB的。
在现实世界中的场景,其中交易成本的存在,它变得至关重要,同时观察市场,知道什么时候该期权的有效期期间对冲有交易成本和风险对冲之间的权衡。
让我们看看如何运用套期保值强化学习。
代理人正在观察金融市场的输入,如股票价格、到期时间、期权价格和股票持有量,并采取是否对冲的行动。如果代理对冲,新持有的股票是-51使用德尔塔计算。因此,代理卖出了6只股票,交易成本为$3。如果代理人不进行对冲,所持股份将保持不变。
后一个时期,股票价格移动到$ 99.40。代理观察利润总额和股票价格的变化而导致的损失,期权价格的变化,支付交易成本,以及相关的总利润和损失的奖励。
在强化学习,代理将通过试错学习通过选择时,期权的寿命期间,对冲最大限度的累积回报。
RL设置由一个代理和一个环境组成。环境向代理发送一个状态,代理将采取相应的操作。代理将根据它返回的奖励来评估它的最后一个动作。这个循环一直持续下去,直到环境发送一个终端状态,比如选项的成熟度,从而结束该事件。在每一集之后,代理人将学会采取行动,使累积奖励最大化。
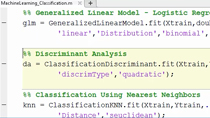
MATLAB使得它更容易建立环境而设计的强化学习组件。
复位函数返回环境的初始状态。这就是所谓的在每个训练情节初。
阶梯函数指定环境如何前进到下一个状态基于其采取行动的代理执行。
观察包括股票价格、到期时间和代理人持有的股票。
该行为是否是对冲与否。
这些意见,动作和复位,阶跃函数形成的环境。
代理由政策和强化学习算法。该政策是观察和动作之间的映射功能。它可以是通过指定层,激活函数,和神经元设计了一个神经网络。
加强学习算法不断更新的策略参数和会发现,最大化累积回报的最优策略。
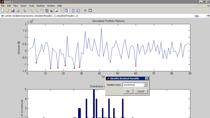
我们培养的代理了一个小时,我们可以看到该代理已经学会最大限度地随时间的累积回报。
其结果是,一个训练有素的代理人跑赢谁使用风险对冲和另一谁没有决定在所有对冲交易者。
我们模拟一个随机的股票路径,当所有的时间段都被对冲时,损失是120美元。经纪人对冲了38个时间段,12次没有交易,损失为55美元。
感谢您的收看。