Deep Network Quantizer
Description
Use theDeep Network Quantizerapp to reduce the memory requirement of a deep neural network by quantizing weights, biases, and activations of convolution layers to 8-bit scaled integer data types. Using this app you can:
Visualize the dynamic ranges of convolution layers in a deep neural network.
Select individual network layers to quantize.
Assess the performance of a quantized network.
Generate GPU code to deploy the quantized network using GPU Coder™.
Generate HDL code to deploy the quantized network to an FPGA using Deep Learning HDL Toolbox™.
Generate C++ code to deploy the quantized network to an ARM Cortex-A microcontroller usingMATLAB®Coder™.
Generate a simulatable quantized network that you can explore in MATLAB without generating code or deploying to hardware.
This app requiresDeep Learning ToolboxModel Quantization Library. To learn about the products required to quantize a deep neural network, seeQuantization Workflow Prerequisites.
Open the Deep Network Quantizer App
MATLAB command prompt: Enter
deepNetworkQuantizer.MATLAB toolstrip: On theAppstab, underMachine Learning and Deep Learning, click the app icon.
Examples
Quantize a Network for GPU Deployment
To explore the behavior of a neural network with quantized convolution layers, use theDeep Network Quantizerapp. This example quantizes the learnable parameters of the convolution layers of thesqueezenetneural network after retraining the network to classify new images according to theTrain Deep Learning Network to Classify New Imagesexample.
This example uses a DAG network with the GPU execution environment.
Load the network to quantize into the base workspace.
loadsqueezenetmerchnet
net = DAGNetwork with properties: Layers: [68×1 nnet.cnn.layer.Layer] Connections: [75×2 table] InputNames: {'data'} OutputNames: {'new_classoutput'}
Define calibration and validation data.
应用程序使用校准数据netw锻炼ork and collect the dynamic ranges of the weights and biases in the convolution and fully connected layers of the network and the dynamic ranges of the activations in all layers of the network. For the best quantization results, the calibration data must be representative of inputs to the network.
The app uses the validation data to test the network after quantization to understand the effects of the limited range and precision of the quantized learnable parameters of the convolution layers in the network.
In this example, use the images in theMerchDatadata set. Define anaugmentedImageDatastoreobject to resize the data for the network. Then, split the data into calibration and validation data sets.
unzip('MerchData.zip'); imds = imageDatastore('MerchData',...'IncludeSubfolders',true,...'LabelSource','foldernames'); [calData, valData] = splitEachLabel(imds, 0.7,'randomized'); aug_calData = augmentedImageDatastore([227 227], calData); aug_valData = augmentedImageDatastore([227 227], valData);
At the MATLAB command prompt, open the app.
deepNetworkQuantizer
In the app, clickNewand selectQuantize a network.
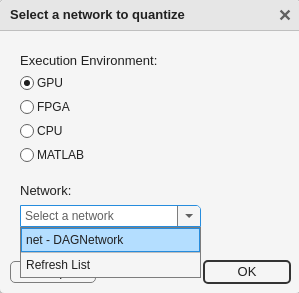
The app verifies your execution environment. For more information, seeQuantization Workflow Prerequisites.
In the dialog, select the execution environment and the network to quantize from the base workspace. For this example, select a GPU execution environment and the DAG network,net.
The app displays the layer graph of the selected network.
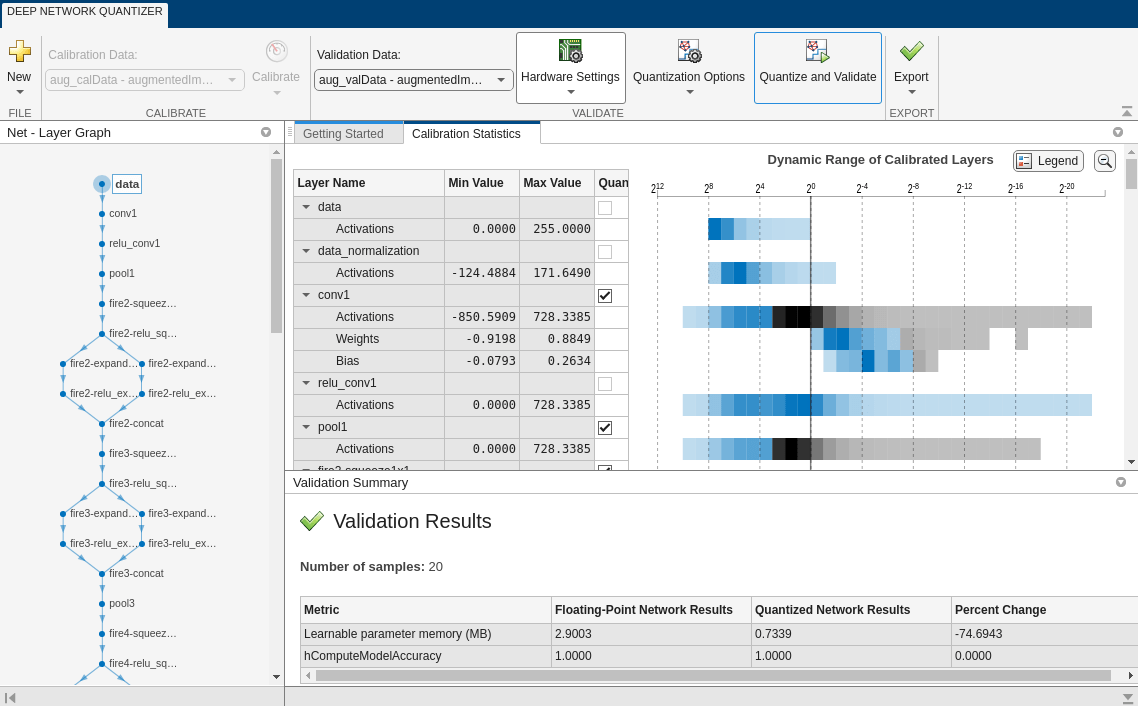
In theCalibratesection of the toolstrip, underCalibration Data, select theaugmentedImageDatastoreobject from the base workspace containing the calibration data,aug_calData. SelectCalibrate.
TheDeep Network Quantizeruses the calibration data to exercise the network and collect range information for the learnable parameters in the network layers.
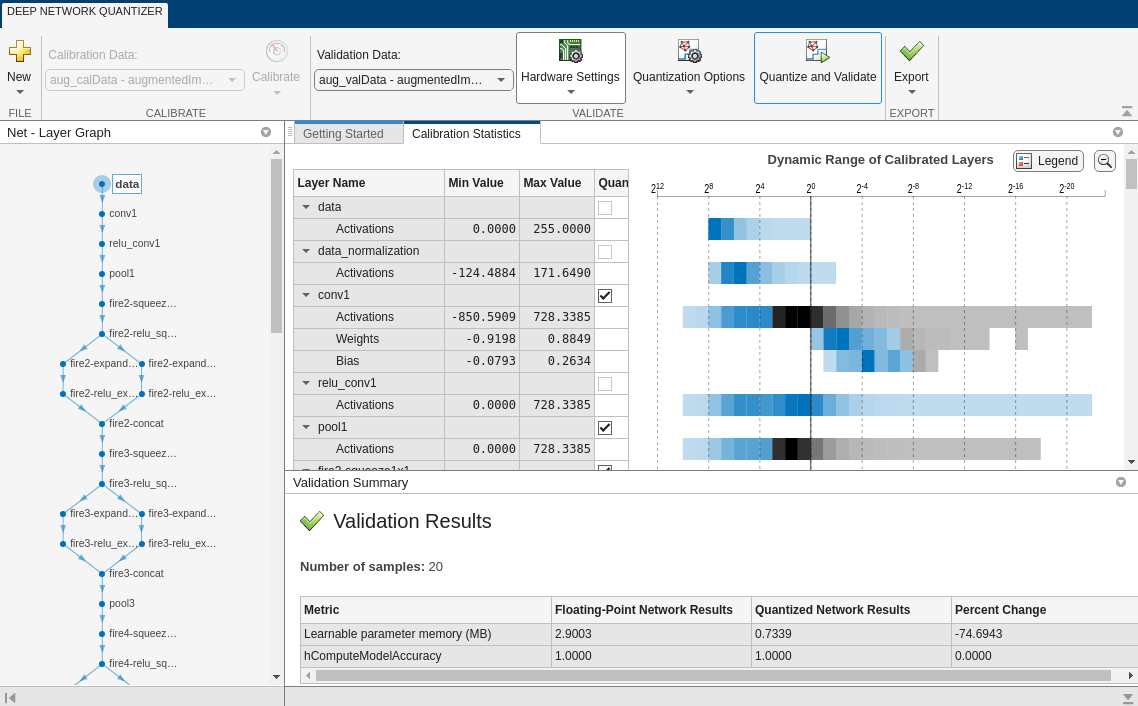
When the calibration is complete, the app displays a table containing the weights and biases in the convolution and fully connected layers of the network and the dynamic ranges of the activations in all layers of the network and their minimum and maximum values during the calibration. To the right of the table, the app displays histograms of the dynamic ranges of the parameters. The gray regions of the histograms indicate data that cannot be represented by the quantized representation. For more information on how to interpret these histograms, seeQuantization of Deep Neural Networks.
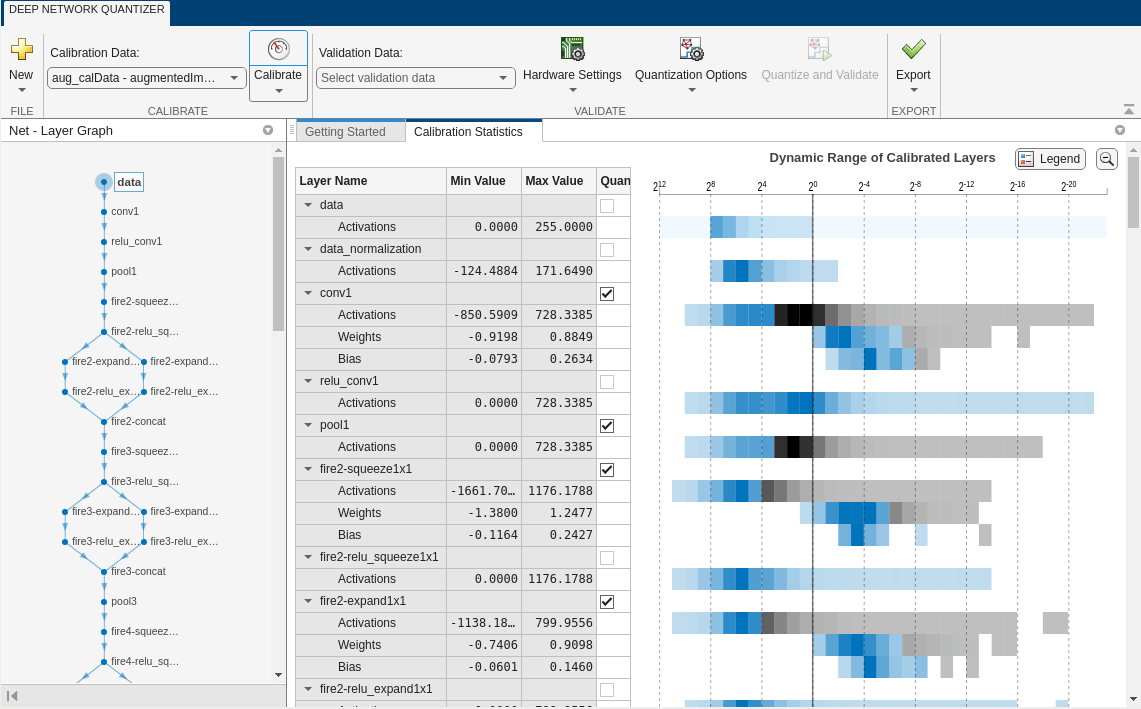
In theQuantizecolumn of the table, indicate whether to quantize the learnable parameters in the layer. Layers that are not quantized remain in single-precision after quantization.
In theValidatesection of the toolstrip, underValidation Data, select theaugmentedImageDatastoreobject from the base workspace containing the validation data,aug_valData.
In theValidatesection of the toolstrip, underQuantization Options, select theDefaultmetric function andMinMaxexponent scheme. Select数字转换和验证.
TheDeep Network Quantizerquantizes the weights, activations, and biases of convolution layers in the network to scaled 8-bit integer data types and uses the validation data to exercise the network. The app determines a default metric function to use for the validation based on the type of network that is being quantized. For a classification network, the app uses Top-1 Accuracy.
When the validation is complete, the app displays the results of the validation, including:
Metric function used for validation
Result of the metric function before and after quantization
Memory requirement of the network before and after quantization (MB)

If you want to use a different metric function for validation, for example to use the Top-5 accuracy metric function instead of the default Top-1 accuracy metric function, you can define a custom metric function. Save this function in a local file.
functionaccuracy = hComputeModelAccuracy(predictionScores, net, dataStore)%% Computes model-level accuracy statistics% Load ground truthtmp = readall(dataStore); groundTruth = tmp.response;% Compare with predicted label with actual ground truthpredictionError = {};foridx=1:numel(groundTruth) [~, idy] = max(predictionScores(idx,:)); yActual = net.Layers(end).Classes(idy); predictionError{end+1} = (yActual == groundTruth(idx));%#okend% Sum all prediction errors.predictionError = [predictionError{:}]; accuracy = sum(predictionError)/numel(predictionError);end
To revalidate the network using this custom metric function, underQuantization Options, enter the name of the custom metric function,hComputeModelAccuracy. SelectAddto addhComputeModelAccuracyto the list of metric functions available in the app. SelecthComputeModelAccuracyas the metric function to use.
The custom metric function must be on the path. If the metric function is not on the path, this step will produce an error.
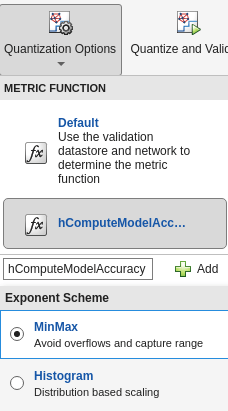
Select数字转换和验证.
The app quantizes the network and displays the validation results for the custom metric function.
The app displays only scalar values in the validation results table. To view the validation results for a custom metric function with non-scalar output, export thedlquantizerobject as described below, then validate using thevalidatefunction at the MATLAB command window.
If the performance of the quantized network is not satisfactory, you can choose to not quantize some layers by deselecting the layer in the table. You can also explore the effects of choosing a different exponent selection scheme for quantization in theQuantization Optionsmenu. To see the effects of these changes, select数字转换和验证again.
After calibrating the network, you can choose to export the quantized network or thedlquantizerobject. Select theExportbutton. In the drop down, select from the following options:
Export Quantized Network- Add the quantized network to the base workspace. This option exports a simulatable quantized network that you can explore in MATLAB without deploying to hardware.
Export Quantizer- Add the
dlquantizerobject to the base workspace. You can save thedlquantizerobject and use it for further exploration in theDeep Network Quantizerapp or at the command line, or use it to generate code for your target hardware.Generate Code- Open theGPU Coderapp and generate GPU code from the quantized neural network. Generating GPU code requires a GPU Coder™ license.
Quantize a Network for CPU Deployment
To explore the behavior of a neural network with quantized convolution layers, use theDeep Network Quantizerapp. This example quantizes the learnable parameters of the convolution layers of thesqueezenetneural network after retraining the network to classify new images according to theTrain Deep Learning Network to Classify New Imagesexample.
This example uses a DAG network with the CPU execution environment.
Load the network to quantize into the base workspace.
loadsqueezenetmerchnet
net = DAGNetwork with properties: Layers: [68×1 nnet.cnn.layer.Layer] Connections: [75×2 table] InputNames: {'data'} OutputNames: {'new_classoutput'}
Define calibration and validation data.
应用程序使用校准数据netw锻炼ork and collect the dynamic ranges of the weights and biases in the convolution and fully connected layers of the network and the dynamic ranges of the activations in all layers of the network. For the best quantization results, the calibration data must be representative of inputs to the network.
The app uses the validation data to test the network after quantization to understand the effects of the limited range and precision of the quantized learnable parameters of the convolution layers in the network.
In this example, use the images in theMerchDatadata set. Define anaugmentedImageDatastoreobject to resize the data for the network. Then, split the data into calibration and validation data sets.
unzip('MerchData.zip'); imds = imageDatastore('MerchData',...'IncludeSubfolders',true,...'LabelSource','foldernames'); [calData, valData] = splitEachLabel(imds, 0.7,'randomized'); aug_calData = augmentedImageDatastore([227 227], calData); aug_valData = augmentedImageDatastore([227 227], valData);
At the MATLAB command prompt, open the app.
deepNetworkQuantizer
In the app, clickNewand selectQuantize a network.
The app verifies your execution environment. For more information, seeQuantization Workflow Prerequisites.
In the dialog, select the execution environment and the network to quantize from the base workspace. For this example, select a CPU execution environment and the DAG network,net.

The app displays the layer graph of the selected network.
In theCalibratesection of the toolstrip, underCalibration Data, select theaugmentedImageDatastoreobject from the base workspace containing the calibration data,aug_calData. SelectCalibrate.
TheDeep Network Quantizeruses the calibration data to exercise the network and collect range information for the learnable parameters in the network layers.
When the calibration is complete, the app displays a table containing the weights and biases in the convolution and fully connected layers of the network and the dynamic ranges of the activations in all layers of the network and their minimum and maximum values during the calibration. To the right of the table, the app displays histograms of the dynamic ranges of the parameters. The gray regions of the histograms indicate data that cannot be represented by the quantized representation. For more information on how to interpret these histograms, seeQuantization of Deep Neural Networks.

In theQuantizecolumn of the table, indicate whether to quantize the learnable parameters in the layer. Layers that are not quantized remain in single-precision after quantization.
In theValidatesection of the toolstrip, underValidation Data, select theaugmentedImageDatastoreobject from the base workspace containing the validation data,aug_valData.
In theValidatesection of the toolstrip, underHardware Settings, selectRaspberry Pias theSimulation Environment. The app auto-populates the Target credentials from an existing connection or from the last successful connection. You can also use this option to create a new Raspberry Pi connection.

In theValidatesection of the toolstrip, underQuantization Options, select theDefaultmetric function andMinMaxexponent scheme. Select数字转换和验证.
TheDeep Network Quantizerquantizes the weights, activations, and biases of convolution layers in the network to scaled 8-bit integer data types and uses the validation data to exercise the network. The app determines a default metric function to use for the validation based on the type of network that is being quantized. For a classification network, the app uses Top-1 Accuracy.
When the validation is complete, the app displays the results of the validation, including:
Metric function used for validation
Result of the metric function before and after quantization
Memory requirement of the network before and after quantization (MB)

If the performance of the quantized network is not satisfactory, you can choose to not quantize some layers by deselecting the layer in the table. You can also explore the effects of choosing a different exponent selection scheme for quantization in theQuantization Optionsmenu. To see the effects of these changes, select数字转换和验证again.
After calibrating the network, you can choose to export the quantized network or thedlquantizerobject. Select theExportbutton. In the drop down, select from the following options:
Export Quantized Network- Add the quantized network to the base workspace. This option exports a simulatable quantized network that you can explore in MATLAB without deploying to hardware.
Export Quantizer- Add the
dlquantizerobject to the base workspace. You can save thedlquantizerobject and use it for further exploration in theDeep Network Quantizerapp or at the command line, or use it to generate code for your target hardware.Generate Code- Open theMATLAB Coderapp and generate C++ code from the quantized neural network. Generating C++ code requires a MATLAB Coder™ license.
Quantize a Network for FPGA Deployment
To explore the behavior of a neural network that has quantized convolution layers, use theDeep Network Quantizerapp. This example quantizes the learnable parameters of the convolution layers of theLogoNet神经网络的FPGA的目标。
For this example, you need the products listed underFPGAinQuantization Workflow Prerequisites.
加载pretrained网络to quantize into the base workspace. Create a file in your current working folder calledgetLogoNetwork.m. In the file, enter:
functionnet = getLogoNetworkif~isfile('LogoNet.mat') url ='//www.tianjin-qmedu.com/supportfiles/gpucoder/cnn_models/logo_detection/LogoNet.mat'; websave('LogoNet.mat',url);enddata = load('LogoNet.mat'); net = data.convnet;end
加载pretrained网络.
snet = getLogoNetwork;
snet = SeriesNetwork with properties: Layers: [22×1 nnet.cnn.layer.Layer] InputNames: {'imageinput'} OutputNames: {'classoutput'}
Define calibration and validation data to use for quantization.
TheDeep Network Quantizerapp uses calibration data to exercise the network and collect the dynamic ranges of the weights and biases in the convolution and fully connected layers of the network. The app also exercises the dynamic ranges of the activations in all layers of the LogoNet network. For the best quantization results, the calibration data must be representative of inputs to the LogoNet network.
量化后,应用程序使用验证哒ta set to test the network to understand the effects of the limited range and precision of the quantized learnable parameters of the convolution layers in the network.
In this example, use the images in thelogos_datasetdata set to calibrate and validate the LogoNet network. Define animageDatastoreobject, then split the data into calibration and validation data sets.
Expedite the calibration and validation process for this example by using a subset of the calibration and validation data. Store the new reduced calibration data set incalData_conciseand the new reduced validation data set invalData_concise.
currentDir = pwd; openExample('deeplearning_shared/QuantizeNetworkForFPGADeploymentExample') unzip('logos_dataset.zip'); imds = imageDatastore(fullfile(currentDir,'logos_dataset'),...'IncludeSubfolders',true,'FileExtensions','.JPG','LabelSource','foldernames'); [calData,valData] = splitEachLabel(imds,0.7,'randomized'); calData_concise = calData.subset(1:20); valData_concise = valData.subset(1:6);
Open theDeep Network Quantizerapp.
deepNetworkQuantizer
ClickNewand selectQuantize a network.
Set the execution environment to FPGA and selectsnet - SeriesNetworkas the network to quantize.

The app displays the layer graph of the selected network.
UnderCalibration Data, select thecalData_concise - ImageDatastoreobject from the base workspace containing the calibration data.
ClickCalibrate. By default, the app uses the host GPU to collect calibration data, if one is available. Otherwise, the host CPU is used. You can use theCalibratedrop down menu to select the calibration environment.
TheDeep Network Quantizerapp uses the calibration data to exercise the network and collect range information for the learnable parameters in the network layers.
When the calibration is complete, the app displays a table containing the weights and biases in the convolution and fully connected layers of the network. Also displayed are the dynamic ranges of the activations in all layers of the network and their minimum and maximum values recorded during the calibration. The app displays histograms of the dynamic ranges of the parameters. The gray regions of the histograms indicate data that cannot be represented by the quantized representation. For more information on how to interpret these histograms, seeQuantization of Deep Neural Networks.

In theQuantize Layercolumn of the table, indicate whether to quantize the learnable parameters in the layer. Layers that are not quantized remain in single-precision.
UnderValidation Data, select thevalData_concise - ImageDatastoreobject from the base workspace containing the validation data.
In theHardware Settingssection of the toolstrip, select the environment to use for validation of the quantized network. For more information on these options, seeHardware Settings.
For this example, selectXilinx ZC706 (zc706_int8)andJTAG.

UnderQuantization Options, select theDefaultmetric function andMinMaxexponent scheme. For more information on these options, seeQuantization Options.
Click数字转换和验证.
TheDeep Network Quantizerapp quantizes the weights, activations, and biases of convolution layers in the network to scaled 8-bit integer data types and uses the validation data to exercise the network. The app determines a default metric function to use for the validation based on the type of network that is being quantized. For more information, seeQuantization Options.
When the validation is complete, the app displays the validation results.

After quantizing and validating the network, you can choose to export the quantized network.
Click theExportbutton. In the drop-down list, selectExport Quantizerto create adlquantizerobject in the base workspace. You can deploy the quantized network to your target FPGA board and retrieve the prediction results by using MATLAB. For an example, seeClassify Images on FPGA Using Quantized Neural Network(Deep Learning HDL Toolbox).
Import adlquantizerObject into the Deep Network Quantizer App
这个例子shows you how to import adlquantizerobject from the base workspace into theDeep Network Quantizerapp. This allows you to begin quantization of a deep neural network using the command line or the app, and resume your work later in the app.
Open theDeep Network Quantizerapp.
deepNetworkQuantizer
In the app, clickNewand selectImport dlquantizer object.

In the dialog, select thedlquantizerobject to import from the base workspace. For this example, usequantObjthat you create in the above example Quantize a Neural Network for GPU Target.

The app imports any data contained in thedlquantizerobject that was collected at the command line. This data can include the network to quantize, calibration data, validation data, and calibration statistics.
The app displays a table containing the calibration data contained in the importeddlquantizerobject,quantObj. To the right of the table, the app displays histograms of the dynamic ranges of the parameters. The gray regions of the histograms indicate data that cannot be represented by the quantized representation. For more information on how to interpret these histograms, seeQuantization of Deep Neural Networks.

Related Examples
Parameters
Version History
Introduced in R2020aSee Also
Functions
You can also select a web site from the following list:
Americas
- América Latina(Español)
- Canada(English)
- United States(English)
Europe
- Belgium(English)
- Denmark(English)
- Deutschland(Deutsch)
- España(Español)
- Finland(English)
- France(Français)
- Ireland(English)
- Italia(Italiano)
- Luxembourg(English)
- Netherlands(English)
- Norway(English)
- Österreich(Deutsch)
- Portugal(English)
- Sweden(English)
- Switzerland
- United Kingdom(English)