可视化和评估分类器在分类学习者的表现
学习者训练分类器分类之后,可以比较模型基于精度值,显示结果通过绘制类预测,并检查性能使用混淆矩阵和ROC曲线。
如果你使用k倍交叉验证,那么应用程序计算使用的观测精度值k验证折叠和报告的平均交叉验证错误。这也使得预测这些验证折叠的观测和计算混淆矩阵根据这些预测和ROC曲线。
请注意
将数据导入到应用程序的时候,如果你接受默认值,应用自动使用交叉验证。欲了解更多,请看选择验证方案。
如果你坚持使用验证,应用计算中使用的观测精度值验证褶皱,使预测这些观察。应用程序还计算混淆矩阵和基于这些预测ROC曲线。
如果你使用resubstitution验证,比分是resubstitution精度基于训练数据,和预测resubstitution预测。
检查面板性能的模型
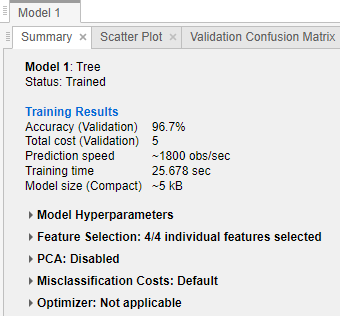
在分类学习者训练模型后,检查模型窗格中看到哪个模型的最佳百分比的整体精度。最好的准确性(验证)分数是强调在一个盒子里。这一点是验证精度。验证准确性分数估计模型的性能相比,新数据的训练数据。用分数来帮助你选择最好的模型。
交叉验证,分数在所有观测精度不安排测试,计算每个观测时抵抗(验证)褶皱。
坚持验证,比分是伸出的观测精度。
resubstitution验证,比分是resubstitution对所有训练数据观测精度。
最好的总分为你的目标可能不是最好的模型。稍微降低总体精度模型可能是最好的为你的目标分类器。例如,在特定类中假阳性的可能是对你很重要。您可能想要排除一些预测数据收集是昂贵或困难的。
找出每个类的分类器进行检查混淆矩阵。
视图模型指标在总结选项卡和模型面板中
您可以查看模型度量模型中总结选项卡,模型面板,使用指标来评估和比较模型。或者,您可以使用结果表标签比较模型。有关更多信息,请参见比较模型信息和结果在表视图中。
的培训结果指标计算验证集。测试结果计算指标,如果显示,进口测试集。更多信息,明白了评估测试集模型性能。
模型指标
| 度规 | 描述 | 提示 |
|---|---|---|
| 精度 | 比例的正确分类的观察 | 寻找更大的精度值。 |
| 总成本 | 误分类总成本 | 寻找小总成本值。确保精度值还大。 |
| 预测的速度 | 估计预测速度的新数据,根据预测时间验证数据集 | 后台进程内部和外部的应用程序可以影响这个估算,所以火车模型相似条件下更好的比较。 |
| 培训时间 | 培训时间模型 | 后台进程内部和外部的应用程序可以影响这个估算,所以火车模型相似条件下更好的比较。 |
| 模型尺寸(小型) | 模型的大小如果导出为一个紧凑的模型(也就是说,没有训练数据) | 寻找适合的模型尺寸值目标硬件应用程序的内存需求。 |
你可以排序模型模型窗格中根据精度或总成本。选择排序的度量模型,使用排序列表的顶部模型窗格。不是所有的指标可用于排序的模型窗格。你可以通过其他指标的排序模型结果表(见比较模型信息和结果在表视图中)。
您还可以删除不需要的模型中列出模型窗格。选择您要删除的模型并单击删除选定的模型按钮在右上角的窗格中,点击删除在模型部分的分类学习者选项卡,或右键单击并选择模型删除。你不能删除最后一个模型模型窗格。
比较模型信息和结果在表视图中
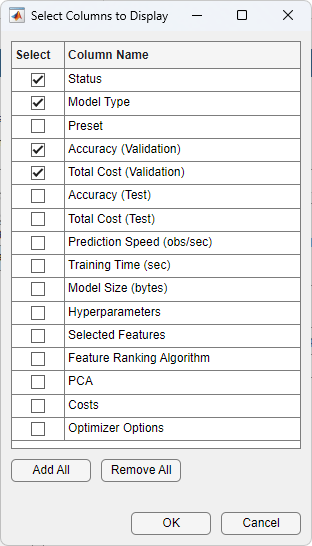
而不是使用总结选项卡或模型面板比较模型度量,您可以使用一个表的结果。在分类学习者选项卡,模型部分中,点击结果表。在结果表选项卡中,可以排序模型的训练和测试结果,以及他们的选择(如模型类型,选择特性,PCA,等等)。例如,验证模型的准确性进行排序,请单击排序箭头准确性(验证)列标题。向下箭头表示从最高精度模型分类精度最低。
查看更多表列选项,单击“选择列显示”按钮![]() 在桌子的右上角。在Select列显示对话框,检查框您想要显示的列在结果表中。新选中的列添加到右边的表。
在桌子的右上角。在Select列显示对话框,检查框您想要显示的列在结果表中。新选中的列添加到右边的表。
在结果表中,您可以手动拖拽表列,这样他们出现在你的优先顺序。
你可以收藏一些模型的使用最喜欢的列。应用程序不断的选择喜欢的模型结果表和之间的一致模型窗格。与其他列最喜欢的和型号从表中列不能被删除。
从表中删除一行,一行并单击右键单击任何条目隐藏的行(或隐藏选定行(s)如果行突出显示)。连续删除行,点击任何你想要的条目在第一行删除转变,然后单击任何条目在最后一行你想删除。然后,右键单击其中一个条目并单击突出显示隐藏选定行(s)。恢复删除所有行,右键单击任何表中的条目并单击显示所有行。恢复行附加表的底部。
出口信息表中,使用一个导出按钮![]() 在桌子的右上角。选择导出表工作区或一个文件中。导出的表只包含显示的行和列。
在桌子的右上角。选择导出表工作区或一个文件中。导出的表只包含显示的行和列。
情节分类器的结果
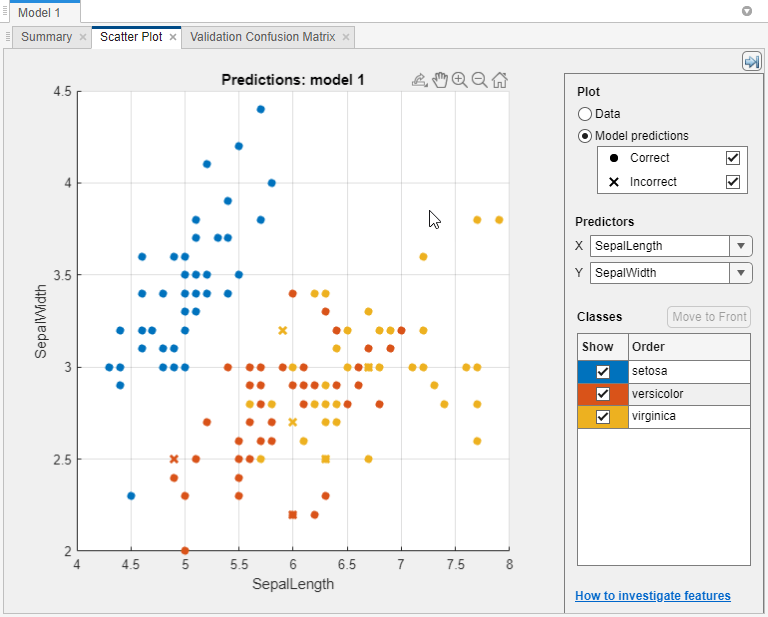
使用散点图来检查分类器的结果。视图的散点图模型,选择模型模型窗格。在分类学习者选项卡,情节和解释部分,单击箭头打开画廊,然后单击散射在验证结果组。你训练一个分类器后,散点图从显示的数据切换显示模型预测。如果您使用的是抵抗或交叉验证,那么这些预测是预测伸出(验证)的观察。换句话说,每个预测软件获得通过使用一个模型,训练没有相应的观察。
调查结果,使用右边的控件。您可以:
选择是否情节模型预测或单独的数据。
显示或隐藏使用复选框下正确的或不正确的结果模型的预测。
选择阴谋使用特性X和Y列表下预测。
可视化结果由显示或隐藏特定的类类使用复选框显示。
变化的叠加顺序绘制类通过选择下一个类类然后点击移到前面。
放大和缩小,或者锅整个阴谋。使缩放或移动,鼠标在散点图,然后单击工具栏上的相应按钮出现上图右上角的阴谋。
另请参阅调查在散点图特征。
出口数据的散点图您创建应用程序,看看出口情节分类学习者应用。
检查性能混淆矩阵中的每个类
使用混淆矩阵图来了解当前选中的分类器中执行每个类。你训练分类模型后,应用程序会自动打开的混淆矩阵模型。如果你训练一个“所有”模型,应用程序打开的混淆矩阵第一个模型。查看另一个模型的混淆矩阵,选择模型模型窗格。在分类学习者选项卡,情节和解释部分,单击箭头打开画廊,然后单击混淆矩阵(验证)在验证结果组。混淆矩阵可以帮助您识别分类器表现不佳的地区。
当你打开情节,行显示真正的类,列显示预测类。如果您使用的是维持或交叉验证,那么混淆矩阵计算使用预测伸出(验证)的观察。对角线细胞指出真正的类和预测类比赛。如果这些对角线细胞是蓝色的,正确分类器分类的观察这一事实类。
默认视图显示了每个细胞的观察。
看看每个类,分类器执行情节,选择真阳性比率(TPR),假阴性率(FNR)选择。TPR正确的比例分类观察每个真正的类。FNR是错误的比例分类观察每个真正的类。情节显示总结每个真正的类在过去两列在右边。
提示
寻找地区分类器通过检查细胞表现不佳的对角线显示高百分比和橙色。比例越高,细胞的暗色调的颜色。在这些橙色细胞,真正的阶级和预测类不匹配。更进一步的数据点。

在这个例子中,使用了carbig数据集,第五行从顶部显示所有日本汽车真正的类。列显示预测的类。从日本的汽车,77.2%是正确分类,77.2%正确分类的真阳性分在这个类中,蓝色的细胞所示TPR列。
日本行中的其他车辆分类错误的:5.1%的汽车是不正确归类为来自德国,5.1%被归类为来自瑞典,12.7%被归类为来自美国。错误分类的假阴性率点这类22.8%,橙色的细胞所示FNR列。
如果你想看多的观察(汽车,在这个例子中)而不是百分比,情节中,选择数量的观察。
如果假阳性是重要的在你的分类问题,每个预测类阴谋的结果(而不是真正的类)调查错误发现率。结果每个预测类,情节,选择阳性预测值(PPV),错误发现率(罗斯福)选择。PPV正确的比例分类观察每个预测类。罗斯福是错误分类的观察每个预测类的比例。选择这个选项,现在混淆矩阵包括以下表汇总行。阳性预测值蓝色所示正确预测点的每个类,和错误发现率橙色所示错误地预测点的每个类。
如果你决定是不是有太多点感兴趣的课,尝试改变分类器设置或特征选择寻找一个更好的模型。
出口的混淆矩阵块您创建应用程序的数据,看看出口情节分类学习者应用。
检查ROC曲线
接受者操作特征(ROC)曲线查看训练后一个模型。在情节和解释部分,单击箭头打开画廊,然后单击ROC曲线(验证)在验证结果组。这个应用程序创建一个通过使用ROC曲线rocmetrics函数。
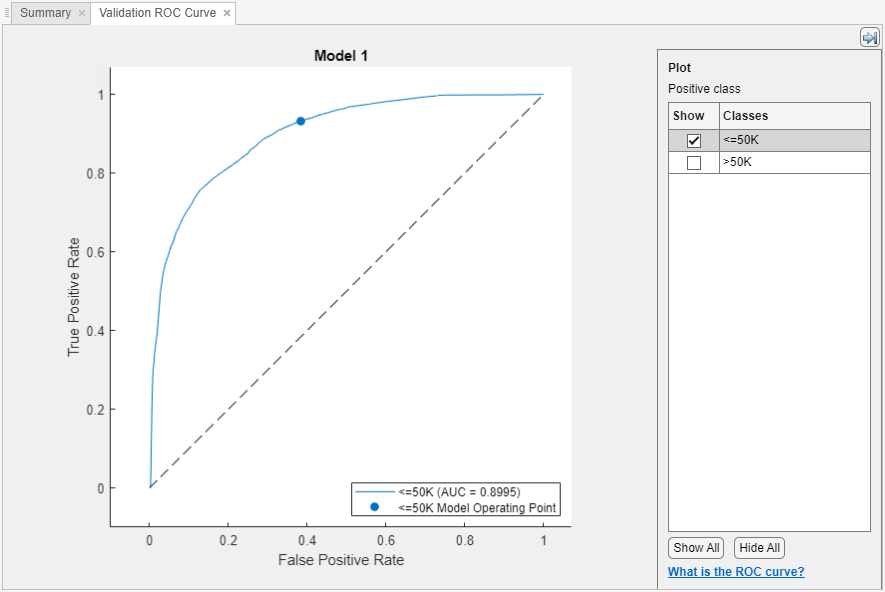
ROC曲线显示了真阳性率(TPR)和假阳性(玻璃钢)不同阈值的分类分数,计算当前选中的分类器。的模型操作点显示了假阳性率和真阳性率对应使用的阈值分类器分类一个观察。例如,假阳性的0.4表明,分类器错误分配40%的负类观察到正类。真阳性的0.9表明,正确分类器分配90%的积极类观测到积极类。
的AUC(曲线下面积)值对应于ROC曲线的积分(TPR值)对玻璃钢玻璃钢=0来玻璃钢=1。的AUC值是衡量分类器的整体质量。AUC值的范围0来1和更大的AUC值表明更好的分类性能。比较类和训练的模型,看看他们在ROC曲线表现不同。
您可以创建一个使用ROC曲线为一个特定的类显示复选框下情节。然而,你不需要检查ROC曲线为两类二元分类问题。两个ROC曲线对称,AUC值是相同的。一个类是一个真阴性率的TPR (TNR)其他类的,而且TNR 1-FPR。因此,TPR和玻璃钢的阴谋一个类是一样的一块1-FPR与1-TPR其他类。
多类分类器,应用程序制定一套one-versus-all二元分类问题有一个二进制的问题对于每一个类,并找到ROC曲线为每个使用对应的二进制类问题。每个二进制问题假定一个类是积极的,其余都是负面的。情节上的模型操作点显示了每个类的分类器的性能在其one-versus-all二进制的问题。
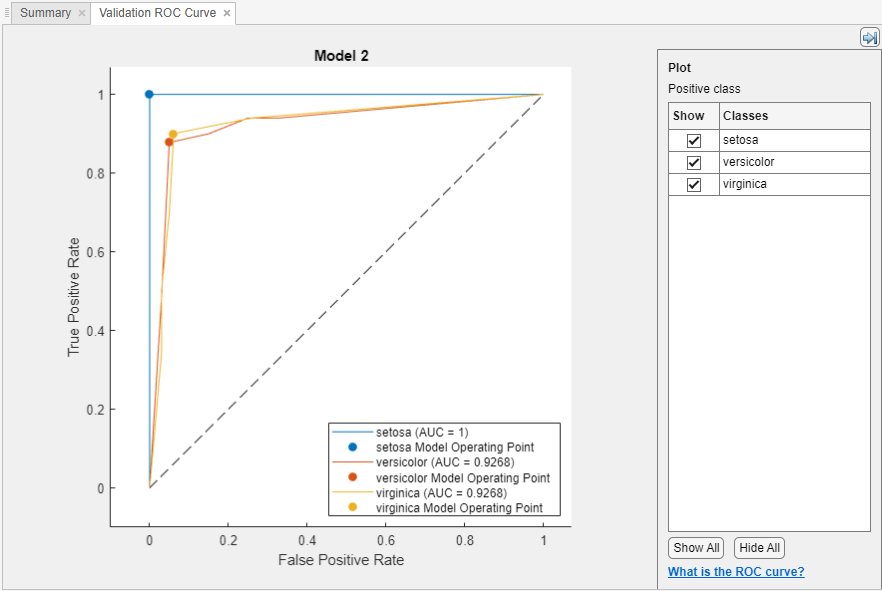
有关更多信息,请参见rocmetrics和ROC曲线和性能指标。
出口ROC曲线阴谋您在应用程序中创建的数据,看看出口情节分类学习者应用。
使用部分依赖情节解释模型
部分依赖情节(pdp)允许您可视化的边际效应预测的预测成绩训练分类模型。在火车模型分类学习者之后,您可以查看部分情节为模型的依赖。在分类学习者选项卡,情节和解释部分,单击箭头打开画廊。在解释结果部分中,点击部分依赖。计算部分依赖值时,应用程序使用最终的模型,完整的训练数据集(包括训练和验证数据,但不包括测试数据)。
调查结果,使用右边的控件。
下数据,选择是否使用阴谋的结果训练集数据或测试集数据。训练集是指训练最后的模型和使用的数据包括所有观测不用于测试。
下功能选择功能来使用X列表。情节的轴刻度线对应于独特的预测价值所选择的数据集。
如果你使用PCA模型训练,你可以选择的主成分X列表。
可视化类的预测成绩。情节中的每一行对应的平均预测评分在预测价值为一个特定的类。显示或隐藏绘制线通过检查或结算相应的显示框下类。通过点击相应的做一个策划线厚类下名字类。
放大和缩小,或者锅整个阴谋。使缩放或移动,把鼠标PDP并单击工具栏上的相应按钮出现上图右上角的阴谋。
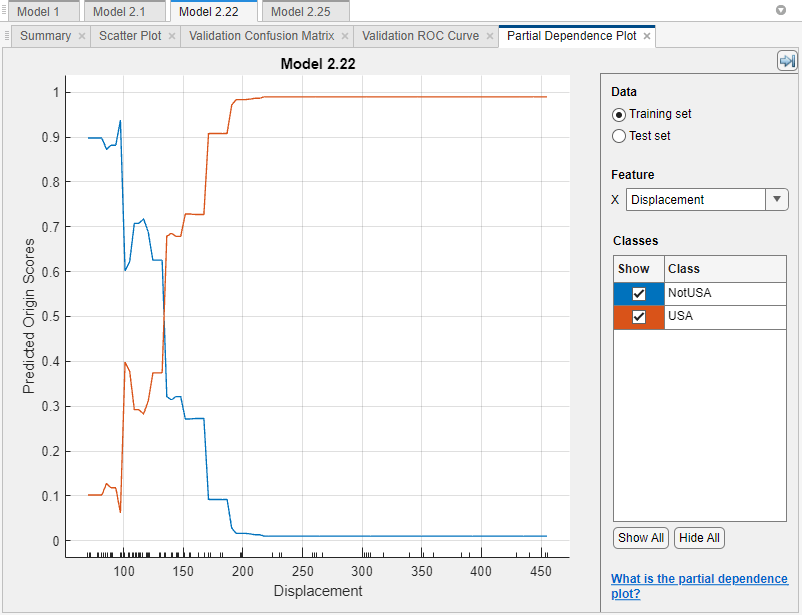
例如,看到的解释分类器训练分类学习者应用。部分依赖情节的更多信息,请参阅plotPartialDependence。
出口pdp您在应用程序中创建的数据,看看出口情节分类学习者应用。
情节比较模型通过改变布局
可视化的结果模型训练分类学习者通过使用中的情节选项情节和解释部分的分类学习者选项卡。你可以重新排列的布局图对比结果跨多个模型:使用的选项布局按钮,拖拽的阴谋,或选择选项提供的文档模型的行为向右箭头图选项卡。
例如,在分类学习者训练两个模型后,显示为每个模型和改变剧情情节布局比较土地使用其中的一个过程:
在情节和解释部分中,点击布局并选择比较模型。
单击第二个模型选项卡名称,然后拖拽向右第二个模型选项卡。
单击文档行为模型的最右边的箭头图选项卡。选择
瓷砖都选择并指定一个1×2布局。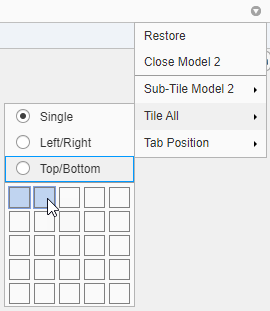

注意,您可以点击隐藏情节选项按钮![]() 在右上角的情节,使更多的空间情节。
在右上角的情节,使更多的空间情节。
评估测试集模型性能
在分类学习者训练模型后,你可以在一个测试评估模型的性能在应用程序中设置。这个过程允许您检查是否验证精度提供了一个很好的估计性能的新数据模型。
一组测试数据导入分类学习者。另外,储备一些数据测试时将数据导入到应用程序(请参阅(可选)储备数据进行测试)。
如果测试数据集在MATLAB®工作空间,然后在测试上节分类学习者选项卡上,单击测试数据并选择从工作空间。
如果测试数据集在一个文件中,然后在测试部分中,点击测试数据并选择从文件。选择一个文件类型列表中,如电子表格、文本文件,或逗号分隔值(
. csv)文件,或选择所有文件浏览其他文件类型等.dat。
在导入测试数据对话框中,选择的测试数据集测试数据设置变量列表。测试设置必须具有相同的变量作为训练和验证预测进口。独特的测试响应变量中的值必须在完整的一个子集类响应变量。
计算测试集的度量标准。
计算测试指标为一个模型,选择训练模式模型窗格。在分类学习者选项卡,测试部分中,点击测试所有并选择测试选择。
为所有训练模型计算测试指标,点击测试所有并选择测试所有在测试部分。
每个模型的应用计算测试集性能完整的训练数据集,包括培训和验证数据(但不包括测试数据)。
比较验证的准确性和测试精度。
在模型中总结选项卡中,应用程序显示验证指标和测试指标培训结果节和测试结果部分,分别。你可以检查是否验证精度很好估计测试精度。
你也可以想象使用情节的测试结果。
显示一个混淆矩阵。在情节和解释上节分类学习者选项卡中,单击箭头打开画廊,然后单击混淆矩阵(测试)在测试结果组。
显示一个ROC曲线。在情节和解释部分,单击箭头打开画廊,然后单击ROC曲线(测试)在测试结果组。
例如,看到的检查使用测试集分类器性能分类学习者应用。为例,利用测试集指标hyperparameter优化工作流程,明白了训练分类器在分类学习者使用Hyperparameter优化应用程序。