机器学习模型的Shapley值
本主题定义了Shapley值,描述了统计和机器学习工具箱™中计算Shapley值的两种可用算法,提供了每种算法的示例,并展示了如何降低计算成本。
沙普利值是什么?
在博弈论中,参与者的沙普利值是合作博弈中参与者的平均边际贡献。也就是说,沙普利值是一个合作游戏中产生的全部收益对个体玩家的公平分配。在机器学习预测的上下文中,查询点的特征的Shapley值解释了该特征在指定查询点对预测的贡献(回归的响应或分类的每个类的得分)。Shapley值对应于查询点的预测与平均预测之间的偏差,这是由于特征造成的。对于每个查询点,所有特征的Shapley值之和对应于预测与平均值的总偏差。
的Shapley值我查询点的特征x是由值函数定义的v:
| (1) |
米是所有特征的个数。
是所有特征的集合。
|年代|集合的基数是多少年代,或集合中元素的数量年代.
vx(年代)是集合中特征的值函数吗年代对于查询点x.该函数的值表明了中特征的预期贡献年代到查询点的预测x.
沙普利价值统计和机器学习工具箱
计算机器学习模型的Shapley值沙普利对象。使用这些值来解释模型中各个特征对查询点预测的贡献。你可以用两种方法计算Shapley值:
算法
沙普利提供两种类型的算法:对值函数使用干涉分布的介入算法和对值函数使用条件分布的条件算法。属性指定要使用的算法类型方法的名称-值参数沙普利函数或适合函数。
这两种算法的区别在于值函数的定义。这两种类型都定义了值函数,以便查询点对所有特征的Shapley值的和对应于查询点的预测与平均值的总偏差。
因此,值函数vx(年代)必须与中特征的预期贡献相对应年代对于预测(f)作为查询点x.该算法利用从指定数据中创建的人工样本(X).你必须提供X通过机器学习模型输入或单独的数据输入参数时创建一个沙普利对象。在人工样本中,特征值为年代来自查询点。对于其余的功能(功能在年代c,的补年代),介入性算法使用介入性分布生成样本,而条件算法使用条件分布生成样本。
介入算法
默认情况下,沙普利使用这些介入算法之一:内核SHAP[1],线性SHAP[1],或Tree SHAP[2].
计算精确的沙普利值在计算上是昂贵的,如果沙普利使用所有可能的子集年代.因此,沙普利通过限制用于内核SHAP算法的子集的最大数量来估计Shapley值。详情请参见计算成本.
对于线性模型和树形模型,沙普利分别提供了线性SHAP和树形SHAP算法。这些算法的计算成本更低,并计算精确的沙普利值。这些算法返回的Shapley值与内核SHAP算法在使用所有可能的子集时返回的相同。线性SHAP和树形SHAP算法与核形SHAP算法在以下方面有所不同:
线性SHAP和树形SHAP算法忽略
ResponseTransform属性(用于回归)和ScoreTransform机器学习模型的属性(用于分类)。也就是说,算法基于原始响应或原始分数计算Shapley值,而不分别应用响应转换或分数转换。类型中的转换,则内核SHAP算法使用转换后的值ResponseTransform或ScoreTransform财产。内核SHAP算法使用带有缺失值的观测数据作为树模型和树学习器的集成模型。线性SHAP和树形SHAP算法不能处理任何模型中缺失值的观测值。
沙普利根据机器学习模型类型和其他指定选项选择算法:
线性模型的线性SHAP算法:
用于这些树模型和带树学习器的集成模型的树SHAP算法:
〇树木模型
RegressionTree,CompactRegressionTree,ClassificationTree,CompactClassificationTree具有树学习器的集成模型-
RegressionEnsemble,RegressionBaggedEnsemble,CompactRegressionEnsemble,ClassificationEnsemble,CompactClassificationEnsemble,ClassificationBaggedEnsemble使用树学习器的模型要使用Tree SHAP算法,必须指定
方法名称-值参数(集成聚合方法)为“包”,“AdaBoostM2”,“GentleBoost”,“LogitBoost”,或“RUSBoost”训练分类集成模型时。
内核SHAP算法适用于所有其他模型类型和以下情况:
如果输入预测器数据中的观察值或查询点中的值包含缺失值,则该软件使用内核SHAP。
如果您指定
MaxNumSubsets的name-value参数(用于Shapley值计算的预测器子集的最大数量)沙普利或适合,软件采用内核SHAP。在某些情况下,内核SHAP在计算上比树SHAP更便宜。例如,如果模型包含用于低维数据的深度树,则内核SHAP可以更有效。该软件启发式地选择了一种有效的算法。
一种介入算法定义特征的值函数年代在查询点x对于介入性分布的预期预测D,即特征的联合分布年代c:
x年代中功能的查询点值是年代,X年代c有哪些特点年代c.
求值函数的值vx(年代)在查询点x,假设特征不是高度相关的,沙普利使用数据中的值X作为样本的介入性分布D中的功能年代c:
N是观察数,和(X年代c)j中特性的值年代c为j观察。
例如,假设您有三个特性X并有四点观察:(x11,x12,x13), (x21,x22,x23), (x31,x32,x33),及(x41,x42,x43).假设年代包括第一个特性和年代c包括其他的。在这种情况下,在查询点评估的第一个特征的值函数(x41,x42,x43)是
介入性算法的计算成本比条件算法低,并支持有序分类预测器。万博1manbetx然而,干涉算法需要特征独立假设,并使用分布外样本[4].混合查询点和数据创建的人工样本X可能包含不切实际的观察。例如,(x41,x12,x13)可能是一个在三个特征的完全联合分布中不出现的样本。
有条件的算法
指定方法名称-值参数为“条件”使用内核SHAP算法的扩展[3],这是一个条件算法。
条件算法定义特征的值函数年代在查询点x的条件分布X年代c,考虑到X年代具有查询点值:
求值函数的值vx(年代)在查询点x,沙普利使用查询点的最近邻居,这些邻居对应于数据中10%的观测值X.该方法使用了比介入算法更真实的样本,并且不需要特征独立性假设。然而,条件算法在计算上更昂贵,不支持有序分类预测器,并且无法处理万博1manbetx南S在连续特征中。此外,如果虚拟特征与重要特征相关,该算法可能会将非零Shapley值分配给虚拟特征,这对预测没有贡献[4].
指定计算算法
本例训练线性分类模型,并使用介入算法计算Shapley值(“方法”、“介入”),然后是条件算法(“方法”,“条件”).
列车线性分类模型
加载电离层数据集。该数据集有34个预测器和351个雷达返回的二进制响应,要么是坏的(“b”)或好(‘g’).
负载电离层
训练一个线性分类模型。为提高线性系数的准确性,请指定目标函数最小化技术(“规划求解”作为有限内存Broyden-Fletcher-Goldfarb-Shanno准牛顿算法(“lbfgs”).
Mdl =直线(X,Y,“规划求解”,“lbfgs”)
Mdl = ClassificationLinear ResponseName: 'Y' ClassNames: {'b' 'g'} ScoreTransform: 'none' Beta: [34x1 double]偏差:-3.7100 Lambda: 0.0028学习者:'svm'属性,方法
用干涉算法计算Shapley值
使用线性SHAP算法计算第一次观测的Shapley值,这是一种干涉算法。您不必指定方法名称-值参数“介入”是默认值。
queryPoint = X(1,:);explainer1 = shapley(Mdl,X,“QueryPoint”, queryPoint);
对于分类模型,沙普利使用每个班级的预测分数计算沙普利值。方法绘制预测类的Shapley值情节函数。
情节(explainer1)
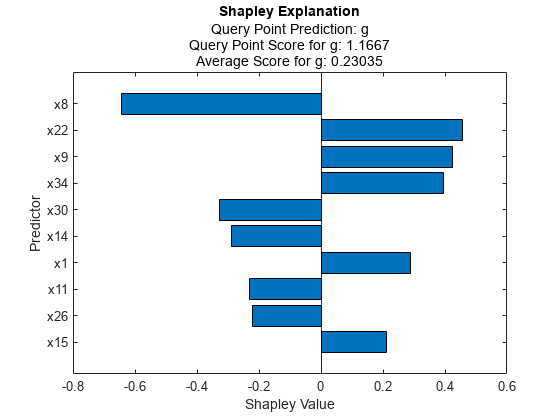
横柱图显示了10个最重要变量的Shapley值,按绝对值排序。每个值都解释了查询点的分数与预测班级的平均分之间的偏差,这是由于相应的变量造成的。
对于线性模型,沙普利假设特征是相互独立的,并从估计的系数(Mdl。β)[1].计算正类(中的第二个类)的Shapley值Mdl。一会,‘g’)直接从估计的系数。
线性shapvalues = (Mdl.Beta'.*(queryPoint-mean(X)))';
创建一个包含Shapley值的表沙普利系数的值。
t = table(explainer1.ShapleyValues.Predictor,explainer1.ShapleyValues.g,linearSHAPValues,...“VariableNames”, {“预测”,“来自shapley的价值观”,“系数值”})
t =34×3表预测值来自shapley值来自系数_________ ___________________ ________________________“x1”0.28789 0.28789“x2”00“x3”0.20822 0.20822“x4”-0.01998 -0.01998“x5”0.20872 0.20872“x6”-0.076991 -0.076991“x7”0.19188 0.19188“x8”-0.64386 -0.64386“x9”0.42348 0.42348“x10”-0.030049 -0.030049“x11”-0.23132 -0.23132“x12”0.1422 0.1422“x13”-0.045973 -0.29022“x15”0.21051“x16”0.13382
使用条件算法计算Shapley值
使用内核SHAP算法的扩展计算第一次观测的Shapley值,这是一种条件算法。
explainer2 = shapley(Mdl,X,“QueryPoint”queryPoint,“方法”,“条件”);
绘制Shapley值。
情节(explainer2)
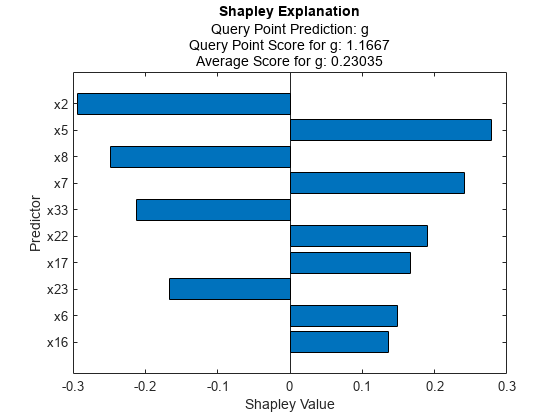
这两种算法为10个最重要的变量确定了不同的集合。只有两个变量,的混合体而且将,都包含在这两个集合中。
计算成本
如果观测值或特征的数量很大,沙普利值的计算成本会增加。
大量的观察
计算值函数(v)如果你有大量的观测,例如超过1000个,那么计算成本就会很高。为加快计算速度,在创建沙普利对象,或通过指定并行运行UseParallel作为真正的方法计算值时沙普利或适合函数。的UseParallel选项在以下情况下可用沙普利使用Tree SHAP算法进行树的集成、内核SHAP算法或内核SHAP算法的扩展。并行计算需要并行计算工具箱™。
大量功能
计算和方程1对于所有可能的子集年代什么时候会计算昂贵米(特征的数量)对于内核SHAP算法或内核SHAP算法的扩展来说是很大的。要考虑的子集总数为2米.属性指定子集的最大数目,而不是计算所有子集的总和MaxNumSubsets名称-值参数。沙普利根据子集的权重值选择要使用的子集。子集的权重正比于1/(总和的分母),这对应于1除以二项式系数:
.因此,具有高或低基数值的子集具有较大的权重值。沙普利首先包含权重最高的子集,然后根据权重值降序包含其他子集。
降低计算成本
这个例子展示了当你有大量的观测值和特征时,如何减少沙普利值的计算成本。
加载示例数据集NYCHousing2015.
负载NYCHousing2015
该数据集包括对10个变量的91446个观测值,这些变量包含2015年纽约市房产销售信息。本例使用这些变量来分析销售价格(SALEPRICE).
预处理数据集。转换datetime阵列(SALEDATE)至月份数字。
NYCHousing2015。SALEDATE=month(NYCHousing2015.SALEDATE);
训练神经网络回归模型。
Mdl = fitrnet(NYCHousing2015,“SALEPRICE”,“标准化”,真正的);
计算第一次观测中所有预测变量的Shapley值。通过使用来测量计算所需的时间抽搐而且toc.
tic explainer1 = shapley(Mdl;“QueryPoint”NYCHousing2015 (:));
警告:由于预测器数据有超过1000个观测值,计算可能会很慢。使用更小的训练集样本或指定“UseParallel”为true,以实现更快的计算。
toc
运行时间为150.637868秒。
正如警告消息所示,由于预测器数据有超过1000个观测值,计算可能会很慢。
沙普利当你有大量的观察或特征时,提供几个选项来减少计算成本:
大量的观察-使用较小的训练数据样本,并通过指定并行运行
UseParallel作为真正的.大量的特性-指定
MaxNumSubsets参数来限制计算中包含的子集的数量。
启动并行池。
parpool;
使用'Processes'配置文件启动并行池(parpool)…与6名工人连接到平行水池。
再次使用较小的训练数据样本和并行计算选项计算Shapley值。另外,将子集的最大数量指定为2 ^ 5.
NumSamples = 5e2;Tbl = datasample(NYCHousing2015,NumSamples,“替换”、假);tic explainer2 = shapley(Mdl,Tbl;“QueryPoint”NYCHousing2015 (1:)...“UseParallel”,真的,“MaxNumSubsets”、2 ^ 5);toc
运行时间为0.844226秒。
指定额外的选项可以减少计算时间。
参考文献
[4]库马尔,I.伊丽莎白,苏雷什·文卡萨布拉曼尼亚,卡洛斯·沙伊德格和索雷尔·弗莱德勒。“Shapley-Value-Based解释作为特征重要性度量的问题”第37届国际机器学习会议论文集119(2020年7月):5491-500。
另请参阅
相关的话题
您也可以从以下列表中选择一个网站: