状态空间,第4部分:什么是LQR控制?
从系列:状态空间
布莱恩•道格拉斯
LQR是一种基于状态空间表示的最优控制。在这段视频中,我们在一个非常高的水平引入这个话题,让你与控制问题的理解走开,当你正在研究它背后的数学可以建立这样的认识。此段视频将涵盖这意味着什么是最佳的,如何去想LQR问题。最后,我会告诉你在MATLAB一些例子®这将帮助你获得关于LQR一点直觉。
我们来谈谈线性二次型调节器,或者叫LQR控制。LQR是一种基于状态空间表示的最优控制。在这段视频中,我想要在一个非常高的层次上介绍这个主题,这样你们就可以对控制问题有一个大致的理解,并且可以在学习它背后的数学知识时建立在这个理解上。我会讲到什么是最优的,如何考虑LQR问题,然后我会给你们展示一些MATLAB中的例子,我想这些例子会帮助你们对LQR有一些直观的认识。我是Brian,欢迎来到MATLAB技术讲座。
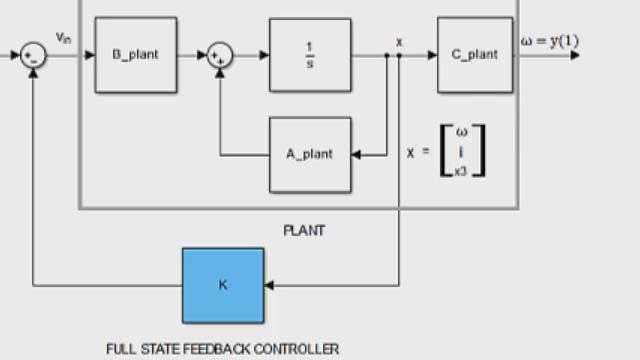
首先,我们来比较一下我们在第二段视频中介绍的极点配置控制器和LQR控制器的结构。这样你就能知道它们有什么不同。通过极点配置,我们发现,如果我们反馈状态向量中的每个状态,并将它们乘以增益矩阵K,我们就有能力将闭环极点放在我们选择的任何地方,假设系统是可控和可观察的。然后我们缩放参考项以确保没有稳态参考跟踪误差。
的LQR结构,另一方面,进料从缩放的参考备份充满状态向量,然后由增益矩阵K相乘,并减去它。所以,你可以看到,这两个控制法的结构是完全差异 - 当然,实际上,不,他们是完全一样的。他们都是全状态反馈控制器,我们可以实现与来自LQR和极点相同结构的结果。
关于这个结构的一个简短说明:我们可以设置它来反馈输出的积分,或者我们可以将增益应用到状态错误。这三种实现都可以产生零稳态误差,并且可以与极点配置或LQR的结果一起使用。如果你想了解更多关于其他两个反馈结构的信息,我在描述中留下了一个很好的资源。
好吧,我们回来了。那么,如果这两个控制器是以完全相同的方式实现的,为什么要给它们起不同的名字呢?这是钥匙。实现是一样的,但是选择K的方式不同。
随着极点,我们通过选择我们想要把闭环极点解决在K。我们希望地点他们在一个特定的地点。这是太棒了!但是这种方法的一个问题是要找出闭环极点的合适位置。对于高阶系统和具有多个执行器的系统,这可能不是一个非常直观的答案。
所以对于LQR,我们不选择极点位置。我们通过选择对我们很重要的闭环特性来找到最优的K矩阵——具体来说,就是系统的性能有多好,以及达到这个性能需要付出多少努力。这句话可能没有太大的意义,所以让我们来做一个快速思考练习,我认为它会有帮助。
我从Christopher Lum那里借用并修改了这个例子,他有一个关于LQR的视频,如果你想更深入地解释数学的话,这个视频值得一看。我已经在描述中链接到他的视频。但这里的大意是:
假设你正试图找出从家里去上班的最佳或最优方式。你有几种交通工具可供选择。你可以开你的车,你可以骑你的自行车,坐公共汽车,或者租一架直升飞机。问题是,哪一个是最优选择?这个问题本身是无法回答的,因为我还没有告诉你一个好的结果意味着什么。所有这些选择都可以让我们从家里去上班,但它们的作用是不同的,我们需要弄清楚什么对我们来说是重要的。如果我说时间是最重要的,要尽快开始工作,那么最优的解决方案就是坐直升机。另一方面,如果我说你没有太多的钱,而且上班尽可能的便宜是一个好的结果,那么骑自行车就是最佳的解决方案。
当然,在现实生活中,你没有无限的金钱来最大化你的表现,你也没有无限的时间来最小化你的花费,但是你需要在两者之间找到一个平衡点。所以你可能会说你要提前开会,所以珍惜上班的时间,但你不是一个独立的有钱人,所以你关心花了多少钱。因此,最佳的解决方案是坐你的车或乘公共汽车。
现在,如果我们想要一个奇特的方式来评估数学其中运输方式是最优的,我们可以建立一个函数是加在一起旅行时间和金钱,每个选项获取量。然后,我们可以用一个乘数设定的时间与金钱的重要性。我们将加权每个根据自己的个人喜好这些矩阵。我们称这个成本函数,或目标函数,你可以看到它很大程度上受到这些权重参数的影响。如果Q是高的,那么我们就惩罚需要更多时间的选择,如果R为高,那么我们就惩罚是花了很多钱选项。一旦我们设定的权重,计算每个选项的总成本,选择具有综合成本最低的一个。这是最佳的解决方案。
有趣的是,根据绩效和支出的相对权重,有不同的最佳解决方案。万博 尤文图斯没有通用的最优解决方案,只有满足用户需求的最佳解决方案。CEO可能会坐直升机,而大学生可能会骑自行车,但考虑到他们的偏好,两者都是最佳选择。
这和我们设计控制系统时的推理是完全一样的。我们不需要考虑极点位置,我们可以考虑和评估什么对我们来说是重要的,在系统性能和我们想要花费多少来获得性能之间。当然,通常我们想花多少钱不是用美元来衡量的,而是用执行机构的努力,或它所需要的能量来衡量的。
这是LQR如何处理找到最佳增益矩阵。我们建立了一个成本函数,增加了性能和精力总时间的加权和,然后通过解决LQR问题,它返回生产给出了系统的动态成本最低的增益矩阵。
现在我们在LQR中使用的成本函数看起来和我们在旅行例子中开发的函数有点不同,但是概念是完全相同的;我们通过调整Q来惩罚糟糕的性能,我们通过调整R来惩罚执行器的努力。
因此,让我们看看都有哪些表现手段这一成本函数。性能,判断在状态向量。现在,让我们假设我们希望每一个国家为零,被驱动回到其初始平衡点。因此,如果系统在一些非零状态初始化,速度越快它返回到零,表现较好的是和降低成本。而且,我们可以得到它是如何迅速恢复到理想状态的量度的方法是通过查看曲线下面积。这是整体在做什么。与它花费更多的时间更接近球门比多区域的曲线更小的面积意味着曲线。
然而,状态可以是消极或积极的,我们不希望从总成本减去负值,所以我们的平方值,以确保它是积极的。这有惩罚更大的误差不成比例比较小的多的效果,但它是一个很好的折衷,因为它把我们的成本函数为二次函数。二次函数,像Z = X ^ 2 + Y ^ 2凸出,并且因此,有一个明确的最小值。和二次函数受线性动态保持二次所以我们的系统也将有一个明确的最小值。
最后,我们希望能够衡量每个状态的相对重要性。因此,Q不是一个单一的数,而是一个方阵它的行数与状态数相同。Q矩阵必须是正定的,这样当我们将它与状态向量相乘时,结果值为正且非零。通常它只是一个对角线上值为正的对角矩阵。有了这个矩阵,我们可以通过使Q矩阵中相应的值变得非常大来确定我们想要的低误差的状态,而那些我们不太关心的状态会使这些值变得非常小。
成本函数的另一半加起来驱动的成本。在一个非常相似的方式,我们来看看输入向量,我们方的条款,以确保他们是积极的,然后进行加权与沿其对角线积极乘数R矩阵。
我们可以在更大的矩阵形式如下写这篇文章,虽然你不经常看到这样写的成本函数,它帮助我们想象的东西。Q和R是这个更大的加权矩阵的一部分,但是这个矩阵的非对角线项为零。我们可以用N那些弯道补,使得整个矩阵仍然正定但现在N矩阵惩罚的输入和状态的交叉产品。s manbetx 845虽然是设置你的成本函数与N矩阵,对我们来说,我们要保持简单,只是将其设置为零,只注重Q和R.用途
因此,通过设置Q和R的值,我们现在有一个指定究竟什么是对我们非常重要。如果致动器之一是真贵,我们正在努力节约能源,那么我们通过增加R矩阵值与之相对应予以处罚。如果你是因为他们使用了燃料,这是一种有限的资源利用卫星控制的推进器,这可能是这种情况。在这种情况下,您可以接受较慢的反应或多个状态的错误,这样就可以节省燃料。
在另一方面,如果性能是至关重要真的,那么我们可以通过增加与美国相当于我们关心的Q矩阵值惩罚状态错误。使用反作用轮时对卫星的控制,因为他们使用的是可以存储在电池与太阳能电池板补充能量,这可能是这种情况。因此,使用更多的能量低,差错控制可能是一个很好的权衡。
现在的大问题是:我们如何解决这个优化问题?而最令人失望的答案是,推导这个解超出了本视频的范围。但是我在描述中留下了一个很好的链接,如果你想仔细阅读的话。
The good news, however, is that as a control system designer, often the way you approach LQR design is not by solving the optimization problem by hand, but by developing a linear model of your system dynamics, then specifying what’s important by adjusting the Q and R weighting matrices, then running the LQR command in MATLAB to solve the optimization problem and return the optimal gain set, and then just simulate the system and adjust Q and R again if necessary. So as long as you understand how Q and R affects the closed-loop behavior, how they punish state errors and actuator effort, and you understand that this is a quadratic optimization problem, then it’s relatively simple to use the LQR command in MATLAB to find the optimal gain set.
有了LQR,我们把设计的问题从我们把极点放在哪里,转移到问题上,我们如何设置Q和r。不幸的是,没有一种一刀切的方法来选择这些权重;然而,我认为设定Q和R比选择极点位置更直观。例如,你可以从Q和R的单位矩阵开始,然后通过尝试、错误和对系统的直觉来调整它们。为了帮助你们建立一些直觉,让我们来看看MATLAB中的一些例子。
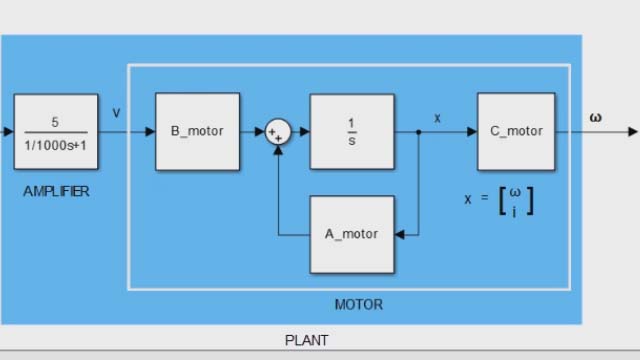
好吧,这需要解释一下。让我们从代码开始。我有一个在无摩擦环境下旋转质量的简单模型系统有两种状态,角度和角速度。我正在设计一个全状态反馈控制器使用LQR,它真的不能再简单了。我将从Q的单位矩阵开始,其中第一个对角元素与角误差有关,第二个元素与角速率有关。该系统只有一个驱动输入,即四个旋转推进器,它们共同作用来创建单个扭矩指令。因此,R只是一个值。
现在,我使用LQR命令求解最优反馈增益,并构建一个表示闭环动态的状态空间对象。通过设计控制器,我可以模拟对初始条件的响应,我将初始条件设置为3弧度。差不多就是这样。这个脚本中的其他所有东西都只是让这个复杂的情节更容易理解结果。
好的,让我们运行这个脚本。你可以看到UFO被初始化为3弧度。在最上面,我记录了机动需要多长时间这代表了性能,以及完成机动需要多少燃料。让我们开始,看看控制器做得有多好。
看那个,它完成了5.8秒的机动燃料的15个单位,并获得在这个过程中,这是重要的组成部分奶牛。当推进器是活动的,它们产生随时间加速UFO的转矩。因此,燃料的使用与加速度成正比的积分。所以我们越是加快,则使用更多的燃料。
现在让我们看看我们是否可以用更少的燃料来做这个机动通过更多的惩罚推进器。我将使R增加到2并重新运行模拟。
我们少用了2个单位的燃料,但是多花了3秒。问题是,这个组合,它超出了目标一点点,不得不浪费时间回来。所以让我们试着放慢最大旋转速度,希望它不会超调。我们要通过惩罚Q矩阵的角速率部分来实现。现在,任何非零利率的成本都是以前的两倍。让我们试一试。
好了,我们节省大约一秒钟,因为它没有超调,并且在这个过程中成功地收工燃料的另一个单元。好了,够了这个小东西。现在,让真的节省燃料通过放松角度误差权重一堆。
好了,现在进展很慢了。我来加快视频的速度。最后,我们用了5个单位的燃料,不到以前的一半。我们也可以用另一种方法来调节一个非常主动的控制器。
是的,就是要快得多。小于2秒,我们的加速是关闭的图表。这就是你如何旋转拿起一头牛。不幸的是,在近100份燃料的费用,所以双方是下降到了一切。好了,所以希望,你开始看到我们如何能够通过调整这两个矩阵调整和优化我们的控制器。它很简单。
现在,我知道这个视频被拖延,但有不同的剧本我想告诉你一件事真快,这就是LQR如何比极点配置更加强大。在这里,我有一个不同的状态空间模型,它有三种状态和一个执行机构。我定义我的Q和R矩阵和解决的最佳增益。和以前一样,我会产生闭环状态空间模型,然后运行到1,0,0的初始条件的响应,那么我绘制第一状态的响应,从1返回到0的是步骤;执行机构的努力;和闭环极点和零点的位置。
让我们运行一下,看看会发生什么。第一个状态很好地回到了0,但代价是很多的驱动。我没有做任何特别的模型但是假设执行器需要推力。所以这个控制器需要10单位的推力。然而,假设我们的推进器只能产生2个单位的推力。这个控制器的设计会使推进器饱和我们得不到我们想要的响应。现在,如果我们用极点配置来开发这个控制器,此时的问题是为了减少执行器的工作,我们应该移动这三个极点中的哪一个?这不是很直观,对吧?
但随着LQR,我们可以很方便地找到R矩阵,并通过提高单个值惩罚执行器的使用。我会重新运行该脚本。我们看到,响应速度慢,符合市场预期,但该驱动器不再饱和。而且,检查了这一点,如果我们使用极点配置与R.所以这个单一调整移动所有三个闭环极点,我们将不得不知道,以减少执行机构努力将这些电线杆就这样。这将是非常艰难的。
所以这就是我要离开这个视频。LQR控制是非常强大的,希望你看到它是简单的设置和比较直观调整和调整。而最好的部分是,它返回基于你怎么体重性能和精力的最佳增益矩阵。所以,这取决于你如何你想你的系统到底表现。
如果你不想错过下一个科技视频,不要忘记订阅这个频道。另外,如果你想看看我的频道,控制系统讲座,我也会讲到更多的控制理论话题。谢谢收看。下次见。