统计和机器学习工具箱
统计と机械学习を使用してデータを分析およびモデル化
统计和机器学习工具箱™には,データを记述,解析,およびモデル化する关数やアプリが用意されています。记述统计および探索的データ解析のためのプロットを使用したり,确率分布をデータに近似したり,モンテカルロシミュレーションのために乱数を生成できるほか,仮说検定を行うことも可能です。回帰および分类アルゴリズムにより,データから推定を行い,予测モデルを作成できます。
また,多次元データの解析については,统计和机器学习工具箱では特徴选択,ステップワイズ回帰,主成分分析(PCA),正则化およびその他の次元削减方法が提供されており,モデルに影响を与える変数または特徴の特定が可能です。
このツールボックスは,SVM(サポートベクターマシン),ブースティングされた决定木とバギングされた决定木中,k近傍中,k平均,K -medoid法,阶层クラスタリング,混合ガウスモデルおよび隠れマルコフモデルを含む教师ありおよび教师なしの机械学习アルゴリズムを提供します。多くの统计手法および机械学习アルゴリズムは,メモリに收まりきらない大きなデータセットの计算に使用できます。
详细を见る:

可视化
确率プロット,箱ひげ図,ヒストグラム,Q-Qプロット,および多変量分析用の高度なプロット(树状図,バイプロット,アンドリュースプロットなど)を使用してデータを视覚的に探索します。

多次元散布図を使用して,変数间の关系を検讨
记述统计
いくつかの关连性の高い変数を用いると,大规模なデータセットであっても,すばやく理解して记述することができます。

グループ化された平均と分散を使用してデータを探索
クラスター分析
ķ平均法,K-中心点划分法,DBSCAN,阶层クラスタリング,混合ガウスおよび隠れマルコフモデルを使用してデータをグループ化し,パターンを见つけます。

2つの同心円グループにDBSCANを適用
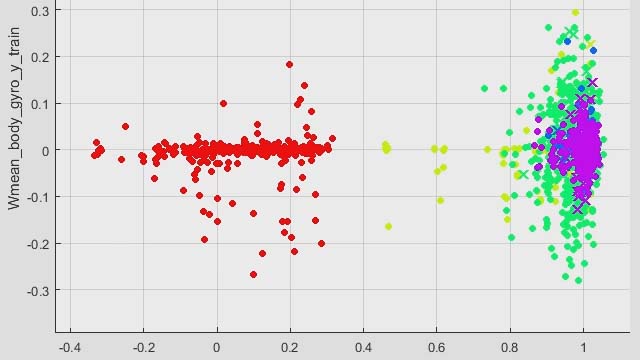
特徴抽出
スパースフィルタリングや再构成型独立成分分析(RICA)などの教师なしの学习技术を使用して,データから特徴量を抽出します。専门的な手法を使用して,画像,信号,テキスト,および数値データから特徴量を抽出することもできます。

モバイル端末から提供された信号から特徴量を抽出
特徴选択
データのモデル化において,予测精度を最大限に高める特徴量の部分集合を自动的に特定します。特徴选択手法には,ステップワイズ回帰,逐次特徴选択,正则化,およびアンサンブル法などがあります。

NCAは,モデルの精度を保持する特徴量を选択するのに役立つ
特徴変换および次元削减
既存の(非カテゴリカル)特徴量を新しい予测子変数に変换して次元削减を行うと,记述力の小さい特徴量を落とすことができます。特徴量変换手法には,PCA,因子分析,非负値行列因子分解などがあります。

PCAは多変量データを,その情报の大部分を保持しながら,より低次元の直交座标系にそのデータを射影する。
予测モデルの学习,検证,调整
さまざまな机械学习アルゴリズムの比较,特徴量の选択,ハイパーパラメーターの调整,予测性能の评価を行います。
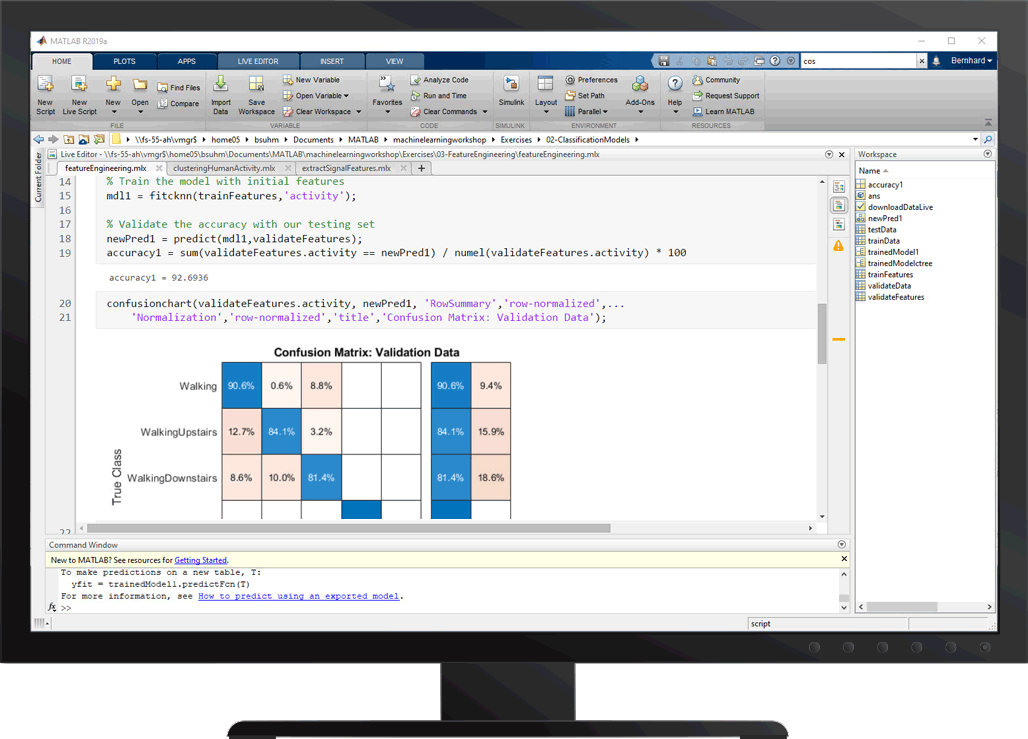
分类
カテゴリカルな応答変数を1つ以上の予测子の关数としてモデル化します。さまざまなパラメトリックおよびノンパラメトリックの分类アルゴリズム(ロジスティック回帰,SVM,ブースティングされた决定木とバギングされた决定木,単纯ベイズ,判别分析,K近傍法など)を使用します。

分类学习器アプリで対话的に分类器の学习を実行
モデルの自动最适化
モデルの精度を高めるには,ハイパーパラメーターを自动的に调整し,特徴量を选択して,データセットの不均衡をコストマトリックスで対处します

ベイズ最适化を使用してハイパーパラメーターを效率的に最适化
线形回帰および非线形回帰
多数の线形または非线形回帰アルゴリズムから选択して,复数の予测子または応答変数を持つ复雑なシステムの动作をモデル化します。多层または阶层型,线形,非线形,および一般化线形混合效果モデルを入れ子および/または交差変量效果と共に近似して,縦方向またはパネル分析,反复测定,および成长モデリングを実行します。

回帰学习器アプリで対话的に回帰モデルを近似
ノンパラメトリック回帰
SVM,ランダムフォレスト,ガウス过程,ガウスカーネルなどは予测子と応答の关系を示すモデルを指定せずに,正确に近似をします。

分位点回帰を使用して,外れ値を识别
分散分析(ANOVA)
标本分散をいくつかの异なる発生源に帰し,変动がグループ内で発生したものか,异なるグループ间で発生したものなのかを决定します0.1因子,2因子,多因子,多変量,ノンパラメトリック分散分析(ANOVA),共分散分析(ANOCOVA),および反复测定分散分析(朗诺)を用います。

多因子分散分析(ANOVA)を使用してグループを検定
确率分布
连続分布および离散分布の近似,统计プロットを使用した適合度の評価,40以上の异なる分布の确率密度关数および累积分布关数の计算を行うことができます。

分布钳工アプリを使用して対话的に分布を近似
乱数生成
近似した确率分布または作成した确率分布から,拟似乱数ストリームおよび准乱数ストリームを生成します。

乱数を対话的に生成
仮说検定
吨検定,分布検定(カイ二乘,ジャック - ベラ,リリーフォースおよびコルモゴルフ - スミルノフ),および1标本,対応のある2标本,独立した2标本のノンパラメトリック検定を行います自己相关と乱数度の検定を行い,分布を比较します(2标本コルモゴルフ - スミルノフ)。

片侧吨検定における弃却域
実験计画法(DOE)
カスタマイズした実験计画法(DOE)を定义,分析,および可视化します。データ入力が出力に及ぼす影响の情报を生成できるよう,実用的な计画を作成,テストし,データ入力を操作します。

ボックスベーンケン计画法を适用して,高次の応答曲面を生成
统计的工程管理(SPC)
プロセスの可変性を评価することで,制品やプロセスを监视,改良します。管理図の作成,工程能力の见积もり计算,およびゲージR&R(反复性と再现性)の评価を行います。

管理図を使用して制造工程を监视
信頼性および生存时间分析
コックス比例ハザード回帰を行い,分布の近似を実施することで,打ち切りの有无にかかわらず,故障までの时间データを可视化して分析します。経験的ハザード关数,生存时间关数,累积分布关数,およびカーネル密度推定値を计算します。

「打ち切られた」値の例としての故障データ
高大的配列でビッグデータを分析する
多くの分类,回帰,クラスタリングアルゴリズムで高大的配列とテーブルを利用できます。それらを用いると,元のコードを変更せずに,メモリに收まらないデータセットを使ってモデルを学习させることができます。

并列计算
并列化により统计计算とモデルトレーニングを高速化します。

并行计算工具箱またはMATLAB并行服务器™を使用して计算を高速化
クラウドおよび分散コンピューティング
クラウドインスタンスを使用して,統計および機械学習の計算を高速化します.MATLAB在线™上で全機械学習ワークフローを実行してください。

亚马逊または天青のクラウドインスタンスで计算を実行
コード生成
MATLAB编码器TM值を使用して,分類および回帰アルゴリズム,記述統計量,および確率分布を推定するために,移植可能で読み取り可能なCまたはc++コードを生成します.MATLAB函数ブロックとシステムブロックから機械学習モデルを使用して,高性能なシミュレーションの検証と確認の作業を高速化します。

2つの実装方法:Cコードを生成するか,MATLABコードをコンパイルします。
アプリケーションおよびエンタープライズシステムとの统合
MATLAB编译™を使用して,统计,机械学习モデルをスタンドアロン,MapReduce的,星火™アプリケーション,网络アプリケーション,および微软®高强®アドインとして実装します.MATLAB编译器SDK™を使用して,C / C ++共有ライブラリ,微软.NETアセンブリ,爪哇®クラス,および的Python®パッケージを构筑します。

MATLAB编译を使用して,空気の质の分类モデルを统合

コード生成とモデル更新のワークフロー
自动化された机械学习(AutoML)
分类用の最适なモデルとそれに纽づいたハイパーパラメーターを自动的に选択(fitcauto)
特徴选択
分类问题にカイ二乘テスト(fscchi2),回帰问题に˚Fテスト(fsrftest)を使用して特徴をランク付け
コード生成
数値テーブルを用いて予测(MATLAB编码器が必要)
コード生成
决定木やアンサンブル学习用决定木の固定小数点C / C ++コードを生成(编码器MATLABおよび定点设计が必要)
GPUサポート
GPU上での実行により,更正件,随机,および32个の确率分布关数を高速化(并行计算工具箱が必要)

