 克利夫角:克利夫·莫尔谈数学和计算机
克利夫角:克利夫·莫尔谈数学和计算机 罗兰关于MATLAB的艺术
罗兰关于MATLAB的艺术 用MATLAB进行图像处理
用MATLAB进行图像处理 人在仿真软件万博1manbetx
人在仿真软件万博1manbetx 深度学习
深度学习 开发区域
开发区域 斯图尔特的MATLAB视频
斯图尔特的MATLAB视频 在标题后面
在标题后面 本周文件交换精选
本周文件交换精选 汉斯在物联网
汉斯在物联网 学生休息室
学生休息室 初创企业、加速器和企业家
初创企业、加速器和企业家 MATLAB社区
MATLAB社区 MATLABユーザーコミュニティー
MATLABユーザーコミュニティー基准测试GPU
我最近买了一个GPU,一种图形处理单元。它之所以被称为GPU,是因为这种处理器最初的目的是提高图形处理速度。但是MATLAB用它来加速计算。让我们看看gpuArray对象基准测试。多年来我一直在做计算机基准测试。我喜欢通过改变任务的大小来查看所需的内存数量对性能的影响。在做这些简介的时候,我总能学到一些意想不到的东西。本·托多罗夫(Ben Todoroff)是MathWorks并行处理小组的成员。去年他贡献了# 34080, gpuBench到MATLAB中央文件交换。他已经能够比较几种不同的gpu。我将只考虑一个GPU的性能,但更详细。重要的注意。这只是关于双倍精度。单一精度则是另一回事。
 图片来源:英伟达
图片来源:英伟达
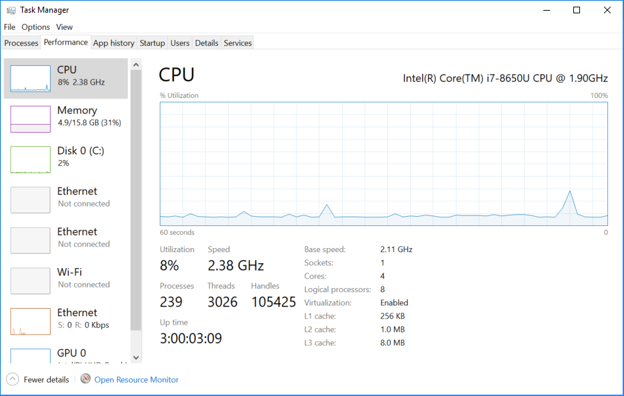 工作频率在1.90 GHz和远高于3 GHz的额定基本速度之间自动变化。它会随着温度的变化而上下波动,天知道还有什么。当我在一个寒冷的早晨第一次给机器通电时,它的运行速度比一天中晚些时候要快。请注意,239个进程和3026个线程的利用率为8%。我知道大多数线程都是空闲的,等待唤醒并干扰我的计时实验。我能做的就是多次运行,取平均值。或者我应该用最短的时间,就像短跑运动员的个人最好时间。
工作频率在1.90 GHz和远高于3 GHz的额定基本速度之间自动变化。它会随着温度的变化而上下波动,天知道还有什么。当我在一个寒冷的早晨第一次给机器通电时,它的运行速度比一天中晚些时候要快。请注意,239个进程和3026个线程的利用率为8%。我知道大多数线程都是空闲的,等待唤醒并干扰我的计时实验。我能做的就是多次运行,取平均值。或者我应该用最短的时间,就像短跑运动员的个人最好时间。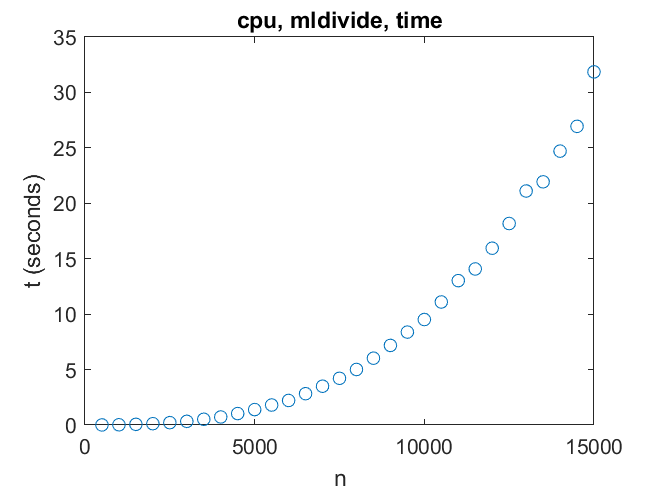 时间越来越多了n ^ 3,如预期。为一个\ b内部循环大致执行2/3 n ^ 3时间,所以十亿次浮点运算
时间越来越多了n ^ 3,如预期。为一个\ b内部循环大致执行2/3 n ^ 3时间,所以十亿次浮点运算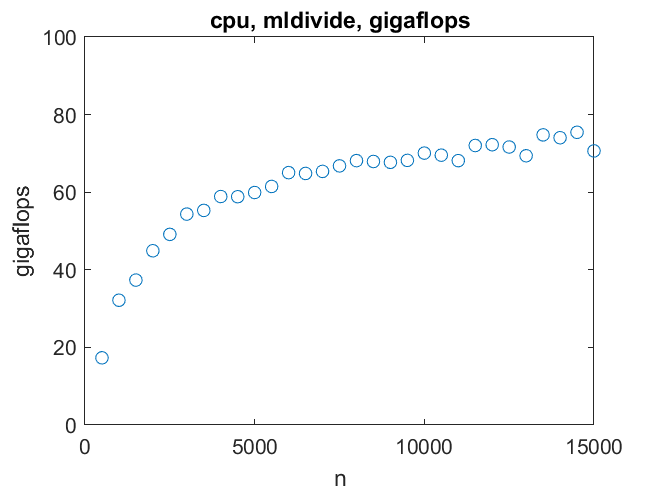 我的结论是x = A \ b我的机器可以达到七千兆次浮点运算n = 10000对于较大的矩阵,速度不会提高很多。
我的结论是x = A \ b我的机器可以达到七千兆次浮点运算n = 10000对于较大的矩阵,速度不会提高很多。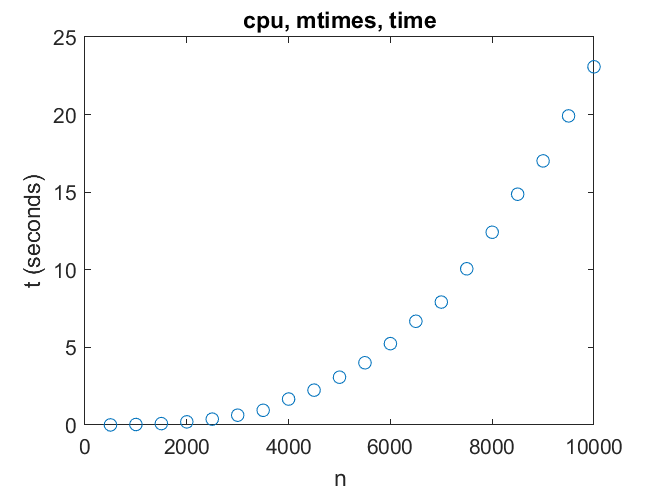
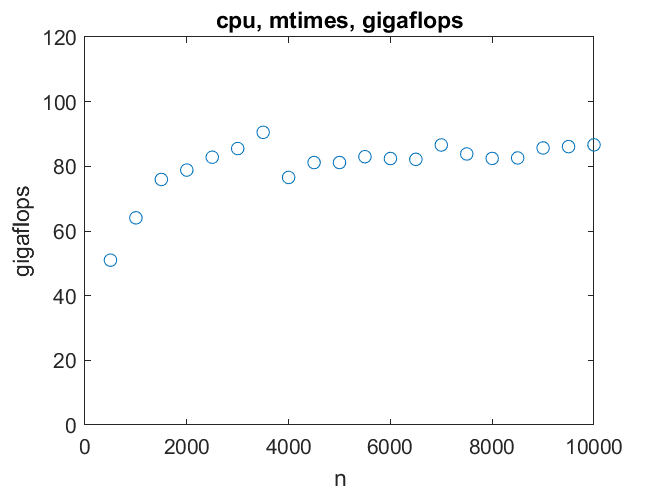 因此,在CPU上的矩阵乘法可以达到80千兆次每秒,哪怕是2000次。
因此,在CPU上的矩阵乘法可以达到80千兆次每秒,哪怕是2000次。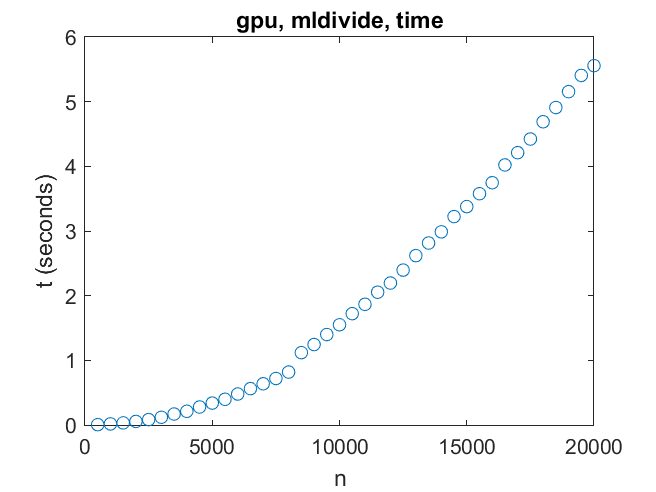
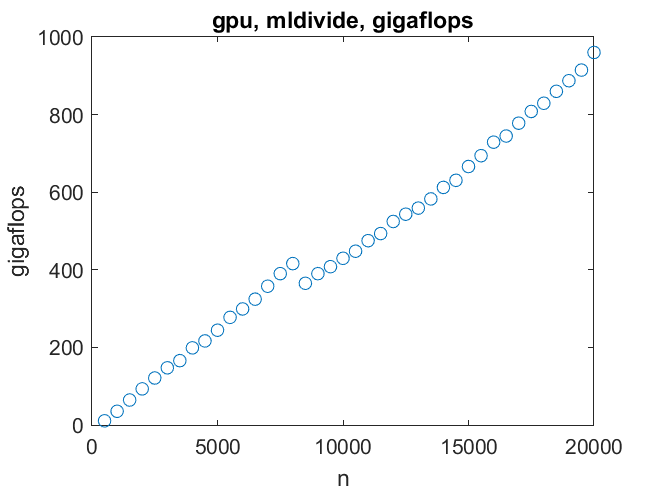 有一个不连续,可能是缓存大小的影响n = 8000.
有一个不连续,可能是缓存大小的影响n = 8000.
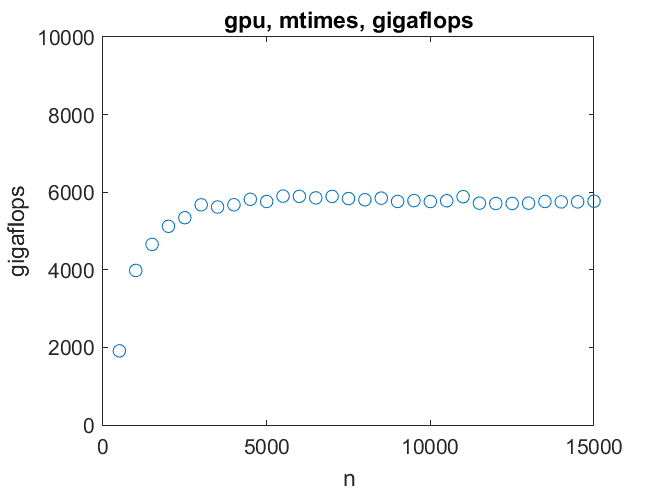 14000阶的一对矩阵可以在不到一秒的时间内相乘。6万亿次浮点运算是最高速度。我们在订单3000达到这个目标。
14000阶的一对矩阵可以在不到一秒的时间内相乘。6万亿次浮点运算是最高速度。我们在订单3000达到这个目标。 对于789阶或更小的线性系统,CPU比GPU更快。GPU可以比CPU快15倍,直到耗尽内存。当然,这没有计算任何数据传输时间。
对于789阶或更小的线性系统,CPU比GPU更快。GPU可以比CPU快15倍,直到耗尽内存。当然,这没有计算任何数据传输时间。 作为矩阵顺序的函数,CPU和GPU都能很快达到它们的最高速度。然后是每秒80亿次,而不是每秒6万亿次。GPU的速度要快75倍。
作为矩阵顺序的函数,CPU和GPU都能很快达到它们的最高速度。然后是每秒80亿次,而不是每秒6万亿次。GPU的速度要快75倍。
内容
我的笔记本电脑
我使用的笔记本电脑是ThinkPad t480,搭载英特尔酷睿i7-8650U处理器,基本工作频率为1.90 GHz。CPU为4核,最大Turbo频率为4.20 GHz。它的主存容量为16GB。我使用的是64位的微软Windows 10操作系统。零售价大约是1500美元。MATLAB使用英特尔数学内核库,它是多线程的。因此,它可以利用所有四个核心。GPU
GPU是运行在1.455 GHz的NVIDIA Titan V。它有12GB内存,640个张量核和5120个CUDA核。它被安置在一个独立的Thunderbolt外围盒中,比笔记本电脑本身大几倍。这个盒子有自己的240W电源和几个风扇。它的零售价为2999美元。 图片来源:英伟达
图片来源:英伟达
基准测试
这是一个令人沮丧的项目。试图测量现代计算机的速度是非常困难的。我可以在我的机器上打开任务管理器性能测量器。我可以切换到飞行模式,这样我就不用再上网了。我可以关闭MATLAB和关闭所有其他窗口,除了性能仪表本身。我可以等到所有短暂性行为消失。但我还是得不到一致的时间。下面是任务管理器的快照。 工作频率在1.90 GHz和远高于3 GHz的额定基本速度之间自动变化。它会随着温度的变化而上下波动,天知道还有什么。当我在一个寒冷的早晨第一次给机器通电时,它的运行速度比一天中晚些时候要快。请注意,239个进程和3026个线程的利用率为8%。我知道大多数线程都是空闲的,等待唤醒并干扰我的计时实验。我能做的就是多次运行,取平均值。或者我应该用最短的时间,就像短跑运动员的个人最好时间。
工作频率在1.90 GHz和远高于3 GHz的额定基本速度之间自动变化。它会随着温度的变化而上下波动,天知道还有什么。当我在一个寒冷的早晨第一次给机器通电时,它的运行速度比一天中晚些时候要快。请注意,239个进程和3026个线程的利用率为8%。我知道大多数线程都是空闲的,等待唤醒并干扰我的计时实验。我能做的就是多次运行,取平均值。或者我应该用最短的时间,就像短跑运动员的个人最好时间。失败
我要测量吉拍.这是10 ^ 9失败了。什么是失败?大多数矩阵计算的内部循环要么是点积,s manbetx 845S = S + x(i)*y(i)或者"daxpy " (x + y)
Y (i) = a*x(i) + Y (i)在这两种情况下,都需要进行一次乘法、一次加法以及少量的索引、加载和存储操作。总的来说,这是两个或两个浮点运算失败.每次通过内部循环都算两次失败。如果我们忽略缓存和内存的影响,矩阵计算所需的时间大致与失败的次数成正比。
CPU, \ b
下面是一个典型的基准测试运行,用于对图标进行计时x = A \ b.t = 0 (30);m = 0 (30);n = 0:500:15000;tspan = 1.0;
While ~get(stop,'value') k = randi(30);nk = n (k);一个= randn (nk、nk);b = randn (nk 1);问= 0;托托= 0;tic while tok < tspan x = A\b;CNT = CNT + 1;托托= toc;End t(k) = t(k) + tok/cnt; m(k) = m(k) + 1; end
t = t / m;吉拍= 2/3 * n。^ 3. / t / 1. e9;这随机改变了矩阵的大小在500 × 500和15000 × 15000之间。如果计算时间小于一秒一个\ b,则重复计算。结果是3000阶及以下的系统需要重复。在两个极端情况下,订单500的系统需要重复100次以上,而订单15000的系统需要超过30秒。如果我运行这个超过一个小时,每个值n遇到几次,平均下来几次。添加了一些注释后
情节(n t ' o ')我得到
 时间越来越多了n ^ 3,如预期。为一个\ b内部循环大致执行2/3 n ^ 3时间,所以十亿次浮点运算
时间越来越多了n ^ 3,如预期。为一个\ b内部循环大致执行2/3 n ^ 3时间,所以十亿次浮点运算giga = 2/3 * n。^ 3. / t / 1. e9
 我的结论是x = A \ b我的机器可以达到七千兆次浮点运算n = 10000对于较大的矩阵,速度不会提高很多。
我的结论是x = A \ b我的机器可以达到七千兆次浮点运算n = 10000对于较大的矩阵,速度不会提高很多。CPU、A * B
乘法的两个n——- - - - - -n矩阵需要2 n ^ 3失败的次数是解一个线性方程组的三倍。
 因此,在CPU上的矩阵乘法可以达到80千兆次每秒,哪怕是2000次。
因此,在CPU上的矩阵乘法可以达到80千兆次每秒,哪怕是2000次。GPU, \ b
现在说说这个项目的主要动机,GPU。首先,解一个线性方程组。这里我们遇到了一个重大障碍——GPU上的内存仅够处理21000阶左右的线性系统。对于这样的系统,性能可以达到1万亿次浮点运算(10^12次浮点运算)。如果有更多的内存用于GPU,那么这个速度还远远达不到。
 有一个不连续,可能是缓存大小的影响n = 8000.
有一个不连续,可能是缓存大小的影响n = 8000.GPU, A * B
很容易将矩阵乘法分解成许多GPU可以处理的小型并行任务。
 14000阶的一对矩阵可以在不到一秒的时间内相乘。6万亿次浮点运算是最高速度。我们在订单3000达到这个目标。
14000阶的一对矩阵可以在不到一秒的时间内相乘。6万亿次浮点运算是最高速度。我们在订单3000达到这个目标。A \ b,比较
GPU和CPU相比如何一个\ b? 对于789阶或更小的线性系统,CPU比GPU更快。GPU可以比CPU快15倍,直到耗尽内存。当然,这没有计算任何数据传输时间。
对于789阶或更小的线性系统,CPU比GPU更快。GPU可以比CPU快15倍,直到耗尽内存。当然,这没有计算任何数据传输时间。A * B,比较
矩阵乘法的情况就大不相同了。 作为矩阵顺序的函数,CPU和GPU都能很快达到它们的最高速度。然后是每秒80亿次,而不是每秒6万亿次。GPU的速度要快75倍。
作为矩阵顺序的函数,CPU和GPU都能很快达到它们的最高速度。然后是每秒80亿次,而不是每秒6万亿次。GPU的速度要快75倍。超级计算机,过去和现在
四十多年前,在LINPACK基准测试在美国,世界上最快的超级计算机是在博尔德的国家大气研究中心(NCAR)新安装的Cray-1。这台机器可以在50毫秒内解决100乘100的线性系统。这相当于每秒14兆次浮点运算(10^6次浮点运算),大约是其最高每秒160兆次浮点运算速度的十分之一。我桌上的机器每秒运算6万亿次,比它快37500倍。无论是crai -1还是NVIDIA的Titan V都可以从更大的内存中获利。另一方面,当今世界上最快的超级计算机是峰会在田纳西州的橡树岭国家实验室(Oak Ridge National Laboratory)。它的最高速度是200petaflops(10^15次浮点运算),比我的笔记本加上GPU快大约37500倍。顶峰有很多记忆。发布与MATLAB®R2018b
|


另请参阅
-

测量GPU性能
博客
-

使用GPU进行图像处理
博客





评论
要留下评论,请点击在这里登录到您的MathWorks帐户或创建一个新帐户。